De oorsprong van Word2Vec
Word2Vec, ontwikkeld door een team onder leiding van Tomas Mikolov bij Google in 2013, is een baanbrekende innovatie in de wereld van natural language processing (NLP). Deze techniek maakte het mogelijk om woorden te converteren naar vectoren van reële getallen, waarbij semantische en syntactische patronen binnen een grote hoeveelheid tekstdata geïdentificeerd konden worden. De publicatie van Mikolov et al., getiteld “Efficient Estimation of Word Representations in Vector Space1” in 2013, was cruciaal voor de popularisering van deze techniek (Mikolov et al., 2013).

De kernformules van Word2Vec
De kern van Word2Vec ligt in het trainen van een neuraal netwerk om woordassociaties te leren van een grote tekstcorpus zonder gelabelde data te vereisen. Dit wordt bereikt via twee architectuurkeuzes: 1. Continuous Bag-of-Words (CBOW) en 2. Skip-gram. CBOW voorspelt een woord op basis van zijn context, terwijl Skip-gram het omgekeerde doet door de context te voorspellen vanuit een woord. Deze methodes gebruiken een ‘soft’ doelfunctie die de cosinus gelijkenis tussen de werkelijke woordvector en de voorspelde woordvector maximaliseert, waardoor woorden met vergelijkbare betekenissen dicht bij elkaar in de vectorruimte komen te liggen.
1. Continuous Bag of Words (CBOW)
In het CBOW-model wordt het doel bereikt om het doelwoord (w_t) te voorspellen uit een venster van omliggende context woorden. De context woorden zijn wt−k,…,wt−1,wt+1,…,wt+k, waarbij (k) de grootte van de trainingscontext aangeeft. De voorspellingsfunctie y^ wordt gegeven door:
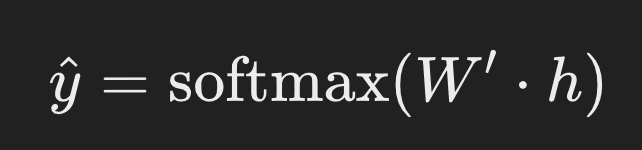 voorspellingsfunctie
voorspellingsfunctie
waarbij (h) de gemiddelde vector van de getransformeerde input context woorden is:
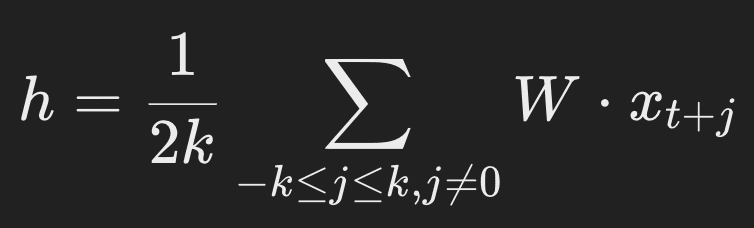 vector getransformeerde inputcontextwoorden
vector getransformeerde inputcontextwoorden
Hierin is (W) de gewichtsmatrix tussen de inputlaag en de verborgen laag, en (W′) de gewichtsmatrix tussen de verborgen laag en de outputlaag. xt+j is de one-hot2 gevectoriseerde vorm van het woord (wt+j).
2. Skip-gram
Het Skip-gram-model werkt omgekeerd aan CBOW. Hier is het doel om de omliggende woorden te voorspellen uit een gegeven doelwoord. Voor een doelwoord (wt), wordt de voorspellingsfunctie (^t+j*) voor elk context woord (wt*+j) gedefinieerd als:
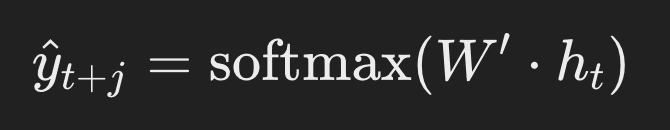 voorspellingsfunctie context woord
voorspellingsfunctie context woord
met (ht = W.x_t), waar (xt) de one-hot gevectoriseerde representatie is van het doelwoord (wt). In beide modellen is softmax3 de activatie functie die is gedefinieerd als: met (ht = W.x_t), waar (xt) de one-hot gevectoriseerde representatie is van het doelwoord (wt). In beide modellen is softmax de activatie functie die is gedefinieerd als:
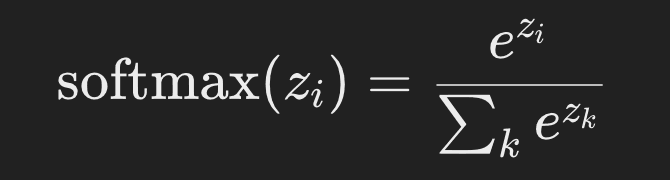 activatie functie
activatie functie
waar (z_) de logits4 zijn (de inputs naar de softmax-functie), die de ongenormaliseerde log-kansen vertegenwoordigen dat een specifiek woord voorkomt in de gegeven context. Deze wiskundige beschrijvingen van CBOW en Skip-gram vormen de basis van hoe Word2Vec werkt, waarbij het leert de woordvectoren te optimaliseren zodat woorden met vergelijkbare betekenissen dichtbij elkaar liggen in de vectorruimte.
Meest voorkomende toepassing van Word2Vec
Een van de meest voorkomende toepassingen van Word2Vec is in de ontwikkeling van aanbevelings systemen en zoekmachines. Door de relaties tussen woorden te begrijpen, kunnen deze systemen relevantere resultaten leveren op basis van de context van zoekopdrachten. Verder wordt Word2Vec gebruikt voor sentiment analyse, waarbij het mogelijk is de algemene sentimenten van teksten te detecteren door de vector representaties van woorden te analyseren.
Toepassing in tech
In de technologiewereld wordt Word2Vec breed ingezet voor het verbeteren van de gebruikerservaring. Zo wordt het bijvoorbeeld gebruikt in chatbots en virtuele assistenten om de natuurlijkheid en relevantie van hun antwoorden te verbeteren. Daarnaast wordt het toegepast in spraakherkenningssoftware, waarbij het helpt om de betekenis van gesproken taal beter te interpreteren. Deze toepassingen zijn essentieel voor het bouwen van systemen die kunnen integreren met gebruikers op een manier die zo menselijk mogelijk aanvoelt.
Elke nieuwe doorbraak op het gebied van NLP zoals Word2Vec drijft de grenzen van wat mogelijk is in technologie en machine learning verder naar voren, en transformeert de manier waarop we met machines communiceren. Dit maakt Word2Vec een van de hoekstenen van moderne AI-toepassingen.
- https://arxiv.org/abs/1301.3781 ↩︎- One-Hot. In de context van machine learning en specifiek natural language processing (NLP), verwijst de term representatie naar de manier waarop data, zoals woorden, zinnen, of zelfs hele documenten, worden omgezet in een vorm die een computer kan verwerken en begrijpen. Dit is essentieel omdat computers niet direct de rijke en complexe structuren van menselijke taal kunnen begrijpen; ze hebben behoefte aan numerieke of binaire formaten.One-hot Encoding: Elk woord in het vocabulaire wordt gerepresenteerd als een vector die voornamelijk uit nullen bestaat, met een enkele 1 op de index die het specifieke woord vertegenwoordigt. Dit is een eenvoudige maar vaak inefficiënte methode, omdat het geen informatie over de relaties tussen woorden behoudt.Dense Word Embeddings: Technieken zoals Word2Vec of GloVe converteren woorden naar dichte vectoren (reële getallen), waarin semantisch of syntactisch vergelijkbare woorden dicht bij elkaar in de vectorruimte liggen. Deze representaties vangen veel meer van de complexiteit van taalgebruik en relaties tussen woorden.Contextual Embeddings: Nieuwere technologieën zoals BERT (Bidirectional Encoder Representations from Transformers) of GPT (Generative Pre-trained Transformer) genereren representaties die niet alleen afhankelijk zijn van het individuele woord zelf, maar ook van de context waarin het woord wordt gebruikt binnen een zin of tekstfragment. Deze technieken leveren dynamische embeddings die veranderen afhankelijk van de gebruikte zin. De keuze van representatie heeft een diepgaande invloed op de prestaties van machine learning-modellen in NLP-taken. Een goede representatie kan ervoor zorgen dat het model subtiele nuances in taal kan herkennen, zoals sarcasme, intentie, of emotionele lading. Dit is cruciaal voor toepassingen zoals sentimentanalyse, machinevertaling, en spraakherkenning. Door woorden, zinnen en teksten te vertalen naar numerieke representaties, kunnen ontwikkelaars en onderzoekers krachtige modellen bouwen die in staat zijn tot geavanceerde taalverwerkingstaken, waardoor de interactie tussen computers en mensen natuurlijker en effectiever wordt. ↩︎- De softmax-functie, veel gebruikt in machine learning en met name in de context van classificatieproblemen en neurale netwerken, is een generalisatie van de logistische functie die een vector van logits, of ruwe (ongenormaliseerde) voorspellingen van een model, omzet in een probabilistische verdeling. De output van de softmax-functie is een vector waarvan de elementen interpreteerbaar zijn als kansen, en die samen optellen tot 1.Normalisatie: Softmax zorgt ervoor dat de som van de outputkansen gelijk is aan 1, waardoor de output kan worden geïnterpreteerd als een probabilistische verdeling.Niet-lineair: Hoewel de exponentiële functie zelf niet-lineair is, draagt softmax bij aan de niet-lineariteit van de besluitvorming in neurale netwerken, wat essentieel is voor het leren van complexe patronen.Gevoelig voor extremen: Vanwege de exponentiële aard van de functie worden verschillen tussen de componenten van de inputvector versterkt. Dit betekent dat zelfs kleine verschillen in de logits kunnen leiden tot grote verschillen in de resultaten van de softmax-uitkomsten. Softmax wordt typisch gebruikt in de laatste laag van een neurale netwerkclassificatie om de logits te vertalen naar kansen. Het is bijzonder nuttig in scenario’s waarin meerdere klassen worden overwogen (multiclass classificatie), zoals het herkennen van handgeschreven cijfers, spraakherkenning, of het categoriseren van tekst in onderwerpen. Deze functie is cruciaal voor het interpreteren van de outputs van het netwerk als waarschijnlijkheden, wat een intuïtief begrip mogelijk maakt van welke klasse het meest waarschijnlijk is gegeven de input. ↩︎- Logits zijn een term uit de context van machine learning, met name in de statistische modellering en neurale netwerken. Ze vertegenwoordigen de ongenormaliseerde log-kansen die worden geproduceerd door een neuraal netwerk voordat ze worden omgezet in kansen via een softmax-activatiefunctie. In het geval van Word2Vec en andere neurale netwerkmodellen voor NLP, worden logits vaak gebruikt om de output te berekenen die wordt geproduceerd door de laatste laag van het netwerk voordat deze wordt doorgegeven aan de softmax-functie. Logits zijn de directe outputs van deze laatste laag, en ze worden vervolgens genormaliseerd door de softmax-functie om de uiteindelijke kansverdeling te verkrijgen over de mogelijke uitvoerwaarden. In het geval van Word2Vec worden logits gebruikt om de relatieve waarschijnlijkheid van elk woord in het vocabulaire te berekenen, gegeven de context of het doelwoord. Deze logits worden vervolgens omgezet in kansen door middel van softmax, waardoor de resulterende kansverdeling kan worden gebruikt om de woordvector te optimaliseren via achterwaartse propagatie en gradient descent. ↩︎
De oorsprong van Word2Vec
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.