Data kwaliteit evolutie public sector Nederland
L1: Summary
Managementsamenvatting
De Nederlandse publieke sector bevindt zich op een cruciaal kantelpunt in haar digitale transformatie. De historische benadering van datamanagement gekenmerkt door een rigide scheiding tussen transactionele systemen (OLTP) en analytische rapportageomgevingen (OLAP) is niet langer toereikend voor de complexe eisen van het moderne digitale tijdperk. De gelijktijdige opkomst van Generatieve AI, de dwingende noodzaak tot real-time ketensamenwerking en de steeds striktere geopolitieke en juridische kaders (BIO, NIS2, AVG, EU AI Act, Archiefwet, Wet Open Overheid) dwingen overheidsorganisaties tot een fundamentele en strategische herziening van hun data-architectuur. Het tijdperk van vrijblijvende innovatie is voorbij; we betreden een fase van gereguleerde, soevereine en auditbare intelligentie.
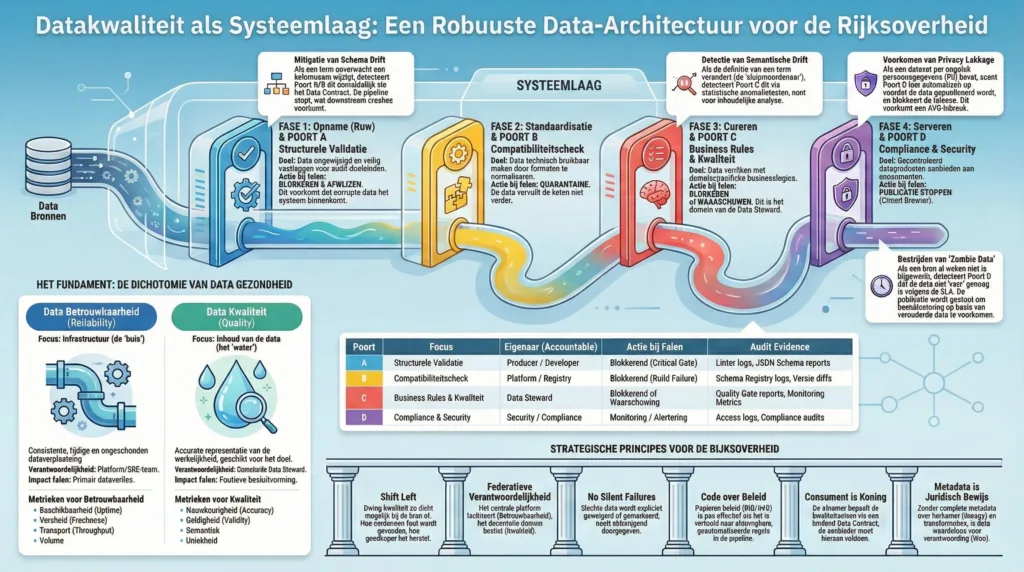
Dit onderzoeksrapport biedt een uitputtende analyse en een uitvoerbaar, architecturaal kader voor de transformatie van gefragmenteerde ‘legacy’ datalandschappen naar geïntegreerde, soevereine en intelligente dataplatforms. Uit onze analyse blijkt onomstotelijk dat een Sovereign Hybrid Lakehouse architectuur, ondersteund door een operating model gebaseerd op Team Topologies, de enige houdbare strategie is om digitale soevereiniteit te verenigen met de vereiste innovatiekracht en wendbaarheid. Wij constateren een significante ‘soevereiniteitskloof’ bij het onkritisch gebruik van publieke cloud-diensten, waarbij juridische garanties vaak niet stroken met de technische realiteit van extraterritoriale toegang.1 Deze kloof dient gedicht te worden door on-premise en soevereine cloud-implementaties te verkiezen boven generieke hyperscaler diensten, tenzij strikte encryptie (Hold Your Own Key, HYOK) en confidential computing worden toegepast om data ook tijdens verwerking (‘in use’) te beschermen.
De urgentie voor deze transitie wordt versterkt door de verschuiving van statische data-analyse naar dynamische, AI-gedreven interacties. Waar voorheen rapportages achteraf werden gedraaid, vereisen burgers en beleidsmakers nu real-time inzichten en voorspellende waarde. Dit vraagt om een infrastructuur die niet alleen data opslaat, maar deze ook begrijpt en veilig ontsluit via semantische zoektechnologie en gecontroleerde AI-agenten. Het risico van inactiviteit is niet slechts technologisch, maar raakt de kern van het openbaar bestuur: het verlies van controle over eigen data, afhankelijkheid van niet-Europese actoren en het onvermogen om te voldoen aan transparantieverplichtingen.
Top 10 Strategische Conclusies
De onderstaande conclusies vormen de synthese van onze analyse van het huidige technologische landschap, afgezet tegen de specifieke eisen van de Nederlandse overheid.
-
Het Einde van de Cloud-First Dogmatiek: De strategie ‘Cloud First’ is in de praktijk vervangen door ‘Cloud Smart’ en ‘Sovereign by Design’. Voor kritieke overheidsdata (classificatie Departementaal Vertrouwelijk en hoger) en vitale processen is on-premise infrastructuur of een strikt gecontroleerde sovereign cloud de enige optie die daadwerkelijk voldoet aan de eis van immuniteit tegen extraterritoriale wetgeving, zoals de Amerikaanse FISA 702.1 Dit vereist een herwaardering van de eigen datacenters en private cloud-omgevingen als strategische assets.
-
Convergentie van Database Paradigma’s: De historische strikte scheiding tussen SQL (relationeel) en NoSQL (niet-relationeel) vervaagt in hoog tempo. Moderne, toekomstbestendige architecturen vereisen ‘Converged Databases’ of Lakehouse-patronen die in staat zijn om zowel gestructureerde transacties (ACID-compliant) als ongestructureerde vector-data (voor AI-toepassingen) te ondersteunen binnen één uniform governance-kader. Het handhaven van gescheiden silo’s voor elk datatype is operationeel onhoudbaar geworden.
-
Search is Infrastructure, geen Feature: Zoektechnologie is geëvolueerd van een applicatie-feature naar fundamentele infrastructuur. Geavanceerde vector search en hybride retrieval (de combinatie van traditionele keyword search en moderne semantische zoektechnologie) zijn noodzakelijk om te voldoen aan de juridische ‘recall’ eisen van de Wet Open Overheid (WOO) en de contextuele precisie die Generatieve AI vereist.2 Zonder deze infrastructuur is effectieve ontsluiting van overheidsinformatie onmogelijk.
-
AI Vereist Strikte Lineage en Auditability: Het gebruik van AI in de publieke sector is ethisch en juridisch onmogelijk zonder volledige traceerbaarheid (lineage) van de keten: van ruwe data, via trainingsdataset en modelversie, naar de uiteindelijke beslissing. ‘Black box’ systemen zijn fundamenteel in strijd met de algemene beginselen van behoorlijk bestuur en de eisen van de aanstaande EU AI Act.3 Traceerbaarheid moet architecturaal worden afgedwongen, niet administratief.
-
Polyglot Persistence Vraagt om Strikte Governance: De wildgroei aan gespecialiseerde database-types (graph, time-series, document, key-value) leidt zonder centrale regie tot een onbeheersbare operationele complexiteit en fragmentatie van data. Een strikte ‘Paved Road’ of ‘Golden Path’ aanpak, waarbij teams kiezen uit een beperkte set van goed ondersteunde standaarden, is vereist om deze fragmentatie te voorkomen en beheerbaarheid te garanderen.
-
Supply Chain Security is de Nieuwe Perimeter: Met de introductie van NIS2 verschuift de primaire focus van netwerkbeveiliging naar de integriteit van de software supply chain. Het gebruik van Software Bill of Materials (SBOMs), cryptografische ondertekening (signing) van artifacts en strikte provenancetracking zijn verplicht voor alle database- en AI-componenten om te voorkomen dat malafide code of modellen de overheidssystemen binnendringen.5
-
Data Mesh als Organisatorisch Antwoord op Schaalbaarheid: Centrale datateams vormen steeds vaker de bottleneck in innovatie en rapportage. Een transitie naar domeingeoriënteerd eigenaarschap (Data Mesh), waarbij domeinteams verantwoordelijk zijn voor hun eigen dataproducten maar ondersteund worden door een centraal platformteam dat de infrastructuur levert, is noodzakelijk om schaalbaar te blijven in een complexe overheidscontext.
-
Agentic AI Introduceert Nieuwe Risicoklassen: De overgang van passieve AI-tools naar autonome AI-agenten (‘Agentic AI’) introduceert fundamenteel nieuwe risico’s. Dit vereist nieuwe controlemechanismen, waaronder verplichte ‘human-in-the-loop’ goedkeuring voor elke destructieve actie of beslissing met rechtsgevolgen, en strikte ’tool gating’ om de actieradius van agenten technisch te beperken.4
-
Legacy is een Actief Risico (Liability): Systemen die technisch niet in staat zijn te integreren met moderne authenticatiestandaarden (zoals OIDC) of moderne encryptiestandaarden, vormen een direct en onacceptabel risico voor de ketenveiligheid. Deze systemen moeten prioriteit krijgen voor inkapseling (containment) of uitfasering, aangezien zij de zwakste schakel vormen in een Zero Trust architectuur.
-
FinOps is Essentieel voor On-Premise Beheersbaarheid: De kosten van AI-compute (GPU’s) en grootschalige data-opslag op eigen infrastructuur kunnen zonder sturing exploderen. Een FinOps-mindset, gericht op unit-economics, capaciteitsplanning en toerekening van kosten, is essentieel voor een duurzaam on-premise beheer, vergelijkbaar met cloud-kostenbeheer.
Top 10 Risico’s en Mitigaties
| Risico | Context | Impact | Mitigatie |
|---|---|---|---|
| Vendor Lock-in via SaaS | Afhankelijkheid van propriëtaire AI/Data platforms zonder exit-pad. | Onmogelijkheid om van leverancier te wisselen; data gijzeling; soevereiniteitsverlies. | Exit Strategie Verplichting: Contractueel en technisch afdwingen van open data formaten (Parquet, Iceberg) en API-standaarden. ^1 |
| Data Swamp door Lakehouse | Ongecontroleerde dump van data in object storage zonder schema of eigenaar. | Onvindbare data, non-compliance met AVG/WOO, ‘Garbage In, Garbage Out’. | Data Contracts: Afdwingen van schema en kwaliteit bij ingestie. Automated Lifecycle: Verplichte TTL policies. ^1 |
| Schaduw-AI Gebruik | Teams gebruiken publieke ChatGPT met gevoelige overheidsdata. | Datalekken van staatsgeheimen of persoonsgegevens naar commerciële partijen. | Private AI Faciliteit: Bied een intern, veilig alternatief (Private LLM). Blokkeer toegang tot publieke AI-endpoints. ^4 |
| Hallucinerende Agenten | AI-agenten nemen autonome beslissingen op basis van onjuiste feiten. | Juridische fouten, reputatieschade, onterechte beschikkingen. | Grounding & Human-in-the-loop: Verplicht gebruik van RAG met bronvermelding. Kritieke acties vereisen menselijke accordering. ^4 |
| Supply Chain Poisoning | Malafide code of modellen geïnjecteerd via open source dependencies. | Achterdeurtjes in vitale systemen, data exfiltratie. | Private Registry & Signing: Gebruik alleen getekende artifacts uit eigen beveiligde registry. Scan alle inkomende containers/modellen. ^5 |
| Cognitieve Overbelasting | DevOps teams bezwijken onder de complexiteit van DB/AI beheer. | Uitval van personeel, configuratiefouten, security incidenten. | Platform Engineering: Centraliseer complexiteit in het platformteam. Bied ‘Golden Paths’ aan voor standaard use cases. ^5 |
| Legacy Obstructie | Oude systemen blokkeren integratie met moderne IAM/Zero Trust. | Kwetsbare plekken in het netwerk, onmogelijkheid tot ketenintegratie. | Containment Pattern: Isoleer legacy achter moderne API-gateways en proxies (sidecar pattern). Plan harde uitfasering. |
| Compliance Paralysis | Angst voor regelgeving (AVG, AI Act) legt innovatie stil. | Achterstand in dienstverlening, inefficiëntie, maatschappelijke onvrede. | Compliance as Code: Automatiseer controles in de pipeline. Enabling teams adviseren proactief in plaats van alleen blokkeren. ^5 |
| Kostenexplosie On-Prem | Onderschatting van TCO voor GPU-clusters en storage. | Budgetoverschrijdingen, stilvallen van projecten. | FinOps & Showback: Maak kosten inzichtelijk per team/domein. Deel resources dynamisch (Kubernetes quotas). |
| Federatieve Chaos | Gebrek aan standaarden leidt tot onbruikbare data-uitwisseling in de keten. | Inefficiënte ketensamenwerking, fouten in gegevensuitwisseling. | Data Governance Board: Stel interbestuurlijke standaarden vast voor metadata en API’s. Gebruik een federatieve catalogus. ^1 |
RisicoContextImpactMitigatieVendor Lock-in via SaaSAfhankelijkheid van propriëtaire AI/Data platforms zonder exit-pad.Onmogelijkheid om van leverancier te wisselen; data gijzeling; soevereiniteitsverlies.Exit Strategie Verplichting: Contractueel en technisch afdwingen van open data formaten (Parquet, Iceberg) en API-standaarden. 1Data Swamp door LakehouseOngecontroleerde dump van data in object storage zonder schema of eigenaar.Onvindbare data, non-compliance met AVG/WOO, ‘Garbage In, Garbage Out’.Data Contracts: Afdwingen van schema en kwaliteit bij ingestie. Automated Lifecycle: Verplichte TTL policies. 1Schaduw-AI GebruikTeams gebruiken publieke ChatGPT met gevoelige overheidsdata.Datalekken van staatsgeheimen of persoonsgegevens naar commerciële partijen.Private AI Faciliteit: Bied een intern, veilig alternatief (Private LLM). Blokkeer toegang tot publieke AI-endpoints. 4Hallucinerende AgentenAI-agenten nemen autonome beslissingen op basis van onjuiste feiten.Juridische fouten, reputatieschade, onterechte beschikkingen.Grounding & Human-in-the-loop: Verplicht gebruik van RAG met bronvermelding. Kritieke acties vereisen menselijke accordering. 4Supply Chain PoisoningMalafide code of modellen geïnjecteerd via open source dependencies.Achterdeurtjes in vitale systemen, data exfiltratie.Private Registry & Signing: Gebruik alleen getekende artifacts uit eigen beveiligde registry. Scan alle inkomende containers/modellen. 5Cognitieve OverbelastingDevOps teams bezwijken onder de complexiteit van DB/AI beheer.Uitval van personeel, configuratiefouten, security incidenten.Platform Engineering: Centraliseer complexiteit in het platformteam. Bied ‘Golden Paths’ aan voor standaard use cases. 5Legacy ObstructieOude systemen blokkeren integratie met moderne IAM/Zero Trust.Kwetsbare plekken in het netwerk, onmogelijkheid tot ketenintegratie.Containment Pattern: Isoleer legacy achter moderne API-gateways en proxies (sidecar pattern). Plan harde uitfasering.Compliance ParalysisAngst voor regelgeving (AVG, AI Act) legt innovatie stil.Achterstand in dienstverlening, inefficiëntie, maatschappelijke onvrede.Compliance as Code: Automatiseer controles in de pipeline. Enabling teams adviseren proactief in plaats van alleen blokkeren. 5Kostenexplosie On-PremOnderschatting van TCO voor GPU-clusters en storage.Budgetoverschrijdingen, stilvallen van projecten.FinOps & Showback: Maak kosten inzichtelijk per team/domein. Deel resources dynamisch (Kubernetes quotas).Federatieve ChaosGebrek aan standaarden leidt tot onbruikbare data-uitwisseling in de keten.Inefficiënte ketensamenwerking, fouten in gegevensuitwisseling.Data Governance Board: Stel interbestuurlijke standaarden vast voor metadata en API’s. Gebruik een federatieve catalogus. 1
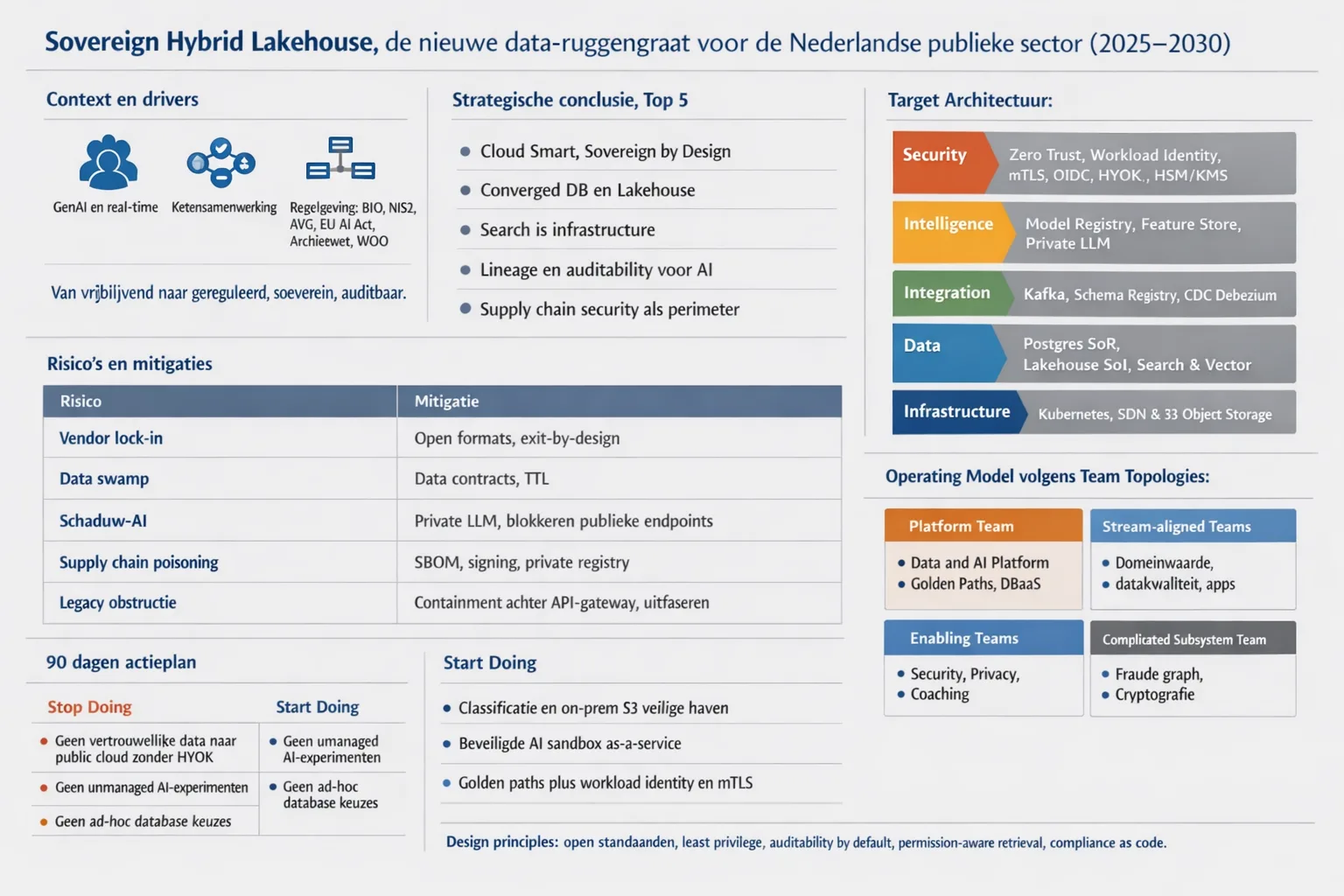
Target Architecture (5 Bullets)
-
Infrastructure: Een Hybride Soevereine Cloud opzet, bestaande uit een On-Premise Core voor de meest gevoelige workloads en een Trusted Partner Cloud voor schaalbare, minder gevoelige taken. De fundering wordt gevormd door Kubernetes voor compute-abstractie en S3-compatibele object storage voor universele data-opslag.
-
Data Layer: Een Lakehouse Architectuur die gebruik maakt van open tabelformaten (zoals Delta Lake of Apache Iceberg) om een strikte scheiding tussen compute en storage te realiseren. Dit garandeert volledige auditability, ’time travel’ functionaliteit voor historische reconstructie en voorkomt vendor lock-in op dataniveau.1
-
Intelligence Layer: Een modulair en container-gebaseerd AI-platform, dat Vector Stores voor semantisch geheugen, Feature Stores voor modelconsistentie en lokale LLM/SLM-hosting faciliteiten omvat. Deze laag is strikt afgeschermd van het publieke internet en opereert binnen de beveiligde zone.
-
Integration: Een Event-Driven Architectuur gebaseerd op standaarden zoals Apache Kafka of NATS, aangevuld met strikte schema-validatie (Schema Registry) en API-gateways. Dit faciliteert veilige, asynchrone gegevensuitwisseling tussen interne domeinen en externe ketenpartners.
-
Security: Een compromisloze Zero Trust Architectuur waarin netwerkvertrouwen is geëlimineerd. Toegang wordt uitsluitend verleend op basis van geverifieerde identiteit (Workload Identity, mTLS, OIDC) en data wordt altijd versleuteld opgeslagen en getransporteerd, waarbij de encryptiesleutels te allen tijde in eigen beheer blijven (HSM/KMS integratie).
Stop Doing / Start Doing
| Stop Doing | Start Doing |
|---|---|
| Stop met het blindelings verplaatsen van datasets met classificatie ‘Vertrouwelijk’ of hoger naar publieke clouds zonder HYOK-architectuur. | Start met het inventariseren en classificeren van alle datasets en het inrichten van een on-premise S3-compatibele storage layer als veilige haven. |
| Stop met het gedogen van AI-experimenten op lokale laptops of in onbeheerde persoonlijke cloud-accounts. | Start met het inrichten van een centraal ‘Platform Team’ dat een beveiligde, gecontaineriseerde AI-ontwikkelomgeving (sandbox) als dienst aanbiedt aan teams. |
| Stop met het opslaan van kritieke logfiles in platte tekst, op lokale disks of zonder strikt retentiebeleid. | Start met de implementatie van centrale, onwijzigbare (immutable) logging en archivering die voldoet aan de eisen van de Archiefwet en WOO. |
| Stop met ad-hoc database selecties door individuele teams op basis van persoonlijke voorkeur (“Resume Driven Development”). | Start met het definiëren en publiceren van ‘Golden Paths’ voor PostgreSQL, Vector en Object Stores met pre-approved, veilige configuraties. |
| Stop met het vertrouwen op traditionele netwerk-perimeterbeveiliging (firewalls) als enige verdedigingslinie. | Start met de implementatie van workload identity en mTLS authenticatie tussen alle services binnen het domein. |
Stop DoingStart DoingStop met het blindelings verplaatsen van datasets met classificatie ‘Vertrouwelijk’ of hoger naar publieke clouds zonder HYOK-architectuur.Start met het inventariseren en classificeren van alle datasets en het inrichten van een on-premise S3-compatibele storage layer als veilige haven.Stop met het gedogen van AI-experimenten op lokale laptops of in onbeheerde persoonlijke cloud-accounts.Start met het inrichten van een centraal ‘Platform Team’ dat een beveiligde, gecontaineriseerde AI-ontwikkelomgeving (sandbox) als dienst aanbiedt aan teams.Stop met het opslaan van kritieke logfiles in platte tekst, op lokale disks of zonder strikt retentiebeleid.Start met de implementatie van centrale, onwijzigbare (immutable) logging en archivering die voldoet aan de eisen van de Archiefwet en WOO.Stop met ad-hoc database selecties door individuele teams op basis van persoonlijke voorkeur (“Resume Driven Development”).Start met het definiëren en publiceren van ‘Golden Paths’ voor PostgreSQL, Vector en Object Stores met pre-approved, veilige configuraties.Stop met het vertrouwen op traditionele netwerk-perimeterbeveiliging (firewalls) als enige verdedigingslinie.Start met de implementatie van workload identity en mTLS authenticatie tussen alle services binnen het domein.
L2: Strategische Analyse
2.1 Database Evolutie Timeline: Lessen uit het Verleden
De geschiedenis van databasetechnologie in de publieke sector is geen rechtlijnige progressie van ‘slecht’ naar ‘goed’, maar een cyclische beweging tussen uitersten: van strikte consistentie naar flexibiliteit, en van centralisatie naar decentralisatie. Het begrijpen van deze historische context is essentieel om huidige trends te duiden en niet mee te gaan in kortstondige hypes die fundamentele overheidsbelangen schaden.
1960-1970: De Hiërarchische Era (IMS, CODASYL), De Geboorte van de Basisregistratie
-
Concept: Data werd opgeslagen in starre, boomachtige structuren. Relaties waren hard gecodeerd via pointers.
-
Public Sector Context: Dit vormde de basis van de eerste grote overheidsadministraties, zoals de GBA (voorloper BRP) en belastingsystemen op mainframes.
-
Waarom het faalde (als universele oplossing): Extreme rigiditeit. Een simpele wijziging in de datastructuur (bijv. toevoegen van een veld door wetswijziging) vereiste wekenlang herprogrammeren van de applicatie.
-
Les: Flexibiliteit in schema-evolutie (schema evolution) is cruciaal voor een overheid die continu moet anticiperen op veranderende wetgeving.
1980-2000: De Relationele Hegemonie (RDBMS, Oracle, DB2, SQL Server), De Gouden Standaard
-
Concept: Data werd losgekoppeld van de applicatie en opgeslagen in genormaliseerde tabellen, benaderbaar via een standaardtaal (SQL). Het ACID-principe (Atomicity, Consistency, Isolation, Durability) garandeerde data-integriteit.
-
Public Sector Context: RDBMS werd de onbetwiste standaard voor alle kernregistraties, ERP-systemen en primaire processen. De zekerheid van transacties was perfect voor het vastleggen van feiten met rechtsgevolgen (beschikkingen, betalingen).
-
Waarom het bleef: De wiskundige zekerheid van het relationele model is onmisbaar voor de democratische verantwoording. Een financiële transactie mag nooit ‘eventually consistent’ zijn.
-
Limitatie: Schaalbaarheid was voornamelijk verticaal (grotere server kopen), wat leidde tot hoge kosten en vendor lock-in. Ook was het model slecht geschikt voor ongestructureerde data (brieven, foto’s, dossiers).
2000-2010: De NoSQL Revolutie en Data Lakes (Hadoop, MongoDB), De Reactie op Web-Scale
-
Concept: Schema-on-read, horizontale schaalbaarheid op goedkope hardware, en het CAP-theorem (kiezen voor Availability boven Consistency).
-
Public Sector Context: Opkomst van big data analyses, fraudedetectie op ongestructureerde data en pogingen om ‘alles’ op te slaan in Data Lakes.
-
Waarom het faalde (deels): Veel Data Lakes veranderden in ‘Data Swamps’. Zonder schema-handhaving werd de datakwaliteit onbetrouwbaar. Voor primaire overheidsprocessen bleek “Eventual consistency” onacceptabel; een burger wil direct zekerheid over de status van een aanvraag, niet ‘ooit’.
2010-2020: NewSQL en de Cloud Data Warehouse (Snowflake, Spanner), De Synthese
-
Concept: De horizontale schaalbaarheid van NoSQL gecombineerd met de ACID-garanties van SQL. Cloud-native architecturen scheidden compute van storage.
-
Public Sector Context: Start van de migratie naar cloud warehouses voor BI en analytics.
-
Risico: Dit introduceerde nieuwe vormen van vendor lock-in en complexe vraagstukken rondom data soevereiniteit (Cloud Act, Schrems II), wat leidde tot de huidige terughoudendheid.
2020-Heden: Het Lakehouse, Vector en Convergence, Het Tijdperk van AI
-
Concept: Open tabelformaten (Delta Lake, Apache Iceberg) brengen ACID-transacties en management naar goedkope object storage (Data Lakes). Databases worden ‘multimodaal’ en ondersteunen SQL, JSON, Graph en Vector data in één engine.
-
Public Sector Driver: De noodzaak om AI-modellen (die vectoren en ongestructureerde data nodig hebben) direct naast de transactionele data te draaien voor RAG (Retrieval Augmented Generation), zonder complexe en kwetsbare ETL-pijplijnen. Dit maakt auditability van AI mogelijk.
2.2 Huidig Landschap: Categorieën en Archetypen
Voor de Nederlandse overheid identificeren we vier dominante archetypen die in de periode 2025-2030 relevant zijn. De focus verschuift van pure technologie naar de rol die de database speelt in de architectuur.
-
De System of Record (SoR), RDBMS++
-
Technologie: PostgreSQL (de dominante open source standaard), Oracle (legacy/high-end workloads), SQL Server.
-
Positie: De onbetwiste waarheid voor primaire processen. Hier staan de kernregistraties en financiële feiten.
-
Evolutie: Deze databases zijn niet langer statisch; ze integreren functionaliteiten zoals JSON-opslag en Vector-search (bv. pgvector), waardoor ze hybride workloads aankunnen zonder data te dupliceren.
-
Trade-off: Schaalbaarheid blijft een uitdaging voor extreme volumes; focus ligt op consistentie en integriteit.
-
De Analytische Powerhouse, Sovereign Lakehouse
-
Technologie: Trino, Spark, DuckDB draaiend op S3-compatibele storage (MinIO/Ceph) met open tabelformaten (Iceberg/Delta).
-
Positie: Zware analyses, ketenrapportages, archivering en grootschalige WOO-verzoeken over petabytes aan data.
-
Voordeel: Scheiding van storage en compute maakt dit de enige betaalbare optie voor lange-termijn archivering en big data on-premise. Het gebruik van open formaten garandeert dat data leesbaar blijft, zelfs als de software verandert (Exit Strategie).1
-
De Gespecialiseerde Store, Graph & Time-Series
-
Technologie: Neo4j (Graph), InfluxDB/Prometheus (Metrics/Time-Series).
-
Positie: Specifieke, hoogwaardige use cases. Graph databases zijn essentieel voor fraudenetwerkanalyse, ondermijning en het in kaart brengen van complexe relaties in wetgeving. Time-series zijn cruciaal voor IoT (bruggen, sluizen) en IT-monitoring.
-
Waarschuwing: Gebruik deze alleen als het relationele model faalt; vermijd onnodige complexiteit (“Polyglot Pollution”).
-
De AI-Enabler, Vector Database
-
Technologie: Weaviate, Qdrant, Milvus (dedicated) of pgvector/Elastic (integrated).
-
Positie: Het ‘lange termijn geheugen’ voor LLM’s en AI-agenten. Essentieel voor RAG-toepassingen waarbij overheidsdocumenten en beleidsstukken semantisch doorzoekbaar moeten zijn.
-
Trade-off: Dedicated vector DB’s bieden betere performance en features voor AI (zoals hybrid search), maar introduceren een nieuw beheerd component.
2.3 Public Sector Drivers en Compliance
De technologische keuzes worden ingekaderd door dwingende drivers die uniek zijn voor de publieke sector:
-
Wet Open Overheid (WOO) & Archiefwet: Overheidssystemen moeten niet alleen de huidige staat van data opslaan, maar ook de historische context en metadata duurzaam bewaren. Een database die records overschrijft zonder historie (audit trail / time travel) is per definitie non-compliant voor besluitvormingsprocessen. Het Lakehouse-concept met ‘Time Travel’ functionaliteit biedt hier een technisch antwoord op.1
-
Digitale Soevereiniteit & Geopolitiek: De afhankelijkheid van niet-EU leveranciers voor kritieke infrastructuur wordt steeds meer gezien als een nationaal veiligheidsrisico. Dit drijft de strategische beweging naar open source software, open data-standaarden en het in eigen beheer houden van encryptiesleutels (HYOK). Het doel is autonomie: de staat moet te allen tijde zelfstandig kunnen functioneren.
-
Ketensamenwerking & Federatie: Data moet vloeien tussen organisaties (bv. Justitie, Belastingdienst, UWV, Gemeenten) zonder dat data onnodig gekopieerd wordt, wat leidt tot inconsistentie. Dit vereist standaarden voor ‘Data bij de Bron’ en federatieve bevraging, ondersteund door sterke Identity & Access Management (IAM) standaarden.
-
EU AI Act & Transparantie: De inzet van AI in hoog-risico domeinen (zoals sociale zekerheid of rechtspraak) vereist extreme transparantie. Elke output van een AI-systeem moet herleidbaar zijn naar de bron. Dit diskwalificeert ‘black box’ databases en modellen waar deze lineage niet gegarandeerd kan worden.
2.4 Capability Map: Bezitten versus Inkopen
In een soevereine on-prem context verandert de klassieke ‘buy vs. build’ discussie naar ‘operate vs. consume’. Wat moet de overheid zelf beheren om soevereiniteit te borgen, en wat kan als commodity worden afgenomen (binnen strikte kaders)?
| Capability | Advies (On-Prem/Sovereign) | Rationale & Trade-offs |
|---|---|---|
| Commodity RDBMS (Postgres/MySQL) | Operate (via Platform Team) | Volwassen Kubernetes-operators (zoals CloudNativePG) maken zelfbeheer haalbaar en vaak goedkoper dan managed services. Zelfbeheer geeft volledige controle over patches, extensies en encryptie. |
| Vector Search / AI Infra | Operate (Dedicated Team) | Deze data is vaak te gevoelig voor externe SaaS. Performance (latency) vereist fysieke nabijheid tot de data. Vereist specialistische kennis die intern opgebouwd moet worden. |
| Identity (IAM) | Own / Control | Identity is de nieuwe perimeter. De Identity Provider (IdP) moet onder absolute eigen controle staan (bv. Keycloak of sovereign beheerde dienst). Het uitbesteden van identity is het uitbesteden van de sleutels tot het koninkrijk. |
| Logging & SIEM | Hybrid | Log collectie en opslag moeten on-premise gebeuren (data gravity/residency). Analyse kan eventueel via gespecialiseerde (lokale) security partners, mits data residency gegarandeerd is en data niet de EU verlaat. |
| GenAI Modellen (LLM) | Own / Host | Gebruik open weights modellen (Llama, Mistral) gehost op eigen GPU-infrastructuur voor alle vertrouwelijke en interne data. Gebruik publieke SaaS-modellen alleen voor publieke, niet-gevoelige data en content creatie, en nooit voor besluitvorming.^4 |
CapabilityAdvies (On-Prem/Sovereign)Rationale & Trade-offsCommodity RDBMS (Postgres/MySQL)Operate (via Platform Team)**Volwassen Kubernetes-operators (zoals CloudNativePG) maken zelfbeheer haalbaar en vaak goedkoper dan managed services. Zelfbeheer geeft volledige controle over patches, extensies en encryptie.**Vector Search / AI InfraOperate (Dedicated Team)**Deze data is vaak te gevoelig voor externe SaaS. Performance (latency) vereist fysieke nabijheid tot de data. Vereist specialistische kennis die intern opgebouwd moet worden.Identity (IAM)****Own / ControlIdentity is de nieuwe perimeter. De Identity Provider (IdP) moet onder absolute eigen controle staan (bv. Keycloak of sovereign beheerde dienst). Het uitbesteden van identity is het uitbesteden van de sleutels tot het koninkrijk.**Logging & SIEMHybridLog collectie en opslag moeten on-premise gebeuren (data gravity/residency). Analyse kan eventueel via gespecialiseerde (lokale) security partners, mits data residency gegarandeerd is en data niet de EU verlaat.GenAI Modellen (LLM)****Own / HostGebruik open weights modellen (Llama, Mistral) gehost op eigen GPU-infrastructuur voor alle vertrouwelijke en interne data. Gebruik publieke SaaS-modellen alleen voor publieke, niet-gevoelige data en content creatie, en nooit voor besluitvorming.4
L3: Architectuur en Design Guide
3.1 Reference Architecture: De Soevereine Hybride Stack
Deze referentiearchitectuur is modulair opgebouwd in lagen, specifiek ontworpen om vendor lock-in te minimaliseren, auditability te maximaliseren en te voldoen aan de strenge eisen van de Nederlandse overheid.
3.1.1 Infrastructure Layer (De Fundering)
-
Compute: Kubernetes (k8s) is de onbetwiste standaard abstractielaag. Het maakt workloads portabel tussen on-prem datacenters en diverse sovereign clouds. Het gebruik van Kubernetes stelt de overheid in staat om applicaties te verplaatsen zonder code-wijzigingen (“Write Once, Run Anywhere”).
-
Storage: Object Storage (S3-API compliant, bijv. MinIO, Ceph of Scality) fungeert als de universele, schaalbare opslaglaag. Block storage (CSI) wordt gereserveerd voor performance-kritieke transactionele databases. De keuze voor S3-API als standaard voorkomt lock-in op storage-hardware.
-
Network: Software Defined Networking (SDN) met strikte micro-segmentatie (bijv. Cilium of Calico). Het standaard beveiligingsbeleid is ‘Deny All’; verkeer tussen componenten wordt alleen toegestaan als het expliciet is gedefinieerd.
3.1.2 Data Persistence Layer (Polyglot Governance)
We onderscheiden drie strikte architectuurpatronen voor dataopslag om wildgroei te voorkomen:
-
Transactional (OLTP), System of Record: PostgreSQL is de standaard ‘golden path’ keuze voor nieuwe applicaties. Voor legacy-systemen is Oracle of SQL Server toegestaan, mits deze worden ingekapseld en uitgefaseerd volgens roadmap. Consistentie en integriteit staan hier voorop.
-
Analytical (OLAP), System of Insight: Het Lakehouse patroon is leidend. Data landt in een ‘Bronze’ zone (ruw, ongewijzigd), wordt verwerkt naar ‘Silver’ (schoon, gepseudonimiseerd, gestructureerd) en ‘Gold’ (geaggregeerd voor rapportage). Opslag gebeurt in open formaten zoals Parquet en Iceberg/Delta Lake. Dit garandeert dat data toegankelijk blijft, ongeacht de query-engine.
-
Vector & Search, System of Intelligence: Elasticsearch of OpenSearch voor traditionele keyword search en log-analyse. Weaviate, Qdrant of pgvector voor semantische search en AI-toepassingen. Deze systemen zijn geoptimaliseerd voor het snel doorzoeken van ongestructureerde data.
3.1.3 Integration & Streaming Layer
-
Event Bus: Apache Kafka of NATS fungeert als het centrale zenuwstelsel voor asynchrone communicatie tussen domeinen. Dit ontkoppelt systemen (loose coupling) en voorkomt onbeheersbare punt-naar-punt integraties (“spaghetti-architectuur”).
-
CDC (Change Data Capture): Tools zoals Debezium luisteren direct naar de transactielogs van databases en publiceren wijzigingen real-time naar de event bus. Dit is cruciaal om zoekindexes, cache-lagen en AI-modellen up-to-date te houden zonder zware, vertragende batch-jobs.
3.1.4 Intelligence & AI Layer
-
Model Registry: Een centrale administratie (bijv. MLflow) voor versiebeheer van AI-modellen. Hierin wordt vastgelegd welke versie van een model, getraind op welke dataset, op welk moment in productie stond. Dit biedt de vereiste lineage naar trainingsdata.5
-
Feature Store: Centrale opslag van voorberekende model-features om consistentie te borgen tussen training en inferentie. Dit voorkomt ’training-serving skew’.
-
Inference Server: Gecontaineriseerde platforms (zoals KServe of Triton) voor het schaalbaar en veilig serveren van modellen via standaard API’s (V2 inference protocol), draaiend op eigen GPU-resources.
3.2 Decision Matrix: Database Selectie
Om technologische wildgroei te voorkomen, hanteren we een dwingende beslisboom voor architecten en teams:
| Karakteristiek | Aanbevolen Technologie | Waarom? (Rationale & Context) |
|---|---|---|
| Gestructureerd, ACID, Relaties | PostgreSQL | De facto open source standaard, enorm ecosysteem, ondersteunt JSON/Vector, geen licentiekosten, uitstekende Kubernetes support. |
| Ongestructureerd, Analytics, Archief | Lakehouse (S3 + Iceberg) | Kostenefficiënt voor grote volumes, scheiding compute/storage (schaalbaarheid), open standaard (geen lock-in), ondersteunt ’time travel’. |
| Full-text Search, Logs | OpenSearch / Elasticsearch | Bewezen technologie voor tekst en logs, krachtige aggregaties, breed geaccepteerd in de markt. |
| Semantische Search (RAG) | Vector DB (Weaviate/pgvector) | Noodzakelijk voor AI context retrieval. Pgvector voor eenvoudige cases (geïntegreerd in Postgres), Weaviate/Qdrant voor schaal en hybrid search. |
| Complexe Netwerken (Fraude) | Graph DB (Neo4j) | Relaties zijn ‘first class citizens’. Performant bij diepe traversals (vriend-van-vriend-van-vriend) waar SQL faalt. |
| High Frequency Metrics (IoT) | Time-Series (Prometheus/Influx) | Geoptimaliseerde compressie en retentie policies voor data die als stroom binnenkomt en na verloop van tijd minder relevant wordt. |
KarakteristiekAanbevolen TechnologieWaarom? (Rationale & Context)Gestructureerd, ACID, RelatiesPostgreSQLDe facto open source standaard, enorm ecosysteem, ondersteunt JSON/Vector, geen licentiekosten, uitstekende Kubernetes support.Ongestructureerd, Analytics, ArchiefLakehouse (S3 + Iceberg)**Kostenefficiënt voor grote volumes, scheiding compute/storage (schaalbaarheid), open standaard (geen lock-in), ondersteunt ’time travel’.**Full-text Search, LogsOpenSearch / ElasticsearchBewezen technologie voor tekst en logs, krachtige aggregaties, breed geaccepteerd in de markt.**Semantische Search (RAG)****Vector DB (Weaviate/pgvector)**Noodzakelijk voor AI context retrieval. Pgvector voor eenvoudige cases (geïntegreerd in Postgres), Weaviate/Qdrant voor schaal en hybrid search.**Complexe Netwerken (Fraude)****Graph DB (Neo4j)**Relaties zijn ‘first class citizens’. Performant bij diepe traversals (vriend-van-vriend-van-vriend) waar SQL faalt.**High Frequency Metrics (IoT)****Time-Series (Prometheus/Influx)**Geoptimaliseerde compressie en retentie policies voor data die als stroom binnenkomt en na verloop van tijd minder relevant wordt.
3.3 Search Architectuur: Hybrid Retrieval en Reranking
Voor de publieke sector is standaard vector search vaak onvoldoende. Vector search vindt concepten (bijv. “voertuig”), maar mist vaak exacte termen (bijv. een specifiek kenteken “X-123-YZ”) die cruciaal zijn in dossiers.
-
Design Pattern: Hybrid Search. Combineer een Sparse Retriever (BM25/Keyword) voor exacte matches met een Dense Retriever (Embeddings) voor conceptuele matches. Dit combineert de precisie van trefwoorden met het begrip van context.
-
Reranking: De resultaten van beide retrievers worden samengevoegd en opnieuw gerangschikt door een Cross-Encoder model (Reranker). Dit model bekijkt de specifieke relevantie van elk document voor de zoekvraag. Dit verhoogt de relevantie en precisie drastisch, wat cruciaal is voor juridische zoekvragen waar nuance het verschil maakt.2
-
Governance: Permission-Aware Retrieval is verplicht. De zoekindex moet de ACL’s (Access Control Lists) van het brondocument respecteren. Een gebruiker mag via de zoekmachine of AI nooit een document vinden waar hij in het bronsysteem geen leesrechten op heeft. Dit vereist dat permissies worden meegeïndexeerd of real-time worden gecontroleerd (late binding).
3.4 AI & Agentic Design Patterns
-
RAG (Retrieval Augmented Generation): Het standaardpatroon voor kennisintensieve taken binnen de overheid. Context (wetteksten, beleid) wordt opgehaald uit de vector store en aan de prompt toegevoegd voordat het naar het LLM gaat. Dit ‘grondt’ de AI in feiten en vermindert hallucinaties.
-
Tool Calling (Agentic): AI-modellen krijgen toegang tot vooraf gedefinieerde functies (tools), bijvoorbeeld zoek_wettekst(artikel) of bereken_toeslag(inkomen).
-
Security: Tools mogen nooit ‘side effects’ hebben (zoals schrijven, verwijderen, betalen) zonder expliciete menselijke goedkeuring in de loop (“Human-in-the-loop”).
-
Audit: Elke tool-call moet volledig gelogd worden: wat vroeg de AI, met welke parameters, en wat was het exacte resultaat? Dit is essentieel voor de verantwoording van AI-gedreven handelingen.4
L4: Security, Privacy en Governance by Design
4.1 Threat Modeling en Zero Trust
De beveiligingsarchitectuur gaat uit van de fundamentele aanname dat het netwerk vijandig is (Zero Trust) en dat de perimeter doorbroken kan zijn.
-
Threat Model (STRIDE) voor RAG-pipeline:
-
Spoofing: Kan een aanvaller zich voordoen als een andere gebruiker om data te injecteren of in te zien? -> Mitigatie: Sterke identiteitsverificatie via mTLS en OIDC tokens voor elke call.
-
Tampering: Kan de vector-index of het model ‘vergiftigd’ worden met valse informatie? -> Mitigatie: Cryptografisch ondertekende artifacts (signing), immutable logs en strikte toegangcontrole op de schrijfpijplijn.
-
Repudiation: Kan een AI-actie of zoekopdracht achteraf ontkend worden? -> Mitigatie: Niet-weerlegbare, cryptografisch ondertekende audit logs op een veilige server.
-
Information Disclosure: Hallucineert het model PII of staatsgeheimen? -> Mitigatie: Strikte output filtering, pseudonimisering in de Bronze/Silver laag, en contextuele toegangscontrole.
-
Denial of Service: Kan een complexe vector query de database platleggen? -> Mitigatie: Rate limiting, query timeouts en resource quotas per gebruiker/service.
-
Elevation of Privilege: Kan prompt injection (jailbreak) leiden tot beheersrechten? -> Mitigatie: System prompts als read-only configureren, scheiding van data en instructie in de prompt-architectuur.
4.2 Data Governance en Privacy
-
Classificatie bij de Bron: Alle data moet direct bij creatie geclassificeerd worden volgens het schema: A1 (Openbaar), A2 (Intern), A3 (Vertrouwelijk), A4 (Zeer Vertrouwelijk). Deze metadata moet onlosmakelijk met de data meereizen (bijv. via headers of metadata in Parquet-bestanden).
-
Pseudonimisering: Binnen het Lakehouse wordt data in de Silver-laag standaard gepseudonimiseerd. Direct identificerende gegevens (zoals BSN) worden vervangen door tokens. De vertaaltabel (de sleutel) wordt opgeslagen in een aparte, streng beveiligde ‘kluis’ (Zone 1) met beperkte toegang en strikte auditing.1
-
Retentie en Legal Hold: Data moet automatisch verwijderd worden na verloop van de wettelijke bewaartermijn (Time-To-Live in databases), tenzij er een ‘Legal Hold’ op zit vanwege een lopend juridisch onderzoek of WOO-verzoek. Dit vereist een centrale ‘Policy Engine’ die storage policies over alle systemen afdwingt en vernietiging logt.
4.3 Supply Chain Security (NIS2)
De software supply chain voor databases en AI is een aantrekkelijk doelwit. Een kwetsbaarheid in een veelgebruikte library kan duizenden systemen compromitteren.
-
SBOM (Software Bill of Materials): Voor elke container die gedeployed wordt, moet een actuele en complete SBOM aanwezig zijn. Dit maakt het mogelijk om bij een nieuwe kwetsbaarheid (CVE) direct te zien welke systemen geraakt worden.
-
Artifact Signing: Container images en ML-modellen worden digitaal ondertekend in de CI/CD-pijplijn (bijv. met Sigstore/Cosign). De runtime omgeving (Kubernetes admission controller) is geconfigureerd om het starten van ongetekende of onbekende workloads te weigeren.5
-
Private Registry: Geen directe ‘pulls’ van publieke repositories zoals Docker Hub of Hugging Face. Alle software gaat via een interne proxy/registry waar eerst security scanning en policy checks plaatsvinden.
4.4 AI Governance (EU AI Act)
-
Model Cards: Elk deployed model heeft een verplichte ‘Model Card’ (of Fact Sheet) met een begrijpelijke beschrijving van de training data, de bekende limitaties, resultaten van bias-testen en het beoogde gebruik. Dit document is essentieel voor transparantie en toezicht.
-
Logging (Art. 12): Voor High-Risk AI systemen is zeer uitgebreide logging verplicht. Dit omvat niet alleen de input en output, maar ook de interne metrics (zoals uncertainty scores), de versie van het gebruikte model, en eventuele menselijke interventies of overrides.4 Deze logs moeten beschermd worden tegen wijziging.
L5: Operating Model met Team Topologies
Om deze complexe, hybride architectuur beheersbaar te houden en de cognitieve belasting van teams te beperken, is een strikte organisatievorm nodig gebaseerd op de principes van Team Topologies.
5.1 Team Types en Verantwoordelijkheden
-
Platform Team (Data & AI Platform):
-
Verantwoordelijkheid: Bouwt, beheert en innoveert de onderliggende technische infrastructuur (Kubernetes, Storage, Databases-as-a-Service, Identity, AI-hosting).
-
Product: Een self-service platform (‘Internal Developer Platform’) waarmee andere teams zelfstandig databases en AI-services kunnen uitrollen en beheren, zonder tickets te hoeven inschieten bij beheer.
-
Focus: Stabiliteit, Security-by-Design, Schaalbaarheid en het verlagen van de drempel voor dev-teams.
-
Stream-aligned Teams (Domein Teams):
-
Verantwoordelijkheid: Leveren tastbare waarde voor een specifiek business-domein (bv. “Inkomen”, “Handhaving”, “Dienstverlening”).
-
Rol: Zij ‘huren’ databases en AI-diensten van het platform. Ze zijn volledig eigenaar van de data (schema, kwaliteit, content) en de applicatielogica, maar niet van de database-server (hardware/patching).
-
Focus: Business logica, datakwaliteit, gebruikerservaring en snelheid van levering.
-
Enabling Teams:
-
Rollen: Security Architecten, Privacy Officers, Data Scientists, Agile Coaches.
-
Taak: Zij helpen Stream-aligned teams om nieuwe capabilities te leren en volwassen te worden. Ze voeren geen operationeel werk uit (“we doen het voor je”), maar coachen en faciliteren (“we leren je hoe het moet”) om kennis te borgen in de teams.
-
Complicated Subsystem Teams:
-
Voorbeeld: Een team dat werkt aan een specialistisch, complex cryptografisch algoritme of een zeer complex Knowledge Graph model dat diepe wiskundige expertise vereist die niet in elk team beschikbaar is. Dit team levert dit subsystem als een ‘black box’ aan andere teams.
5.2 Interactiepatronen en Cognitive Load Management
Het primaire doel van dit model is om de cognitieve load van de Stream-aligned teams te verlagen, zodat zij zich kunnen focussen op hun domein. Een ontwikkelaar bij “Dienstverlening” moet zich niet druk hoeven maken over PostgreSQL back-up strategieën, OS-patching of vector-index tuning.
-
X-as-a-Service: Het Platform Team levert databases en infra als een dienst. De interactie verloopt via API’s, self-service portals en goede documentatie, niet via vergaderingen of tickets. Dit schaalt.
-
Golden Paths (Paved Roads): Het platform biedt geprefabriceerde, veilige templates (“Golden Paths”) voor veelvoorkomende use cases (bv. “Python Web App + Postgres + Redis”). Wie het gouden pad volgt, krijgt automatische compliance, monitoring, logging en backups ‘gratis’. Wie van het pad wil afwijken, moet zelf de volledige operationele en compliance-last dragen (“You build it, you run it”).
5.3 RACI Matrix (Data Domein)
Een heldere verdeling van taken voorkomt discussie tijdens incidenten.
| Activiteit | Stream-aligned Team | Platform Team | Security/Privacy Enabling | Data Owner (Business) |
|---|---|---|---|---|
| Schema Design & Datamodel | Responsible | Consulted | I | Accountable |
| DB Patching/Upgrade (OS/Engine) | I | Responsible | I | I |
| Data Kwaliteit & Correctheid | Responsible | I | I | Accountable |
| Backup & Restore (Infrastructuur) | I | Responsible | I | Accountable (stelt RPO/RTO eis) |
| Access Policy Definitie (Wie mag wat) | Responsible | I | Consulted | Accountable |
| Incident Response (Applicatie/Data) | Responsible | Consulted | Consulted | Informed |
| Incident Response (Infrastructuur) | Informed | Responsible | Consulted | Informed |
ActiviteitStream-aligned TeamPlatform TeamSecurity/Privacy EnablingData Owner (Business)Schema Design & DatamodelResponsibleConsultedIAccountableDB Patching/Upgrade (OS/Engine)IResponsibleIIData Kwaliteit & Correctheid****ResponsibleIIAccountableBackup & Restore (Infrastructuur)IResponsibleIAccountable (stelt RPO/RTO eis)Access Policy Definitie (Wie mag wat)****ResponsibleIConsultedAccountableIncident Response (Applicatie/Data)****ResponsibleConsultedConsultedInformedIncident Response (Infrastructuur)****InformedResponsibleConsultedInformed
L6: Use Cases, Architectuur en Governance in de Praktijk
Hieronder werken we 8 concrete use cases uit, specifiek voor de Nederlandse publieke sector.
UC1: Informatievoorziening en Dossierzoeking met Rechtenmodel
-
Scenario: Een zaakbehandelaar zoekt in miljoenen documenten (PDFs, e-mails) naar informatie over een specifiek dossier.
-
Architectuur: Bronsystemen (DMS, FileShares) synchroniseren via CDC naar een pipeline. Documenten worden ge-OCR’d, geclassificeerd en geïndexeerd in een OpenSearch cluster (voor tekst) en Weaviate (voor semantiek).
-
Governance & Security: Cruciaal is Permission-Aware Retrieval. De index bevat ACL-velden (Access Control Lists) die overeenkomen met de AD-groepen van de gebruiker. Tijdens het zoeken filtert de query automatisch resultaten weg waarvoor de gebruiker geen rechten heeft.
-
Ownership: Het ‘Search Platform Team’ beheert de indexer-infra. Het ‘Zaak Domein Team’ is eigenaar van de relevantie-tuning en de frontend.
UC2: Juridische en Beleidsdocumenten Retrieval (Legal RAG)
-
Scenario: Een jurist stelt een vraag (“Wat is het beleid rondom X?”) en krijgt een antwoord met bronverwijzingen.
-
Architectuur: Een RAG-pipeline. Beleidsstukken worden ‘gechunked’ en in een Vector Store geplaatst. Een LLM (on-prem gehost) genereert het antwoord op basis van de gevonden chunks.
-
Governance: Traceability is key. Het antwoord moet voetnoten bevatten die linken naar de originele PDF. Versiebeheer is essentieel: welk beleid was geldig op datum X?
-
Security: Mitigatie van Prompt Injection. De LLM mag geen instructies uit de documenten uitvoeren (“negeer vorige regels”).
UC3: Fraude en Anomaliedetectie met Privacy Waarborgen
-
Scenario: Detecteren van verdachte patronen in aanvragen en betalingen.
-
Architectuur: Data uit diverse bronnen wordt geladen in een Lakehouse (Silver laag, gepseudonimiseerd). Een Graph Database (Neo4j) wordt gebruikt om relaties tussen aanvragers, adressen en rekeningen te analyseren.
-
Governance: Strikte DPIA (Data Protection Impact Assessment). Data-minimalisatie: alleen noodzakelijke velden worden geanalyseerd. Als een hit wordt gevonden, mag de-pseudonimisering alleen plaatsvinden door een geautoriseerde fraude-onderzoeker via een gelogd proces (“break-glass”).
-
Ownership: Een gespecialiseerd ‘Fraude Analyse Team’ (Complicated Subsystem Team).
UC4: Incident Response en Security Analytics (SIEM+)
-
Scenario: Het SOC (Security Operations Center) analyseert logs om een cyberaanval te detecteren.
-
Architectuur: Hoge volumes logdata (firewall, server, applicatie) stromen via Kafka naar een Time-Series DB en OpenSearch. Voor lange termijn opslag (compliance) gaat data naar goedkope Object Storage (Lakehouse).
-
Governance: Immutable Logs. Logs worden geschreven naar ‘WORM’ (Write Once Read Many) storage om te voorkomen dat een aanvaller sporen wist.
-
Security: Forensic Readiness. De architectuur moet het mogelijk maken om snel een snapshot van data te maken voor juridisch bewijs.
UC5: Publieksdienstverlening (KCC Chatbot)
-
Scenario: Een chatbot op de website beantwoordt vragen van burgers over paspoorten of belastingen.
-
Architectuur: Een RAG-oplossing gevoed door een gecureerde kennisbank (‘Gold’ data).
-
Governance: Content Governance. De chatbot mag alleen antwoorden genereren op basis van gevalideerde teksten van de communicatieafdeling, niet op basis van ‘internetkennis’. Er is een redactieproces voor de kennisbank.
-
Security: Output Guardrails. Een tweede, kleiner model controleert het antwoord van de chatbot op PII, toxiciteit of hallucinaties voordat het naar de burger gaat.
UC6: Wet en Regelgeving Impactanalyse (Traceability)
-
Scenario: Beleidsmakers analyseren wat de impact van een wetswijziging is op uitvoeringsprocessen.
-
Architectuur: Een Knowledge Graph waarin wetten, artikelen, beleidsregels en uitvoeringsprocessen aan elkaar zijn gerelateerd.
-
Governance: Versiebeheer van de graaf. Men moet kunnen tijdreizen: “Hoe zag het stelsel eruit in 2023?”.
-
Ownership: Een multidisciplinair team van juristen en data-engineers.
UC7: Ketensamenwerking en Datadeling
-
Scenario: Gegevensuitwisseling tussen Justitie en Zorg in een veiligheidshuis-casus.
-
Architectuur: Federatieve bevraging. Data blijft bij de bron. Via API’s en een Data Contract wordt specifieke data opgevraagd. Identity Federation zorgt voor authenticatie.
-
Governance: Data Contracts. Expliciete afspraken over het formaat, de kwaliteit en de betekenis van de data.
-
Security: Geen massale data-kopieën. Just-in-time toegang op basis van een specifiek dossier.
UC8: AI-Agent Assistenten met Tool Calling
-
Scenario: Een interne AI-assistent die voor een medewerker agenda-afspraken maakt, ruimtes boekt of simpele statussen opzoekt.
-
Architectuur: Een ‘Agentic’ workflow waarbij de LLM via API’s tools aanroept.
-
Governance: Tool Gating. De agent krijgt alleen toegang tot ‘veilige’ API’s (lezen). Voor schrijfacties (boeken, wijzigen) is expliciete bevestiging van de gebruiker nodig.
-
Audit: Elke stap van de agent (“Ik ga nu agenda X bekijken”) wordt gelogd voor analyse bij fouten.
L7: Roadmap en Investment Case
De transformatie naar deze architectuur is geen ‘big bang’, maar een beheerst meerjarenplan.
7.1 Roadmap Fasering
-
Fase 0: Fundering (0-3 maanden)
-
Focus: Identity, Basic Infra & Security Baseline.
-
Deliverables: Operationeel Kubernetes platform on-prem. Werkende, centrale IAM (OIDC/Keycloak). Definitie en publicatie van ‘Golden Path’ voor PostgreSQL. Selectie en installatie S3-storage oplossing.
-
Stop: Moratorium op nieuwe legacy DB installaties en ongecontroleerde cloud-abonnementen.
-
Fase 1: Modernisatie & Lakehouse Pilot (3-9 maanden)
-
Focus: Data ontkoppeling en opschoning.
-
Deliverables: Implementatie MinIO/Ceph clusters. Eerste ‘Bronze/Silver’ pipelines met Delta Lake/Iceberg. Migratie van één niet-kritieke, data-intensieve keten naar het Lakehouse. Formele start Platform Team en Enabling Teams.
-
Fase 2: AI & Vector Scale-up (9-18 maanden)
-
Focus: Intelligentie en Semantiek.
-
Deliverables: On-premise hosting van LLM’s (vLLM/TGI) op GPU-nodes. Vector database integratie in het platform. Eerste RAG-applicatie in productie voor interne kennisdeling (UC1/UC2). Formaliseren AI Governance framework (EU AI Act compliance check).
-
Fase 3: Federatie & Advanced Governance (18-36 maanden)
-
Focus: Ketenbrede schaal en optimalisatie.
-
Deliverables: Federatieve Data Mesh over meerdere overheidsorganisaties heen (data delen bij de bron). Geautomatiseerde WOO-afhandeling ondersteund door AI. Volledige ‘Self-Healing’ capabilities van het platform. Uitfasering laatste legacy systemen.
7.2 Investment Case & FinOps
On-premise AI en Big Data vereisen aanzienlijke CapEx (hardware) investeringen, in tegenstelling tot de OpEx van cloud.
-
Voordeel: Voorspelbare, vlakke kosten. Geen ‘bill shock’ door runaway cloud queries of egress fees. Totale, juridisch afdwingbare controle over data exit en locatie.
-
Kosten Drivers:
-
Hardware: GPU-servers (schaars en duur), snelle NVMe storage voor vector databases.
-
Personeel: Talent (Platform Engineers, Data Engineers, AI specialisten) is de grootste kostenpost en uitdaging.
-
FinOps: Implementeer ‘Showback’ (inzichtelijk maken van kosten per team) om bewustzijn te creëren. Gebruik Kubernetes resource quotas om verspilling tegen te gaan.
-
Exit Strategie: Elke investering moet een expliciete exit-paragraaf hebben. Omdat we bouwen op open standaarden (Kubernetes, Postgres, S3, Iceberg), is de technische lock-in minimaal. Data kan relatief eenvoudig geëxporteerd worden naar elk ander platform dat deze open standaarden ondersteunt.
L8: Annexen en Templates
A.1 One-Page Decision Tree (Tekstuele Weergave)
-
Vraag: Wat is de primaire aard en het doel van de data?
-
Relaties & Transacties (Geld, NAW, Status) -> Ga naar 2.
-
Documenten, Logs, Tijdreeksen, Analytics -> Ga naar 3.
-
Netwerken, Complexe Relaties, Patronen -> Ga naar 4.
-
Transacties (System of Record): Is schema-rigiditeit acceptabel en zijn ACID-garanties vereist?
-
Ja -> PostgreSQL (Default keuze).
-
Nee, extreme wereldwijde schaal nodig (zelden in NL gov) -> Overweeg CockroachDB/TiDB (NewSQL).
-
Analytics/Ongeorganiseerd (System of Insight):
-
Analytische Queries op grote schaal / Archief? -> Lakehouse (Iceberg/Trino op S3).
-
Full-text Search of Logs? -> OpenSearch / Elasticsearch.
-
Semantische Search voor AI/RAG? -> Vector DB (Weaviate/Qdrant) of pgvector (voor kleine scale).
-
Specialistisch:
-
Fraude/Netwerkanalyse/Ondermijning? -> Neo4j (Graph).
-
Sensor Data/IoT/IT-Monitoring? -> Prometheus/InfluxDB (Time-Series).
A.2 Failure Modes en Mitigaties
| Failure Mode | Context | Mitigatie |
|---|---|---|
| Polyglot Chaos | Teams kiezen elke week een nieuwe ‘hippe’ database technologie. | Strikte ‘Service Catalog’. Alleen door het platform ondersteunde DB’s mogen gedeployed worden. Afwijking vereist business case en zelfbeheer. |
| Data Swamp | Lakehouse vult zich met data zonder eigenaar, schema of opschoning. | Data Contracts verplicht stellen bij ingestie. Automatische, onverbiddelijke TTL (Time-To-Live) policies op buckets. |
| Shadow AI | Teams gebruiken ChatGPT publiek met gevoelige data uit frustratie over interne traagheid. | Bied een beter, sneller en veiliger intern alternatief aan (Private LLM). Blokkeer technisch de toegang tot publieke AI-API’s. |
| Vector Amnesia | Vector index en bron data lopen uit de pas (hallucinaties over verouderde data). | Implementeer robuuste CDC-pipelines (Change Data Capture) die updates real-time doorzetten naar de index. |
| Governance Theater | Veel papierwerk en beleid, maar geen technische handhaving. | Policy-as-Code (bijv. OPA). Regels worden afgedwongen in de infrastructuur, niet in Word-documenten. |
Failure ModeContextMitigatie****Polyglot ChaosTeams kiezen elke week een nieuwe ‘hippe’ database technologie.Strikte ‘Service Catalog’. Alleen door het platform ondersteunde DB’s mogen gedeployed worden. Afwijking vereist business case en zelfbeheer.Data SwampLakehouse vult zich met data zonder eigenaar, schema of opschoning.Data Contracts verplicht stellen bij ingestie. Automatische, onverbiddelijke TTL (Time-To-Live) policies op buckets.Shadow AITeams gebruiken ChatGPT publiek met gevoelige data uit frustratie over interne traagheid.Bied een beter, sneller en veiliger intern alternatief aan (Private LLM). Blokkeer technisch de toegang tot publieke AI-API’s.Vector AmnesiaVector index en bron data lopen uit de pas (hallucinaties over verouderde data).Implementeer robuuste CDC-pipelines (Change Data Capture) die updates real-time doorzetten naar de index.Governance TheaterVeel papierwerk en beleid, maar geen technische handhaving.Policy-as-Code (bijv. OPA). Regels worden afgedwongen in de infrastructuur, niet in Word-documenten.
A.3 Checklist voor Architectuur Review (Audit Ready)
-
Classificatie: Is de data geclassificeerd (A1..A4) en is dit technisch zichtbaar?
-
Exit Strategie: Is er een Exit Strategie gedefinieerd en getest (geen propriëtaire formaten)?
-
Identity: Is de Identity Provider (IdP) gekoppeld voor authenticatie (geen lokale users)?
-
Supply Chain: Is er een SBOM aanwezig en zijn de artifacts digitaal ondertekend?
-
Continuïteit: Is de back-up & restore procedure recent getest (RPO/RTO gehaald)?
-
AI Lineage: Is de lineage van trainingsdata en modelversie vastgelegd voor elk AI-model?
-
Search Security: Worden permissies (ACLs) daadwerkelijk gerespecteerd in de zoekresultaten (negative test uitgevoerd)?
-
Logging: Worden logs centraal en onwijzigbaar opgeslagen?
Dit document is opgesteld als leidraad voor strategische besluitvorming binnen de Rijksoverheid en aanverwante publieke organisaties, met inachtneming van de geldende kaders voor soevereiniteit en veiligheid.
Presentatie: Data kwaliteit evolutie public sector
Data kwaliteit evolutie public sector
Presentatie: Data kwaliteit evolutie (companion)
Data kwaliteit evolutie (companion)
Data kwaliteit evolutie public sector Nederland
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.