Between automation and accountability a analysis of AI coding pitfalls, design failures, and operational guardrails.
by Djimit
Executive summary
Generative Artificial Intelligence (AI) is rapidly being integrated into software development workflows, promising unprecedented gains in productivity and efficiency. While these tools excel at accelerating well defined, repetitive coding tasks, their application in more complex, high stakes domains introduces a new spectrum of risks that technology leaders must strategically manage. This report provides a critical analysis of the boundaries of AI assisted coding, identifying where its use is inappropriate and outlining the operational, architectural, and governance guardrails necessary for its safe and effective deployment.
The core thesis of this analysis is that generative AI, in its current state, should be treated as a powerful but fallible junior developer. It is a potent accelerant for boilerplate generation, unit testing, and code translation, but it presents unacceptable risks in domains that demand high level abstract reasoning, deep contextual understanding, and unwavering accountability. These high risk domains include system architecture, security critical code, legal and compliance sensitive logic, and the design of genuinely innovative algorithms.

This report maps a comprehensive typology of ten programming domains where AI is demonstrably unsuitable, detailing the failure patterns and supporting evidence for each. The analysis reveals that AI’s limitations stem from its foundational nature: it is a probabilistic patternmatcher, not a reasoning engine. It learns from vast datasets of public code, inheriting their flaws and biases, and lacks true comprehension of legal intent, business context, or long term architectural consequences.
To quantify these dangers, this report introduces a multi dimensional risk matrix that assesses each domain against five critical factors: Trustworthiness, Security Risk, Legal Exposure, Innovation Ceiling, and Ownership Clarity. This framework provides leaders with a tool to identify “no go zones” where the potential cost of failure, a catastrophic security breach, a multi million dollar lawsuit for IP infringement, or the erosion of a core competitive advantage far outweighs any productivity gains.
However, recognizing limitations is only half the solution. This report synthesizes effective counter strategies, translating the intuitive principles of “vibe coding” into actionable engineering discipline. It presents an operational model of “AI as a Junior Developer,” emphasizing the need for structured oversight, explicit architectural control, and persistent “memory” artifacts to guide the AI and mitigate its cognitive blind spots. This model shifts the developer’s role from a manual typist to a strategic reviewer and system architect, managing the cognitive load of AI collaboration to ensure quality and accountability.
Finally, the report addresses the critical legal and governance implications of AI generated code, focusing on the unsettled landscape of intellectual property, copyright ownership, and license contamination. It concludes by presenting a practical decision framework, a checklist and decision tree for engineering leaders to determine, on a task by task basis, whether and how to deploy AI assistance safely. By establishing clear boundaries, implementing robust governance, and fostering a new discipline of human AI collaboration, organizations can harness the power of automation while upholding the standards of accountability required to build secure, reliable, and innovative software.
Task boundaries of AI Coding a typology of unsuitable domains
While generative AI offers significant productivity boosts for discrete coding tasks, its application is not universal. Certain domains in software development demand levels of reasoning, context, and accountability that current AI systems cannot provide. Delegating tasks in these areas to AI introduces significant risk of technical debt, security vulnerabilities, legal liability, and strategic failure. This section defines ten such domains, explaining the core problems, common failure patterns, and the evidence supporting the need for human led execution.
System Design & Software Architecture
Core Problem: High level system design is an exercise in abstract reasoning and trade off analysis. It requires a deep understanding of non-functional requirements (e.g., scalability, reliability, maintainability), long term business goals, and the subtle interplay between architectural components. AI models, which operate on statistical patterns found in training data, lack the genuine comprehension needed for this task.1 They cannot replicate the critical thinking, stakeholder negotiation, or judgment calls that are the core activities of a software architect.2
Failure Patterns: AI generated architectural suggestions are often opaque, making them difficult to justify, debug, or evolve. This “black box” nature can lead to the adoption of popular but inappropriate patterns, such as proposing a complex microservices architecture for a simple application because it is a common pattern in its training data.1 This phenomenon can be described as “architectural hallucination,” where the AI generates a plausible sounding but contextually flawed design. This is not a reasoned decision but a probabilistic guess based on keyword association, potentially leading an organization down a path of significant technical debt and operational complexity.3 Furthermore, AI systems struggle with ambiguity and cannot engage in the crucial dialogue with stakeholders required to clarify requirements and constraints.1
Supporting Evidence: The International Software Architecture Qualification Board (iSAQB) outlines core architectural activities such as designing structures, evaluating trade offs, and communicating architectures all of which hinge on critical thinking that AI currently lacks. While AI can support an architect by sifting through requirements documents, it cannot perform the core design and evaluation work.2
Security Critical Code
Core Problem: AI coding assistants are predominantly trained on vast public code repositories like GitHub. These repositories are unavoidably saturated with code containing security vulnerabilities. The AI models learn these insecure patterns and faithfully reproduce them in their generated output, effectively laundering vulnerabilities from the open internet into an organization’s proprietary codebase.4
Failure Patterns: AI generated code frequently exhibits classic vulnerabilities, including SQL injection, cross site scripting (XSS), buffer overflows, and the use of hard coded secrets.4 Beyond replicating known flaws, AI can introduce novel risks. Malicious actors can use AI to develop sophisticated malware that evades traditional detection or even engage in “data poisoning” attacks on the training sets of AI models to intentionally introduce subtle backdoors.6 The resulting code may be functionally correct but contain logical flaws that are nearly impossible for standard static analysis tools to detect.
Supporting Evidence: A 2023 study found that up to 32% of code snippets generated by GitHub Copilot contained potential security vulnerabilities.4 More recent analysis has been even more stark, with one report stating that tools like Cursor “consistently fail to generate secure code” and conservatively estimating that such tools could be generating 100,000 new security flaws daily.8 This flood of potentially insecure code renders traditional security evaluation methods increasingly obsolete.9 Therefore, any AI generated code intended for authentication, authorization, cryptography, data validation, or input sanitization must be treated as inherently untrusted and subjected to rigorous, manual expert review.
Compliance & Legal Tasks
Core Problem: Compliance with legal and regulatory frameworks like GDPR, HIPAA, or the Sarbanes Oxley Act requires an understanding of legal intent, nuance, and ethical principles not just pattern matching of text. AI systems lack this understanding and cannot be held accountable for legal interpretation.10
Failure Patterns: The most well known failure pattern is “hallucination,” where AI tools fabricate information. In the legal profession, this has led to lawyers being sanctioned by courts for citing non existent legal cases in briefs generated by ChatGPT.12 In coding, this translates to generating logic that fails to implement proper data anonymization, secure user consent mechanisms, or respect data sovereignty rules.14 A more subtle failure involves the creation of “derived data.” An AI system might combine multiple anonymized data points to inadvertently re identify an individual, creating a severe privacy breach that traditional compliance checks, focused on explicit personal data, would miss.15
Supporting Evidence: Real world examples of compliance failures are numerous. A class action lawsuit was filed against Paramount over its AI recommendation engine allegedly sharing subscriber data without proper consent.15 A major bank’s AI driven credit approval system was found to be biased against women.15 In healthcare, AI medical coding systems have struggled with HIPAA compliance and have shown bias against minority patients due to skewed training data.14 With regulations like the EU AI Act threatening fines of up to €35 million or 7% of global annual revenue, the financial stakes of such failures are immense.16
Innovative Algorithm Design
Core Problem: Generative AI is fundamentally derivative. It excels at interpolating within its training data recombining known patterns in novel ways but it cannot extrapolate to create concepts that lie outside that data. True innovation often requires a paradigm shift, a flash of intuition, or abstract reasoning that is, for now, a uniquely human capability.17
Failure Patterns: An AI can be prompted to generate a perfect implementation of a known algorithm like quicksort, but it cannot invent a fundamentally new sorting paradigm. It lacks the “common sense” and “out of the box” thinking to solve problems that have no precedent in its training set.1 Over reliance on AI for problem solving can lead to an “innovation ceiling,” where developers become anchored to the first plausible solution suggested by the AI, stifling exploration of more creative or optimal paths.
Supporting Evidence: While AI has produced works that appear creative, such as artistic style transfers, it has yet to invent a new artistic movement like Cubism or a new scientific theory.20 Its creativity is a mechanistic process of statistical recombination, devoid of the subjective experience and intentionality that drives human breakthroughs.20 A study from Purdue University found that developers using AI assistants explored 33% fewer alternative solutions, providing empirical evidence for the risk of “cognitive fixation”.22 AI should be viewed as an exceptional research assistant for summarizing existing knowledge, but the synthesis of that knowledge into a truly new algorithm must remain a human led endeavor.
High Stakes Performance Optimization
Core Problem: While AI can suggest code optimizations, these are often superficial and lack deep, system wide context. Effective performance tuning requires a holistic understanding of hardware architecture, memory management, I/O constraints, and the specific execution profile of a complex application knowledge that a generalized AI model does not possess.19
Failure Patterns: AI may suggest a “local optimization” that improves a single function but inadvertently creates a bottleneck elsewhere in the system. It may also fail to account for the computational overhead of its own suggestions, particularly in real time systems where AI driven optimization can introduce latency that negates any performance gains.23 This leads to a “local maximum” trap: the AI optimizes a piece of code, whereas a human expert, understanding the full context, might refactor the entire system for a far greater improvement.
Supporting Evidence: Research highlights that balancing the computational overhead of AI models with the need for low latency performance is a significant challenge, especially in demanding fields like high frequency trading or gaming servers.23 The problem is particularly acute for small and medium sized companies that may lack the specialized knowledge or resources to properly implement and validate AI driven optimization techniques.23 AI’s role is better suited to
identifying potential issues, such as forecasting CPU spikes or memory leaks, rather than autonomously implementing the solutions.23
Complex, Domain Specific Business Logic
Core Problem: Every organization’s core business logic is its unique fingerprint, a complex tapestry of explicit rules, historical context, and unstated assumptions. This “tacit knowledge” is not present in public datasets, and therefore an AI cannot learn or replicate it.1
Failure Patterns: When prompted to write code for a business process, an AI will generate generic, “textbook” logic that is functionally correct but contextually wrong. It will miss critical edge cases and nuances specific to the business. For example, it cannot know about a legacy discount that must be applied to a specific long term customer, a rule that exists only in the collective memory of the sales team. Because AI struggles with ambiguity, it cannot engage in the necessary dialogue with business stakeholders to elicit and clarify these unwritten rules.1
Supporting Evidence: AI tools may overlook specific business goals that require strategic trade offs, or they may prioritize features that do not align with the product’s vision.1 While machine learning models
can be used to replace complex logic, this is a major engineering effort involving extensive data collection, labeling, and training it is not a simple code generation task that can be delegated to a general purpose AI assistant.24 Core business logic representing a company’s competitive advantage must be meticulously handcrafted by developers in close collaboration with domain experts.
Team Collaboration and Code Readability
Core Problem: Unchecked AI use can degrade code from a clear communication medium into an opaque artifact, eroding the shared understanding that is vital for team cohesion and long term maintainability.
Failure Patterns: The speed of AI generation can lead to a “too fast to review” culture, where pull requests are rubber stamped without deep consideration. These PRs often lack the “connective tissue” the design notes, refactoring rationale, and comments that convey human intent.25 This creates a knowledge gap, particularly for junior developers, who may become reliant on AI to produce code they cannot explain, debug, or build upon collaboratively.26 The process of code review shifts from a human to human dialogue about intent (“What were you thinking?”) to a frustrating exercise in reverse engineering a machine’s probabilistic output (“What was the AI thinking?”).
Supporting Evidence: The negative impact on collaboration is subtle but significant enough that specialized tools are emerging to monitor it. Platforms like Appfire’s Flow are designed to detect signals of degrading collaboration, such as a drop in review depth, shallow PRs, or uneven workload distribution, which are invisible to standard project management software.25 This indicates a recognized need to manage the corrosive effect AI can have on the social fabric of a development team.
Education and Foundational Learning
Core Problem: In an educational context, over reliance on AI coding assistants can prevent students from developing the fundamental skills of problem solving, debugging, and critical thinking. It allows them to bypass the productive struggle that is essential for deep learning.4
Failure Patterns: Students may use AI as an “answer key,” generating functional code for assignments without understanding the underlying computer science principles. This fosters a dangerous dependency, creating a generation of developers who are proficient at prompting but inept at programming.28 The most critical skill they fail to develop is debugging. Debugging is a rigorous process of forming and testing hypotheses; when a student asks an AI to “fix my code,” they are outsourcing this entire mental exercise, leading to a “debugging deficit.”
Supporting Evidence: Both educators and senior engineers have raised alarms about this trend, noting that junior developers who rely heavily on AI often cannot explain how their code works and are helpless when it fails in unexpected ways.26 Learning to code requires trial and error; using AI to circumvent this process stunts the growth of the very skills that define a competent engineer.27
Proprietary and Legacy System Migrations
Core Problem: Migrating proprietary or legacy systems is a high risk endeavor that requires deep expertise in often poorly documented, outdated, or unique technologies. AI tools, trained on modern, open source codebases, are ill equipped to handle this complexity and introduce significant security and IP risks.29
Failure Patterns: AI agents often struggle with the unique configurations, customizations, and undocumented APIs of legacy systems, leading to migration failures or unexpected behavior.30 They require extensive access to production systems, creating major security vulnerabilities. Furthermore, legacy systems often contain inconsistent or corrupt data; an AI analyzing this data will not only replicate the “garbage in, garbage out” problem but may amplify it by baking bad data practices into the architecture of the new system.
Supporting Evidence: The challenges of legacy migration include a shortage of skilled professionals and the high complexity of monolithic architectures.29 AI agents face technical hurdles with compatibility, data quality, and handling edge cases.30 Moreover, there are significant governance gaps, including data sovereignty issues in cross border migrations and intellectual property concerns, as an AI might inadvertently incorporate proprietary logic into its outputs in a way that violates IP boundaries.30
Copyright and Ownership Sensitive Code
Core Problem: The legal framework for AI generated intellectual property is dangerously unsettled. The prevailing stance in the United States is that a work must have a human author to be copyrightable. Using AI to generate core proprietary code could render that code legally unprotected, creating an existential risk for technology companies.31
Failure Patterns: A company might use an AI assistant to develop a key feature, only to discover later that it cannot enforce its copyright against a competitor who copies the code because it lacks sufficient human authorship. This creates an “unenforceable asset” a valuable piece of software that has no legal protection. Another critical failure pattern is “license contamination,” where an AI injects snippets of code from its training data that are governed by a restrictive open source license (e.g., the GNU General Public License). If this code is incorporated into a proprietary product, it could legally obligate the company to release its own source code to the public.32
Supporting Evidence: The U.S. Copyright Office has repeatedly denied copyright to works created without sufficient human intervention, most notably in the Thaler v. Perlmutter case and its registration decision for the graphic novel Zarya of the Dawn.33 The scale of the problem is vast: some data suggests over 40% of new code on GitHub involves AI assistance, and a study by the Software Freedom Conservancy found that approximately 35% of AI generated code samples contained potential licensing irregularities.34 This demonstrates a widespread and urgent risk to corporate IP portfolios.
Risk Matrix Analysis
To move from a qualitative understanding of AI coding risks to a quantitative framework for governance, this section introduces a risk matrix. This tool assesses the ten unsuitable programming domains identified in the previous section across five critical risk dimensions. By scoring each domain, technology leaders can gain an at a glance understanding of the risk profiles associated with AI use, enabling them to establish clear boundaries, prioritize oversight, and make informed decisions about where automation is safe versus where it is reckless.
The Risk Dimensions Matrix
The matrix below scores each task category on a scale of 1 to 5, where 1 represents low risk and 5 represents high risk. The five dimensions are:
-
Trustworthiness: The risk of the AI producing incorrect, biased, non functional, or subtly flawed output. (Score 1: Highly reliable; Score 5: Highly unreliable, frequent hallucinations).
-
Security Risk: The risk of introducing exploitable vulnerabilities, security flaws, or backdoors. (Score 1: Negligible risk; Score 5: High probability of introducing critical vulnerabilities).
-
Legal Exposure: The risk of violating laws, regulations (e.g., GDPR, HIPAA), or intellectual property rights (e.g., copyright, license contamination). (Score 1: Minimal legal risk; Score 5: High risk of litigation, fines, or IP loss).
-
Innovation Ceiling: The risk of stifling human creativity, preventing novel solutions, and leading to suboptimal, derivative outcomes. (Score 1: Enhances innovation; Score 5: Severely limits innovation).
-
Ownership Clarity: The risk of ambiguity over who legally owns the copyright to the generated code. (Score 1: Ownership is clear; Score 5: Ownership is highly ambiguous or unenforceable).
Task CategoryTrustworthinessSecurity RiskLegal ExposureInnovation CeilingOwnership ClarityTotal Risk Score****1. System Design & Architecture5325217****2. Security Critical Code5543320****3. Compliance & Legal Tasks5454422****4. Innovative Algorithm Design4235418****5. High Stakes Performance Optimization4314214****6. Domain Specific Business Logic5334318****7. Team Collaboration & Readability4213111****8. Education & Foundational Learning4325115****9. Proprietary & Legacy Migrations5443420****10. Copyright Sensitive Code3352518
Analysis of Risk Thresholds
The matrix reveals that risk is not a monolith but a multi dimensional spectrum. A task’s suitability for AI assistance cannot be judged on productivity potential alone; it must be weighed against its specific risk profile. Based on this analysis, clear governance thresholds can be established.
Unacceptable Risk: The “No Go Zones”
Any task scoring a 4 or 5 in the Security Risk or Legal Exposure dimensions should be considered a “no go zone” for autonomous AI code generation. The potential cost of failure in these areas a catastrophic data breach, regulatory fines measured in the tens of millions of euros 16, or the complete loss of proprietary intellectual property is too severe to justify the risk.
High Risk Quadrant: This includes Compliance & Legal Tasks, Security Critical Code, and Proprietary & Legacy Migrations. These domains consistently score high in the most critical risk areas. For these tasks, AI’s role must be strictly limited to supervised analysis or assistance (e.g., summarizing compliance documents for a human expert, identifying potential vulnerabilities for human review). The final implementation must be human led and human authored. Copyright Sensitive Code also falls here due to its extreme scores in Legal Exposure and Ownership Clarity, making autonomous generation a direct threat to a company’s core assets.32
Contextual Risk: The “Human in the Loop” Mandate Tasks in this category are not necessarily catastrophic risks but pose a high probability of producing suboptimal, untrustworthy, or strategically damaging outcomes if left to AI alone. They score highly on Trustworthiness and Innovation Ceiling.
Moderate/Contextual Risk Quadrant: This includes System Design, Innovative Algorithm Design, and Domain Specific Business Logic. The primary danger here is not a security breach but the creation of brittle architectures, the stifling of true innovation, and the implementation of flawed business rules.1 The appropriate model for these tasks is “human in the loop,” where the AI acts as a brainstorming partner, a research assistant, or a generator of initial drafts, but the final strategic decisions, creative synthesis, and implementation are driven by an experienced human developer or architect.
Operational Risk: The Process and People Challenge
Some tasks present lower direct security or legal risks but threaten the health and effectiveness of the engineering organization itself.
Operational Risk Quadrant: Education & Foundational Learning and Team Collaboration & Readability fall into this category. The risk here is the erosion of skills and the breakdown of communication.25 While a single instance of an AI generated function might not be dangerous, a culture of over reliance can lead to a long term decline in team capability and code quality. Governance here should focus on process, training, and setting clear expectations for code review and developer accountability.
This multi dimensional view demonstrates that a one size fits all AI policy is insufficient. A nuanced governance strategy is required, one that matches the level of human oversight to the specific risk profile of the task at hand. For some tasks, AI is a low risk accelerant; for others, it is a high risk liability. Knowing the difference is the foundation of responsible AI adoption.
Vibe coding a human centric counterbalance to AI automation
As organizations grapple with the limitations of generative AI, a parallel movement among developers offers a human centric framework for effective collaboration. Known as “vibe coding,” this philosophy, prioritizes intuition, rapid iteration, and a deep, continuous feedback loop over the rigid, pre specified instructions typical of automated or “agentic” engineering.35 By translating these principles into actionable practices, development teams can create a powerful counterbalance to AI’s failure modes, using the tool to augment human creativity rather than attempting to replace it.
This section maps 10 principles of vibe coding to common AI pitfalls and demonstrates how they can be implemented through disciplined prompting, architectural control, and modern tooling.
1. Start with Vibes, Not Specs
-
Principle: Let intuition guide the initial sketch. Don’t over plan; follow the creative impulse.35
-
AI Failure Countered: AI’s inability to handle ambiguity and its tendency to generate generic solutions based on rigid prompts.1
-
Actionable Practice: Instead of writing a detailed specification for the AI, start with a high level, intent based prompt. For example, rather than a 20 line prompt detailing a form’s fields and validation, a vibe centric prompt might be: “Create a simple, elegant login page with email/password and Google login”.36 The developer then interacts with the initial output, refining it through conversation. This “improv” approach uses the AI as a rapid prototyping tool, allowing the developer’s intuition to guide the process.
2. Research First, Always and Continuously
-
Principle: Before writing a line of code, map the terrain. Research docs, scan examples, and identify constraints.35
-
AI Failure Countered: AI’s lack of deep domain context and its potential to hallucinate or use outdated information.17
-
Actionable Practice: Use AI as a research accelerator. Before prompting for code, use the AI to summarize key documentation, find relevant code examples from trusted sources, or explain a new API. Tools like Cursor or Windsurf can be fed URLs or documentation files to provide context.37 A prompt might be: “Based on the official Stripe API documentation at this URL, outline the key steps to create a subscription.” This grounds the AI’s subsequent code generation in verified, up to date information.
3. Define a Boomerang Loop (Build, Test, Fail, Refactor)
-
Principle: Structure the workflow for constant return and iteration, not linear progression.35
-
AI Failure Countered: The “black box” nature of AI, which can produce subtly incorrect or non functional code that appears correct on the surface.38
-
Actionable Practice: Treat every piece of AI generated code as a hypothesis to be immediately tested. The workflow becomes:
-
Prompt: Ask the AI to generate a function.
-
Test: Immediately write a unit test that exercises the generated code, including edge cases.
-
Validate: Run the test. If it fails, the AI’s output is incorrect.
-
Refine: Use the failure as a new, more specific prompt for the AI (“The previous code failed this test case. Fix it by handling null inputs.”) or fix it manually. This tight feedback loop prevents flawed AI code from propagating through the system.
4. Test Before Fix
-
Principle: Write a test that fails first to confirm the problem and set a clear target.35
-
AI Failure Countered: AI’s tendency to “fix” bugs with solutions that introduce new, more subtle bugs.
-
Actionable Practice: This is a direct application of Test Driven Development (TDD) to AI collaboration. When a bug is found in AI generated code, the first step is not to ask the AI to “fix it.” The first step is to write a failing test that precisely reproduces the bug. This test then becomes part of the prompt. // This test fails with the current implementation. // Refactor the code to make this test pass without breaking existing tests. This provides the AI with an unambiguous, verifiable goal, dramatically improving the quality of its proposed fix.
5. Code in Streams, Think in Layers
-
Principle: Work continuously but maintain a structured mental model of the system (e.g., discovery, build, validate, refine).35
-
AI Failure Countered: AI’s lack of architectural awareness; it generates code, not systems.2
6. Refactor Only After Success
-
Principle: Get it working first, then improve it. Don’t polish a failure.35
-
AI Failure Countered: The temptation to get lost in optimizing or “improving” AI generated code that is fundamentally incorrect.
-
Actionable Practice: This principle reinforces the “Boomerang Loop.” The primary goal is to get the AI generated code to pass all relevant tests. Only after achieving a “green” state should the developer prompt for improvements. // This function is correct but inefficient. // Refactor it to reduce its time complexity while ensuring all tests still pass. This prevents wasted effort and keeps the focus on verifiable correctness.
7. Build Small, Layer Later
-
Principle: Start with a minimal component (one function, one file). Add scaffolding only when pain demands it.35
-
AI Failure Countered: AI’s tendency to generate overly complex or boilerplate heavy code when given a broad prompt.
-
Actionable Practice: Use highly specific, small scope prompts. Instead of “Build me a user management system,” start with “Write a single function that validates an email address using a regex.” Once that function is generated and tested, move to the next small piece. This granular approach keeps the developer in full control and ensures each component is verified before being integrated into a larger whole. The AI builds the bricks; the human builds the house.
8. Automate Friction
-
Principle: Anything done twice gets scripted or delegated to agents to preserve flow state.35
-
AI Failure Countered: The cognitive overhead of repetitive tasks that pull a developer out of deep work.
-
Actionable Practice: Identify repetitive prompting patterns and turn them into custom commands or snippets. For example, if a developer frequently asks the AI to generate test files, they could create a custom command in their IDE or a tool like Claude Code that automates this prompt.37 This allows the developer to delegate the “friction” of boilerplate generation to the AI while they focus on the more creative aspects of the problem.
9. Ship Disposable Deployments
-
Principle: Treat each push as temporary. Deploy often, rollback easily, and maintain no attachment.35
-
AI Failure Countered: The risk of AI introducing subtle, hard to detect production bugs.4
-
Actionable Practice: This principle aligns perfectly with modern CI/CD and DevOps practices. When working with AI assisted code, robust, automated deployment pipelines with easy rollback capabilities are not just a best practice; they are a critical safety mechanism. By deploying small, AI assisted changes frequently to a staging environment, teams can quickly detect and revert any negative impact before it affects users.
10. Optimize for Feel
-
Principle: The ultimate benchmark is not just performance but the “vibe” of the code its elegance, responsiveness, and clarity.35
-
AI Failure Countered: AI’s tendency to produce code that is functional but clunky, unreadable, or difficult to maintain.
-
Actionable Practice: The human developer acts as the ultimate arbiter of code quality. After the AI has generated a functional and tested piece of code, the developer performs a final review, asking not just “Does it work?” but “Does it feel right?”. This involves manual refactoring for clarity, adding insightful comments that the AI could not generate, and ensuring the code aligns with the team’s established style and conventions. The developer is the guardian of the codebase’s “vibe,” a quality that AI cannot yet measure or replicate.
By adopting these vibe coding principles, teams can transform their relationship with AI from one of blind delegation to one of synergistic collaboration, leveraging the machine’s speed while retaining the human’s judgment, creativity, and accountability.
Trust, memory and prompt design managing AI as a Junior developer
The integration of generative AI into development workflows introduces a significant cognitive load on developers. The tool’s propensity for hallucination, its lack of persistent context, and the ambiguity of its outputs require developers to shift their mental model from simply writing code to constantly supervising, validating, and correcting a probabilistic assistant. Recent studies challenge the narrative of universal productivity gains, revealing that for experienced developers working in familiar codebases, AI assistants can actually slow them down by interrupting their mental flow.22
This “productivity paradox” arises because an expert developer must pause their well honed internal process to evaluate an external suggestion, a cognitive detour that is often more demanding than recalling the solution directly.22 To mitigate this friction and unlock the true potential of AI assistance, organizations must adopt an operational model that treats the AI not as an oracle, but as a talented but inexperienced junior developer. This model requires providing the AI with structure, memory, and explicit guidance the same support a human junior engineer would need to be successful.
The AI as a Junior Developer Analogy
Thinking of an AI coding assistant as a junior developer provides a powerful mental framework for managing its strengths and weaknesses:
-
Eager and Fast, but Lacks Experience: Like a junior dev, the AI can produce large amounts of code quickly. It knows syntax and common patterns but lacks deep experience, domain context, and an understanding of “why” things are done a certain way.26 It can write boilerplate code efficiently but struggles with complex debugging or system design.
-
Needs Clear, Unambiguous Instructions: Vague instructions given to a junior developer result in flawed or incomplete work. The same is true for AI. A prompt like “fix the bug” is ineffective. A prompt like “The calculate_tax function throws a NullPointerException when the user_profile object is missing a state field. Add a null check and return a default tax rate of 0 in this case” provides the clear, explicit instructions the AI needs to succeed.
-
Requires Constant Supervision and Code Review: No competent manager would ship a junior developer’s code to production without a thorough review by a senior engineer. The same standard must apply to AI generated code. Developers must read every line of AI output, not just to check for functional correctness but for security flaws, performance issues, and adherence to coding standards.40
-
Lacks Context and Forgets Past Conversations: A junior developer might forget a key architectural constraint discussed last week. An AI assistant forgets everything the moment the context window resets. It has no persistent memory of past decisions, feedback, or project specific rules.
Engineering Trust Through Structure and Memory
To make the “AI junior developer” a productive team member, senior developers must provide the scaffolding it lacks. This is an exercise in “trust engineering” building a workflow that makes the AI’s output more reliable and easier to validate.
- Providing Explicit Architectural Control
An AI left to its own devices will mix concerns and violate architectural boundaries because it doesn’t understand them. The senior developer must enforce this structure.
-
Layered Prompting: As described in the “Vibe Coding” section, prompts should be scoped to a specific file or architectural layer. This prevents the AI from, for example, putting database queries inside a UI component. The human acts as the architect, directing the AI to work within a pre defined structure.
-
File Level Context: Modern AI native IDEs like Cursor or tools like Windsurf allow the developer to explicitly select which files the AI should use as context for its response. By providing the AI with the relevant interface definition, data model, and utility service files, the developer gives it the local context it needs to generate compliant and consistent code.
- Creating a Persistent Memory
The most significant limitation of current LLMs is their lack of long term memory. This can be mitigated by creating external “memory” artifacts that are fed into the AI’s context window for every relevant task.
-
The ai learnings.md File: This is a simple but powerful technique. A team can maintain a markdown file in their repository that documents key project constraints, architectural decisions, and common mistakes the AI has made in the past.
-
Example Entry: “AI LEARNING: When generating database migration scripts, ALWAYS use the BIGINT data type for primary keys, not INT. The AI previously generated INT, which caused an overflow issue in the users table.”
-
The claude.md or Project Context File: Some tools can automatically generate a project summary file (e.g., claude.md) by scanning the entire codebase. This file outlines the technology stack, core components, coding standards, and data flow.37 Developers can then augment this file with manually curated notes and rules.
-
Integrating Memory into Prompts: Before starting a complex task, the developer instructs the AI to first read and adhere to the rules in these memory files. // Before generating any code, review the rules in rules.mdand the project context inclaude.md. // Your task is to… This provides the persistent guidance the AI lacks, reducing the rate of repeated errors and the cognitive load on the human reviewer.
- Shifting the Developer’s Role and Cognitive Load
This operational model fundamentally changes the developer’s role. It reduces the cognitive load of typing and recalling syntax but increases the cognitive load of reviewing, planning, and system level thinking. Neuroscientific evidence from fMRI studies confirms this shift, showing that AI assistance reduces brain activity associated with information recall but increases activity in regions responsible for monitoring and information integration.22
Organizations must recognize and support this shift. Developer productivity can no longer be measured in lines of code written. Instead, metrics must evolve to track the quality of review, the architectural integrity of the system, and the ability of developers to effectively guide their AI “junior partners.” Training should focus not just on programming languages but on prompt engineering, critical review skills, and the principles of system design needed to effectively supervise AI. By doing so, organizations can manage the cognitive burden and transform a potentially frustrating tool into a truly synergistic partner.
Legal and IP governance navigating the minefield of AI generated code
The rapid adoption of generative AI in software development has created a legal and intellectual property (IP) minefield. The existing legal frameworks for copyright, licensing, and liability were not designed for a world in which non-human agents can generate creative works. For enterprises building proprietary software, the use of AI coding assistants without robust governance introduces profound risks, including the potential loss of copyright protection for core assets, inadvertent open source license violations, and unclear liability for code induced damages. Establishing a clear and rigorous governance framework is not an optional add on; it is an essential prerequisite for the safe use of these powerful tools.
The Copyright Conundrum: Who Owns AI Generated Code?
The most significant legal risk stems from the unsettled question of copyright ownership. In the United States, the legal precedent and the official stance of the U.S. Copyright Office are clear: copyright protection requires human authorship.31
-
The Human Authorship Requirement: A long line of legal precedent, culminating in recent decisions like Thaler v. Perlmutter, has affirmed that a work must originate from a human being to be copyrightable.33 The Copyright Office has repeatedly refused to register works created “autonomously” by AI, arguing that machines cannot be authors because they lack the creative capacity and legal personality to hold IP rights.31
-
The “Unenforceable Asset” Paradox: This creates a critical paradox for businesses. If a developer uses an AI to generate a substantial and creative piece of code with minimal human input, that code may not be protected by copyright. It could effectively fall into the public domain.32 This means the company that paid for its creation would be unable to stop a competitor from legally copying and using that same code. The tool used to accelerate the creation of a valuable asset simultaneously destroys its legal defensibility.
-
Establishing Sufficient Human Contribution: Copyright protection for AI assisted work hinges on the level of human involvement. If a developer significantly modifies, curates, or arranges AI generated code, they may be able to claim authorship over the final, integrated work.32 However, the legal threshold for “sufficient” contribution is not yet clearly defined, creating a gray area fraught with risk.
License Contamination: The Open Source Ticking Bomb
A more immediate and concrete risk is “license contamination.” AI models are trained on billions of lines of code from public repositories, much of which is governed by various open source licenses.34
-
Risk of Replication: AI models can and do replicate code snippets from their training data. If an AI generates code that is a verbatim or derivative copy of code licensed under a “copyleft” license, such as the GNU General Public License (GPL), and a developer incorporates it into a proprietary product, the company may be legally obligated to release its own source code under the same GPL terms.32
-
Scale of the Problem: This is not a theoretical risk. One analysis by the Software Freedom Conservancy found that approximately 35% of AI generated code samples contained potential licensing irregularities.34 Given that some reports indicate over 40% of all new code involves AI assistance, the potential for widespread license violations is enormous.34 This risk represents an existential threat to the business models of companies built on proprietary software.
Liability, Provenance, and Audit Trails
Beyond ownership, the use of AI introduces complex questions of liability and accountability.
-
Accountability for Flaws: If AI generated code leads to a security breach, a data privacy violation, or a system failure causing financial harm, who is liable? Is it the developer who accepted the suggestion, the company that deployed the code, the provider of the AI model, or all three? The legal framework for this is still emerging, but courts are likely to hold the deploying organization and its employees responsible for verifying the safety and correctness of their systems, regardless of how the code was generated.11
-
The Need for Provenance: To manage these risks, organizations must be able to trace the provenance of every line of code. This requires maintaining a clear audit trail that documents when AI was used, what prompts were given, what output was generated, and what human modifications were made. This documentation is critical for asserting human authorship in a copyright dispute, demonstrating compliance with licensing terms, and conducting forensic analysis after a security incident.41
Enterprise Safe Governance Practices
Given these profound risks, organizations must implement a multi-layered governance strategy for AI use in software development.
-
Establish a Clear AI Use Policy: The policy must explicitly define where AI use is permitted and where it is prohibited (e.g., no AI generation for security critical or core IP components). It should mandate the “AI as a Junior Developer” model, requiring human oversight for all generated code.
-
Mandate Human Review and Modification: The policy must require that all AI generated code intended for inclusion in a proprietary product be thoroughly reviewed and significantly modified by a human developer. The goal is to ensure the final work is a product of human creativity and control, sufficient to support a copyright claim.
-
Implement Automated License Scanning: CI/CD pipelines must include automated tools that scan all code, including AI generated contributions, for snippets of known open source code and potential license violations.
-
Maintain a Rigorous Audit Trail: Development workflows must be adapted to log AI interactions. Developers should be required to document their use of AI in commit messages or PR descriptions, creating a clear record of provenance.
-
Use Enterprise Grade, Indemnified AI Tools: Whenever possible, organizations should use enterprise versions of AI coding tools from reputable vendors (e.g., GitHub Copilot for Business, Amazon CodeWhisperer). These services often offer stronger data privacy controls (e.g., not using user prompts for model training) and may provide some level of IP indemnification, offering a layer of financial protection against copyright infringement claims.
-
Conduct Regular Training: Developers must be trained not only on how to use AI tools but also on the associated legal and security risks. This training should cover the company’s AI use policy, IP law fundamentals, and secure coding practices for reviewing AI output.
By treating AI generated code with the legal and operational seriousness it warrants, organizations can navigate this complex landscape, mitigating risk while still harnessing the benefits of AI driven productivity.
Decision framework a practical guide for AI adoption in coding
To translate the principles and risks discussed in this report into a practical, day to day operational tool, engineering leaders need a clear decision framework. This framework should empower developers and managers to quickly assess whether a given programming task is a suitable candidate for AI assistance and, if so, what level of human oversight is required.
The following decision tree provides a structured path for this assessment. It guides the user through a series of questions targeting the highest risk dimensions legal, security, and novelty to arrive at one of three recommended actions:
-
AI Use Not Recommended (Human Led Task): For tasks where the risks of inaccuracy, security failure, or IP loss are unacceptably high. The task should be performed by human experts.
-
AI Use Approved (High Supervision): For tasks where AI can provide value but requires strict oversight. This mandates the “AI as a Junior Developer” model with rigorous review, testing, and documentation.
-
AI Use Approved (Low Supervision): For low risk, well defined tasks where AI is known to excel. Review is still necessary but can be less intensive.
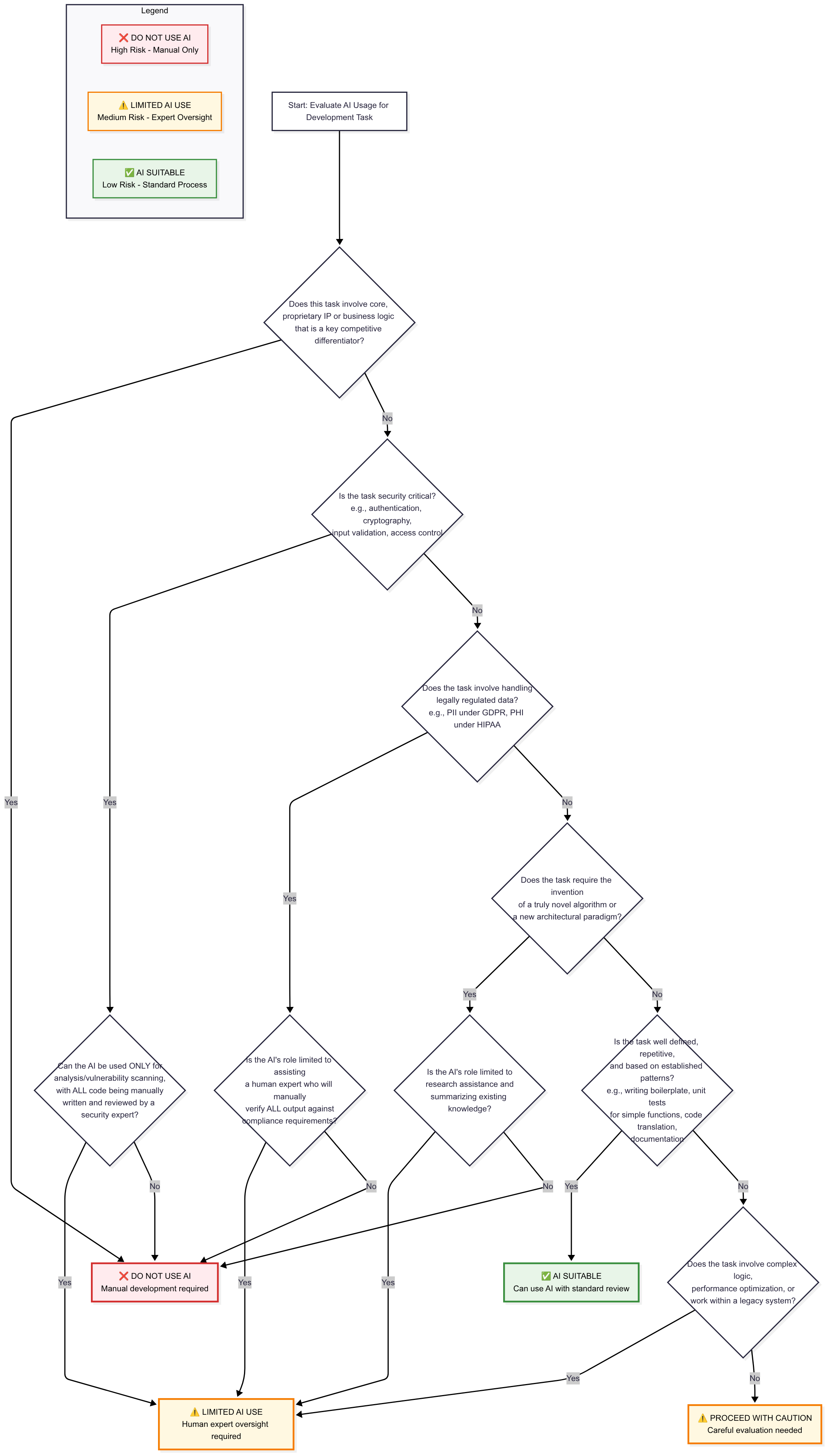
Decision Tree for AI Assisted Coding Tasks
This decision tree can be used as a checklist by engineering teams before initiating work on a task. It is presented here in a text based format that can be easily converted into a flowchart visualization for internal training and documentation.
Guidelines for Implementing the Framework
-
Integrate into Workflow: This decision tree should not be a one time exercise but should be integrated directly into the software development lifecycle (SDLC). For example, it can be part of the ticket creation process in a project management tool like Jira or included in the definition of “ready” for a user story.
-
Define Supervision Levels: The organization must clearly define what “High Supervision” and “Low Supervision” mean in practice.
-
High Supervision: This should mandate a formal code review by at least one senior engineer, 100% test coverage for the generated code, documentation of AI use in the pull request, and a final check against the ai learnings.md or other memory artifacts.
-
Low Supervision: This may require a standard peer review process, but with the understanding that the developer who commits the code is fully accountable for its correctness, security, and maintainability.
-
Empower, Don’t Paralyze: The goal of this framework is to enable safe AI adoption, not to create bureaucratic hurdles. It empowers teams by providing clarity and reducing ambiguity. It gives developers the confidence to use AI for appropriate tasks while protecting the organization from its most significant risks.
-
Iterate and Adapt: The field of AI is evolving rapidly. This framework should be considered a living document. The AI Governance team or a similar body should review and update it quarterly based on new research, emerging threats, and the evolving capabilities of AI tools.
By adopting a formal decision making framework, technology leaders can move beyond the hype and anxiety surrounding AI in software development. They can establish a culture of deliberate, risk aware innovation, ensuring that automation serves as a powerful tool to augment human expertise, not as an unaccountable replacement for it.
References and further reading
This report synthesizes information from a wide range of sources, including academic research, industry analysis, legal commentary, and practitioner insights. The following list of source identifiers corresponds to the citations used throughout the document. For further, in depth exploration of specific topics, readers are encouraged to consult the original materials.
-
4 OpsMx. “Security Risks of AI in Software Development: What You Need to Know.”
-
42 Safe AI. “AI Risk.”
-
1 Aditya Bhuyan. “Limitations of AI Driven Workflows in Software Development: What You Need to Know.” DEV.to.
-
3 Imaginary Cloud. “AI in Software Architecture.”
-
2 iSAQB. “Software Architects and AI Systems: Challenges and Opportunities.”
-
43 Analytics Vidhya. “Top 5 Failures of AI Till Date: Reasons & Solution.”
-
44 Surya Creatx. “Famous AI Project Failures and What We Learned.” Medium.
-
12 Evidently AI. “AI Failures: 10+ Real Life Examples.”
-
5 Security Journey. “How LLM Tools Can Help with Secure Coding.”
-
8 PR Newswire. “AI Creates Millions of New Code Vulnerabilities; Cycode Introduces AI Exploitability Agent.”
-
9 Lawfare. “AI and Secure Code Generation.”
-
6 University of Tennessee Knoxville OIT. “AI/Machine Learning Risks in Cybersecurity.”
-
7 Perception Point. “Top 6 AI Security Risks and How to Defend Your Organization.”
-
45 CrowdStrike. “AI Powered Cyberattacks.”
-
46 Wiz.io. “Top 6 AI Security Risks.”
-
10 One Legal. “AI Legal Issues, Risks, and Considerations.”
-
47 Clio. “Legal Innovation.”
-
11 Thomson Reuters Legal. “The Key Legal Issues with Gen AI.”
-
14 Simbo.ai. “Challenges in Implementing AI for Medical Coding.”
-
16 NAVEX. “Artificial Intelligence and Compliance: Preparing for the Future.”
-
15 Relyance AI. “AI Governance Examples: The Costly Mistakes of Failed AI Governance.”
-
13 Deutsche Welle. “When AI makes mistakes in the courtroom.”
-
48 Vktr. “5 AI Case Studies in Law.”
-
17 Lumenalta. “AI Limitations: What Artificial Intelligence Can’t Do.”
-
18 Mark Levise. “Understanding the Limitations of AI.” Medium.
-
19 Adcock Solutions. “6 Limitations of AI & Why it Won’t Quite Take Over.”
-
20 YouTube. “Can AI be Truly Creative?”
-
21 Elvtr. “Agent of Change: How AI Expands Human Creativity.”
-
49 Quora. “Could artificial intelligence ever learn to be truly creative?”
-
19 Adcock Solutions. “6 Limitations of AI & Why it Won’t Quite Take Over In 2023!”
-
50 Glair.ai. “5 Biggest Limitations of Artificial Intelligence.”
-
23 IOSR Journal. “Optimizing Software Performance Through AI: Techniques And Challenges.”
-
51 Hugging Face. “What Challenges Do Businesses Face When Developing AI Solutions?”
-
52 Ronin Consulting. “6 Business Problems That Can Be Solved by AI.”
-
53 McKinsey & Company. “Superagency in the workplace: Empowering people to unlock AI’s full potential.”
-
24 Michal Zarnecki. “Replace Complex Business Logic with AI Models.” Medium.
-
54 ResearchGate. “AI Driven Collaboration in Software Engineering: Enhancing Productivity and Innovation.”
-
55 McKinsey & Company. “How an AI enabled software product development life cycle will fuel innovation.”
-
25 Appfire. “AI in software development: Keep visibility as workflows evolve.”
-
27 Ugochukwu Benjamin C. “Learning to Code with AI Benefits and Drawbacks.” Medium.
-
38 Revelo. “AI Generated Code: Benefits, Risks, and Usage in Software Development.”
-
28 K. Naidoo. “Dangers of AI coding tools.” DEV Community.
-
56 Intertech. “Risks to Proprietary Data During AI Implementation.”
-
29 Zencoder. “AI Driven Refactoring for Addressing Legacy System Challenges.”
-
57 PYMNTS.com. “Open Source vs Proprietary AI: Which Should Businesses Choose?”
-
30 Sogeti Labs. “The Future of AI Agents in Migration Projects.”
-
33 U.S. Copyright Office. “Copyright and Artificial Intelligence.”
-
31 Outshift by Cisco. “AI and copyright: Protecting ownership and intellectual property rights.”
-
32 Adnan Masood. “Intellectual Property Rights and AI Generated Content.” Medium.
-
34 LeadrPro. “AI Generated Code: Who Owns the Intellectual Property Rights?”
-
35 Reddit r/aipromptprogramming. “My top 10 rules for vibe coding.”
-
36 Tomasz Smykowski. “Vibe Coding: How AI Turns Your Ideas Into Real Software.” DEV Community.
-
37 S Sankar. “8 Essential Tips to Master Claude Code for AI Powered Development.”
-
39 ODSC. “New Study Finds AI Tools Slow Experienced Developers in Familiar Codebases.” Medium.
-
40 Azalio. “AI coding tools can slow down seasoned developers by 19%.”
-
22 AI Buzz. “When AI Coders Hurt: New Study Finds They Slow Senior Devs.”
-
26 LeadDev. “Tech CEOs reckon with the impact of AI on junior developers.”
-
41 Eureka Software. “AI generated Code and Copyright: Who owns AI written Software?”
-
4 Synthesized research on AI limitations and risks.
-
1 Synthesized research on AI limitations in software architecture.
-
43 Synthesized research on AI failure case studies.
-
5 Synthesized research on AI induced security vulnerabilities.
-
10 Synthesized research on legal and ethical risks of AI in law.
-
35 Synthesized research on “vibe coding” principles.
-
24 Synthesized research on AI for complex business logic.
-
25 Synthesized research on AI’s impact on team collaboration.
-
30 Synthesized research on risks of AI in proprietary software migrations.
-
33 Synthesized research on the U.S. Copyright Office’s stance on AI.
-
35 Synthesized research on “vibe coding” principles.
Geciteerd werk
-
Limitations of AI Driven Workflows in Software Development: What …, geopend op juli 23, 2025, https://dev.to/adityabhuyan/limitations of ai driven workflows in software development what you need to know hoa
-
Software Architects and AI Systems: Challenges and Opportunities iSAQB, geopend op juli 23, 2025, https://www.isaqb.org/blog/software architects and ai systems challenges and opportunities/
-
The Role of AI in Software Architecture: Trends and Innovations Imaginary Cloud, geopend op juli 23, 2025, https://www.imaginarycloud.com/blog/ai in software architecture
-
Security Risks using AI in Software Development: Mitigation … OpsMx, geopend op juli 23, 2025, https://www.opsmx.com/blog/security risks of ai in software development what you need to know/
-
AI/LLM Tools for Secure Coding | Benefits, Risks, Training | Security …, geopend op juli 23, 2025, https://www.securityjourney.com/ai/llm tools secure coding
-
AI & Machine Learning Risks in Cybersecurity | Office of Innovative Technologies University of Tennessee, Knoxville, geopend op juli 23, 2025, https://oit.utk.edu/security/learning library/article archive/ai machine learning risks in cybersecurity/
-
Top 6 AI Security Risks and How to Defend Your Organization, geopend op juli 23, 2025, https://perception point.io/guides/ai security/top 6 ai security risks and how to defend your organization/
-
AI Creates Millions of New Code Vulnerabilities. Cycode Introduces AI Exploitability Agent to Prioritize and Fix What Matters 99% Faster. PR Newswire, geopend op juli 23, 2025, https://www.prnewswire.com/news releases/ai creates millions of new code vulnerabilities cycode introduces ai exploitability agent to prioritize and fix what matters 99 faster 302510724.html
-
AI and Secure Code Generation Lawfare, geopend op juli 23, 2025, https://www.lawfaremedia.org/article/ai and secure code generation
-
AI legal issues: Risks and considerations One Legal, geopend op juli 23, 2025, https://www.onelegal.com/blog/ai legal issues risks and considerations/
-
Key legal issues with generative AI for legal professionals Thomson Reuters Legal Solutions, geopend op juli 23, 2025, https://legal.thomsonreuters.com/blog/the key legal issues with gen ai/
-
When AI goes wrong: 10 examples of AI mistakes and failures, geopend op juli 23, 2025, https://www.evidentlyai.com/blog/ai failures examples
-
When AI makes mistakes in the courtroom, DW, 07/23/2025, geopend op juli 23, 2025, https://www.dw.com/en/when ai makes mistakes in the courtroom/a 73365735
-
Challenges in Implementing AI for Medical Coding: Addressing Compliance, Workforce Adaptation, and Ethical Concerns | Simbo AI Blogs, geopend op juli 23, 2025, https://www.simbo.ai/blog/challenges in implementing ai for medical coding addressing compliance workforce adaptation and ethical concerns 1180564/
-
AI Governance Examples Successes, Failures, and Lessons Learned | Relyance AI, geopend op juli 23, 2025, https://www.relyance.ai/blog/ai governance examples
-
Artificial Intelligence and Compliance: Preparing for the Future of AI Governance, Risk, and … NAVEX, geopend op juli 23, 2025, https://www.navex.com/en us/blog/article/artificial intelligence and compliance preparing for the future of ai governance risk and compliance/
-
AI’s limitations: 5 things artificial intelligence can’t do | Limitations of AI Lumenalta, geopend op juli 23, 2025, https://lumenalta.com/insights/ai limitations what artificial intelligence can t do
-
Understanding The Limitations Of AI (Artificial Intelligence) | by Mark Levis | Medium, geopend op juli 23, 2025, https://medium.com/@marklevisebook/understanding the limitations of ai artificial intelligence a264c1e0b8ab
-
6 Limitations of AI & Why it Won’t Quite Take Over In 2023! Adcock Solutions, geopend op juli 23, 2025, https://www.adcocksolutions.com/post/6 limitations of ai why it wont quite take over in 2023
-
The Algorithmic Creativity, Can AI Be Truly Creative? YouTube, geopend op juli 23, 2025, https://www.youtube.com/watch?v=2LIYp_oBNhM
-
Agent Of Change: How AI Expands Human Creativity ELVTR, geopend op juli 23, 2025, https://elvtr.com/blog/agent of change how ai expands human creativity
-
When AI Coders Hurt: New Study Finds They Slow Senior Devs AI Buzz, geopend op juli 23, 2025, https://www.ai buzz.com/when ai coders hurt new study finds they slow senior devs
-
Optimizing Software Performance Through AI … IOSR Journal, geopend op juli 23, 2025, https://www.iosrjournals.org/iosr jce/papers/Vol27 issue3/Ser 1/C2703011520.pdf
-
Replace Complex Business Logic with AI Models | by … Medium, geopend op juli 23, 2025, https://medium.com/@brightcode/replace complex business logic with ai models 3944f764e553
-
AI in software development: Keep visibility as workflows evolve …, geopend op juli 23, 2025, https://appfire.com/resources/blog/ai in software development
-
Tech CEOs reckon with the impact of AI on junior developers LeadDev, geopend op juli 23, 2025, https://leaddev.com/career development/tech ceos reckon with impact junior developers
-
Learning to Code with AI Benefits and Drawbacks | by Ugochukwu Benjamin .C | Medium, geopend op juli 23, 2025, https://medium.com/@kodiugos/learning to code with ai benefits and drawbacks 935f5b09ddde
-
Dangers of AI coding tools DEV Community, geopend op juli 23, 2025, https://dev.to/kwnaidoo/dangers of ai coding tools 2bnd
-
AI Driven Refactoring for Addressing Legacy System Challenges Zencoder, geopend op juli 23, 2025, https://zencoder.ai/blog/addressing legacy system challenges with ai driven refactoring
-
The Future of AI Agents in Migration Projects Sogeti Labs, geopend op juli 23, 2025, https://labs.sogeti.com/the future of ai agents in migration projects addressing resource constraints/
-
AI and copyright: Protecting ownership and intellectual property rights Outshift | Cisco, geopend op juli 23, 2025, https://outshift.cisco.com/blog/ai copyright protecting ownership intellectual property
-
Intellectual Property Rights and AI Generated Content Issues in Human Authorship, Fair Use Doctrine, and Output Liability | by Adnan Masood, PhD. | Medium, geopend op juli 23, 2025, https://medium.com/@adnanmasood/intellectual property rights and ai generated content issues in human authorship fair use 8c7ec9d6fdc3
-
Copyright and Artificial Intelligence | U.S. Copyright Office, geopend op juli 23, 2025, https://www.copyright.gov/ai/
-
AI Generated Code: Who Owns the Intellectual Property Rights? LeadrPro, geopend op juli 23, 2025, https://www.leadrpro.com/blog/who really owns code when ai does the writing
-
My top 10 rules for vibe coding. This is how I conjure fast, original …, geopend op juli 23, 2025, https://www.reddit.com/r/aipromptprogramming/comments/1jzg7yd/my_top_10_rules_for_vibe_coding_this_is_how_i/
-
Vibe Coding: How AI Turns Your Ideas Into Real Software DEV Community, geopend op juli 23, 2025, https://dev.to/tomaszs2/vibe coding how ai turns your ideas into real software 48ej
-
8 Essential Tips to Master Claude Code for AI Powered Development | by S Sankar, geopend op juli 23, 2025, https://levelup.gitconnected.com/8 essential tips to master claude code for ai powered development e7a3afe88252?source=rss 5517fd7b58a6 4
-
AI Generated Code: Benefits, Risks, and Usage in Software Development Revelo, geopend op juli 23, 2025, https://www.revelo.com/blog/ai generated code
-
New Study Finds AI Tools Slow Experienced Developers in Familiar Codebases | by ODSC, geopend op juli 23, 2025, https://odsc.medium.com/new study finds ai tools slow experienced developers in familiar codebases d92695f23665
-
AI coding tools can slow down seasoned developers by 19% Azalio, geopend op juli 23, 2025, https://www.azalio.io/ai coding tools can slow down seasoned developers by 19/
-
Ai generated Code and Copyright: Who owns Ai written Software?, geopend op juli 23, 2025, https://eurekasoft.com/blog/aigenerated code and copyright who owns aiwritten software
-
AI Risks that Could Lead to Catastrophe | CAIS Center for AI Safety, geopend op juli 23, 2025, https://safe.ai/ai risk
-
Top 5 Failures of AI Till Date | Reasons & Solution Analytics Vidhya, geopend op juli 23, 2025, https://www.analyticsvidhya.com/blog/2023/01/top 5 failures of ai till date reasons solution/
-
Famous AI Project Failures and What We Learned | by SuryaCreatX | Medium, geopend op juli 23, 2025, https://suryacreatx.medium.com/famous ai project failures and what we learned 4f6cfbafd017
-
Most Common AI Powered Cyberattacks | CrowdStrike, geopend op juli 23, 2025, https://www.crowdstrike.com/en us/cybersecurity 101/cyberattacks/ai powered cyberattacks/
-
7 Serious AI Security Risks and How to Mitigate Them Wiz, geopend op juli 23, 2025, https://www.wiz.io/academy/ai security risks
-
Legal Innovation in Law Firms: AI Risks and Opportunities Clio, geopend op juli 23, 2025, https://www.clio.com/blog/legal innovation/
-
5 AI Case Studies in Law VKTR.com, geopend op juli 23, 2025, https://www.vktr.com/ai disruption/5 ai case studies in law/
-
Could artificial intelligence ever learn to be truly creative, inventing new art forms or scientific theories beyond human imagination? Quora, geopend op juli 23, 2025, https://www.quora.com/Could artificial intelligence ever learn to be truly creative inventing new art forms or scientific theories beyond human imagination
-
5 Biggest Limitations of Artificial Intelligence glair.ai, geopend op juli 23, 2025, https://glair.ai/post/5 biggest limitations of artificial intelligence
-
What Challenges Do Businesses Face When Developing AI Solutions? Beginners, geopend op juli 23, 2025, https://discuss.huggingface.co/t/what challenges do businesses face when developing ai solutions/136481
-
6 Business Problems That Can Be Solved by AI Ronin Consulting, geopend op juli 23, 2025, https://www.ronin.consulting/artificial intelligence/business problems solved by ai/
-
Superagency in the workplace: Empowering people to unlock AI’s full potential McKinsey, geopend op juli 23, 2025, https://www.mckinsey.com/capabilities/mckinsey digital/our insights/superagency in the workplace empowering people to unlock ais full potential at work
-
AI Driven Collaboration in Software Engineering: Enhancing Productivity and Innovation, geopend op juli 23, 2025, https://www.researchgate.net/publication/390209266_AI Driven_Collaboration_in_Software_Engineering_Enhancing_Productivity_and_Innovation
-
How an AI enabled software product development life cycle will fuel innovation McKinsey, geopend op juli 23, 2025, https://www.mckinsey.com/industries/technology media and telecommunications/our insights/how an ai enabled software product development life cycle will fuel innovation
-
Risks to Proprietary Data During AI Implementation and How To Protect Your Data in an AI System Intertech, geopend op juli 23, 2025, https://www.intertech.com/risks to proprietary data during ai implementation and how to protect your data/
-
Open Source vs Proprietary AI: Which Should Businesses Choose? PYMNTS.com, geopend op juli 23, 2025, https://www.pymnts.com/artificial intelligence 2/2025/open source vs proprietary ai which should businesses choose/
Between automation and accountability a analysis of AI coding pitfalls, design failures, and operational guardrails.
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.