Een strategisch framework voor Data, AI en capaciteit adoptie.
Executive Summary
Dit artikel presenteert een strategisch framework voor organisaties om systematisch data- en AI-capaciteiten te ontwikkelen die meetbare bedrijfswaarde leveren. Gebaseerd op analyse van technologieën en enterprise architectuurprincipes, bieden we een implementatieaanpak die direct aansluit op bedrijfsdoelstellingen. Organisaties kunnen de bijgevoegde assessmenttool gebruiken om hun huidige status te bepalen en gerichte interventies te identificeren. Succesvolle AI-initiatieven vereisen geïntegreerde governance over vijf capaciteitsdomeinen: data-infrastructuur, modelontwikkeling, implementatieoptimalisatie, orchestratie en applicatielevering. Implementatie dient een gefaseerde aanpak te volgen met duidelijke succesindicatoren gekoppeld aan bedrijfsresultaten in plaats van enkel technische experimenten.
I. Inleiding: De strategische noodzaak van Data, AI en capaciteit
De hedendaagse bedrijfsomgeving wordt gekenmerkt door ongekende niveaus van dynamiek, aangedreven door snelle technologische innovatie en steeds hogere klantverwachtingen. Organisaties in alle sectoren staan onder toenemende druk om niet alleen deze veranderingen bij te houden, maar ze proactief te benutten voor strategisch voordeel. In deze context zijn data en kunstmatige intelligentie (AI) uitgegroeid tot centrale krachten, die evolueren van aspirationele concepten naar onmisbare componenten van succesvolle ondernemingen.
Het vermogen om de kracht van data te benutten voor bruikbare inzichten, gecombineerd met de mogelijkheden van AI om processen te automatiseren, besluitvorming te verbeteren en klantervaringen te personaliseren, is niet langer een kwestie van concurrentiedifferentiatie maar een fundamentele vereiste voor duurzame groei en veerkracht. Voorbij de huidige toepassingen van AI omvat het concept van “toekomstige capaciteiten” de continue verkenning en integratie van opkomende technologieën, zodat organisaties aan de voorhoede van innovatie blijven.
Enterprise architectuur (EA) speelt een cruciale rol bij het begeleiden van organisaties door deze complexe transformatie. Door een gestructureerde aanpak te bieden voor het afstemmen van bedrijfsdoelstellingen op technologiestrategieën, stellen EA-frameworks organisaties in staat om data, AI en toekomstige capaciteiten op een coherente en strategische manier te integreren, waarbij de valkuilen van gefragmenteerde of reactieve implementaties worden vermeden. Deze afstemming zorgt ervoor dat technologie-investeringen direct bijdragen aan bedrijfswaarde en dat het enterprise ecosysteem is ontworpen voor langetermijnaanpasbaarheid en robuustheid.
McKinsey onderzoek wijst uit dat organisaties met geavanceerde AI-capaciteiten 3-15% hogere winstmarges behalen dan sectorgenoten, maar 70% van de AI-initiatieven levert niet de verwachte waarde op. Deze discrepantie komt voornamelijk voort uit een technologie-centrische in plaats van een bedrijfsresultaat-gerichte implementatiestrategie.
Uitdagingen bij data- en AI-implementatie
Organisaties staan voor drie kritieke uitdagingen bij het ontwikkelen van hun data- en AI-capaciteiten:
-
Gefragmenteerd technologielandschap: Moeite met het integreren van verschillende tools over de volledige AI-ontwikkelingscyclus
-
Capaciteit-waarde misalignment: Technische sophisticatie overtreft vaak de bedrijfswaardegroei
-
Implementatievolgorde: Onduidelijkheid over welke capaciteiten prioriteit verdienen in verschillende maturiteitsfasen
Dit artikel biedt een beslissingsframework voor het ontwikkelen van enterprise data- en AI-capaciteiten dat deze uitdagingen aanpakt, door analyse van toonaangevende technologiestacks te combineren met gevestigde maturiteitsmodellen tot een actiegericht stappenplan dat meegroeit met de organisatorische gereedheid.
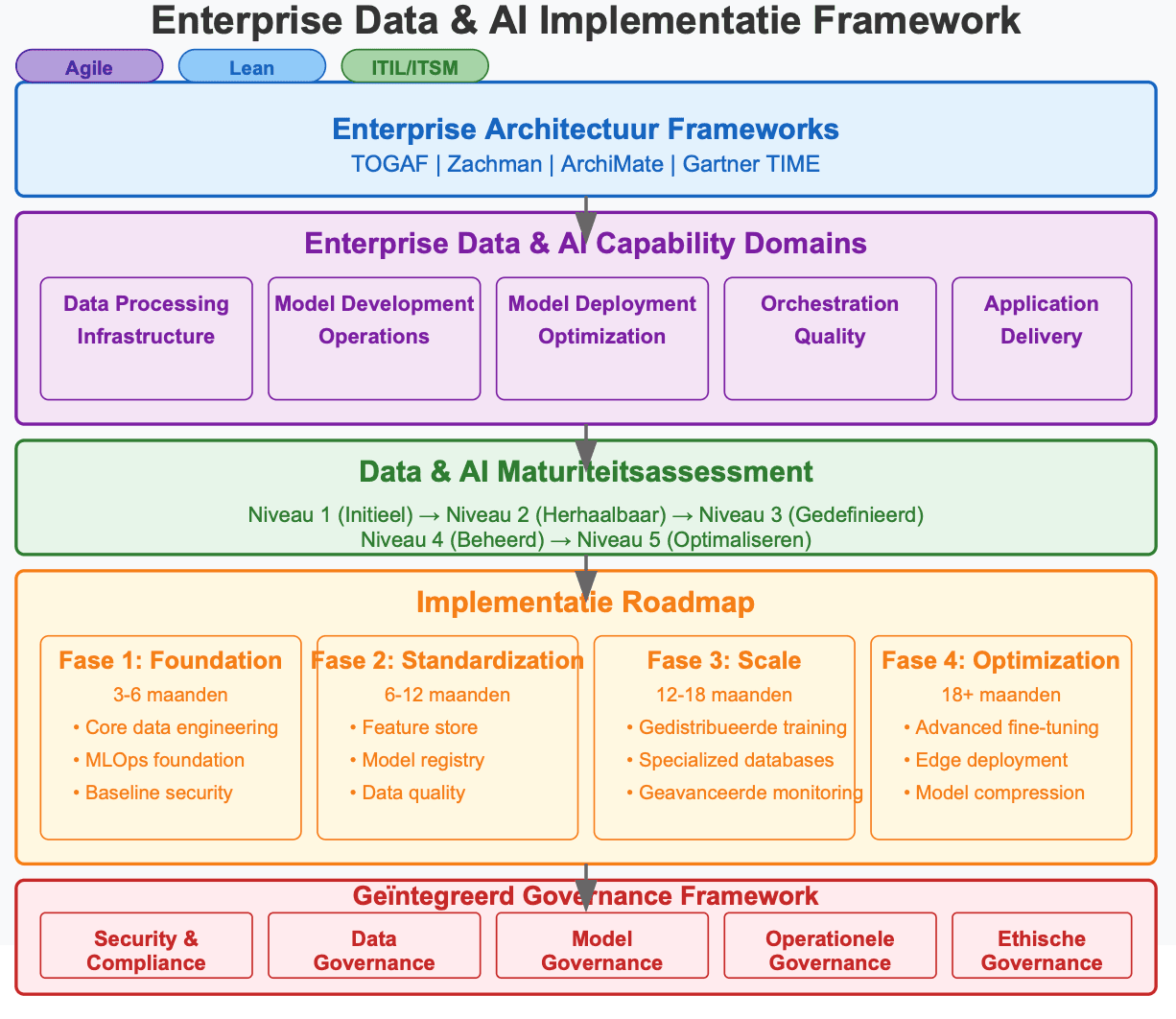
II. Enterprise Architectuur Frameworks voor Data en AI Adoptie
Verschillende enterprise architectuur frameworks bieden gestructureerde benaderingen om organisaties te begeleiden bij de adoptie van data en AI. Tot de meest prominente behoren TOGAF (The Open Group Architecture Framework), het Zachman Framework, ArchiMate en Gartner’s TIME-model.
TOGAF voor AI-implementatie
TOGAF, een breed geadopteerd framework, biedt een uitgebreide methodologie voor het ontwerpen, plannen, implementeren en besturen van IT-architectuur, inclusief data-architectuur. De Architecture Development Method (ADM) biedt een stapsgewijze aanpak die effectief kan worden ingezet om AI-initiatieven gedurende hun volledige levenscyclus te structureren, van initiële visie tot doorlopende governance.
TOGAF faciliteert de creatie van een robuuste data-architectuur die essentieel is voor het ondersteunen van AI-gedreven besluitvorming en de integratie van machine learning-modellen in kernbedrijfsprocessen. De nieuwste iteratie, TOGAF 10, biedt uitgebreide richtlijnen die bijzonder relevant zijn voor het architectureel vormgeven van agentische AI-systemen, die vaak geavanceerde data-architecturen omvatten met vector databases, knowledge graphs en graph databases om redenering en contextueel bewustzijn te verbeteren.
Het Zachman Framework
Het Zachman Framework biedt een ander perspectief door een gestructureerde ontologie aan te reiken voor het definiëren en analyseren van de informatie-infrastructuur van een organisatie. Het gebruikt een 6×6 matrix om architecturale artefacten te categoriseren op basis van verschillende perspectieven (rijen) en aspecten (kolommen), wat een holistische kijk op de onderneming geeft.
Dit framework kan waardevol zijn voor het organiseren van data- en AI-gerelateerde componenten binnen de bredere enterprise architectuur, waarbij afstemming tussen IT-initiatieven en bedrijfsdoelstellingen wordt gewaarborgd. Het Zachman Framework heeft echter bepaalde beperkingen bij het specifiek aanpakken van de unieke uitdagingen van AI-implementatie, waaronder potentiële problemen met interoperabiliteit en integratieconsistentie.
Enterprise Data Architectuur (EDA)
Enterprise Data Architectuur (EDA) dient als essentiële basis voor succesvolle AI-adoptie. EDA biedt de blauwdruk voor het beheren van de data-assets van een organisatie en zorgt ervoor dat ze toegankelijk, betrouwbaar en veilig zijn, allemaal cruciale voorwaarden voor effectieve AI-initiatieven.
Kernelementen van EDA omvatten:
-
Robuuste data governance
-
Uitgebreid data quality management
-
Naadloze data-integratie over verschillende bronnen
-
Stringente data security maatregelen
Een goed gedefinieerde EDA stelt organisaties in staat om hun data-assets maximaal te benutten, waardoor data-gedreven besluitvorming en geavanceerde analysevaardigheden worden ondersteund die de basis vormen van AI-oplossingen. Zonder sterke data-architectuur riskeren organisaties het creëren van “data swamps” met slecht beheerde en ongecontroleerde data, wat de effectiviteit en waarde van AI-implementaties ernstig kan belemmeren.
Vergelijking van Enterprise Architectuur Frameworks
| Framework | Kernfocus | Sterke punten voor Data en AI | Beperkingen voor Data en AI | Primaire use cases |
|---|---|---|---|---|
| TOGAF | Procesgeoriënteerd, gedetailleerde ADM | Structureert AI-initiatieven, faciliteert data-architectuur, TOGAF 10 ondersteunt agentische AI | Kan complex zijn en significante inspanning vereisen | Begeleiding van uitgebreide AI-strategie en implementatie |
| Zachman Framework | Ontologie-gebaseerd, classificatieschema | Organiseert data- en AI-artefacten, holistische benadering | Niet specifiek gericht op AI-uitdagingen (interoperabiliteit, ethiek) | Organiseren en analyseren van enterprise architectuur |
| ArchiMate | Modelleertalaal voor enterprise architectuur | Visualiseert impact van AI op bedrijfsoperaties | Primair een modelleertaal, vereist integratie | Modelleren van AI-technologieën binnen het bedrijfsecosysteem |
| Gartner’s TIME | Strategisch portfoliomanagement | Helpt bij categoriseren van investeringen | Hoog-niveau strategische begeleiding | Strategische planning voor AI-investeringen |
FrameworkKernfocusSterke punten voor Data en AIBeperkingen voor Data en AIPrimaire use casesTOGAFProcesgeoriënteerd, gedetailleerde ADMStructureert AI-initiatieven, faciliteert data-architectuur, TOGAF 10 ondersteunt agentische AIKan complex zijn en significante inspanning vereisenBegeleiding van uitgebreide AI-strategie en implementatieZachman FrameworkOntologie-gebaseerd, classificatieschemaOrganiseert data- en AI-artefacten, holistische benaderingNiet specifiek gericht op AI-uitdagingen (interoperabiliteit, ethiek)Organiseren en analyseren van enterprise architectuurArchiMateModelleertalaal voor enterprise architectuurVisualiseert impact van AI op bedrijfsoperatiesPrimair een modelleertaal, vereist integratieModelleren van AI-technologieën binnen het bedrijfsecosysteemGartner’s TIMEStrategisch portfoliomanagementHelpt bij categoriseren van investeringenHoog-niveau strategische begeleidingStrategische planning voor AI-investeringen
III. Enterprise Data & AI Capability Framework
Op basis van Gartner’s AI Maturiteitsmodel en het DELTA Plus framework (Data, Enterprise, Leadership, Technology, Analytics, People), stellen we een uitgebreid capaciteitsmodel voor over vijf domeinen:
3.1 Kern Capaciteitsdomeinen
-
Data Processing Infrastructure: Fundamentele systemen voor het beheren van gestructureerde en ongestructureerde data op schaal
-
Model Development Operations: Tools en processen voor het creëren, trainen en beheren van modellen
-
Model Deployment Optimization: Systemen voor het operationaliseren en verbeteren van modelprestaties
-
Orchestration Quality: Frameworks voor het coördineren van workflows en verzekeren van outputbetrouwbaarheid
-
Application Delivery: Technologieën voor het leveren van AI-capaciteiten aan eindgebruikers
Elk domein omvat meerdere capaciteiten die parallel maar onderling afhankelijk ontwikkelen.
3.2 Technology Stack Aanbevelingen per Maturiteitsniveau
Data Processing & Infrastructure
| Capaciteit | Beginnende fase (L1-L2) | Groeifase (L3) | Geavanceerde fase (L4-L5) |
|---|---|---|---|
| Batch Processing | PySpark met vereenvoudigde configuraties | PySpark met Ray voor gedistribueerde computing | Ray (Anyscale) met gespecialiseerde computerprofielen |
| Stream Processing | Kafka met basis consumers | Apache Flink met basis state management | Apache Flink met geavanceerde CEP en ML-integratie |
| Feature Store | Handmatig feature management | Feast.dev met basis transformaties | Feast.dev of Tecton met feature backfilling en monitoring |
| Relationele Database | PostgreSQL standalone | PostgreSQL + TimescaleDB | PostgreSQL + TimescaleDB met geautomatiseerde partitionering |
| NoSQL Database | MongoDB voor flexibiliteit | DynamoDB met basis toegangspatronen | DynamoDB met geavanceerde toegangspatronen en GSIs |
| Graph Database | Neo4j standalone | Neo4j met gespecialiseerde modellering | TigerGraph voor large-scale graph analytics |
| Vector Database | Basis vector operaties in PostgreSQL | Weaviate met standaard indexen | Weaviate met hybrid search en custom modules |
| Data Warehouse | Single-region Snowflake | Multi-region Snowflake met governance | Snowflake met custom externe functies en dynamische warehouse sizing |
CapaciteitBeginnende fase (L1-L2)Groeifase (L3)Geavanceerde fase (L4-L5)Batch ProcessingPySpark met vereenvoudigde configuratiesPySpark met Ray voor gedistribueerde computingRay (Anyscale) met gespecialiseerde computerprofielenStream ProcessingKafka met basis consumersApache Flink met basis state managementApache Flink met geavanceerde CEP en ML-integratieFeature StoreHandmatig feature managementFeast.dev met basis transformatiesFeast.dev of Tecton met feature backfilling en monitoringRelationele DatabasePostgreSQL standalonePostgreSQL + TimescaleDBPostgreSQL + TimescaleDB met geautomatiseerde partitioneringNoSQL DatabaseMongoDB voor flexibiliteitDynamoDB met basis toegangspatronenDynamoDB met geavanceerde toegangspatronen en GSIsGraph DatabaseNeo4j standaloneNeo4j met gespecialiseerde modelleringTigerGraph voor large-scale graph analyticsVector DatabaseBasis vector operaties in PostgreSQLWeaviate met standaard indexenWeaviate met hybrid search en custom modulesData WarehouseSingle-region SnowflakeMulti-region Snowflake met governanceSnowflake met custom externe functies en dynamische warehouse sizing
Implementatieprioriteit: Organisaties moeten initieel prioriteit geven aan batch processing en relationele database capaciteiten, en streaming en gespecialiseerde databases toevoegen naarmate use cases rijpen.
Model Development & Operations
| Capaciteit | Beginnende fase (L1-L2) | Groeifase (L3) | Geavanceerde fase (L4-L5) |
|---|---|---|---|
| ML Framework | PyTorch voor standaardtaken | PyTorch met gedistribueerde training | PyTorch met custom CUDA kernels en quantization |
| Traditional ML | Scikit-learn en XGBoost | XGBoost met hyperparameter tuning | XGBoost met geavanceerde feature interaction modellering |
| LLM Foundation | Open-source modellen (LLAMA) | Claude 3.7 Sonnet met basis prompting | Claude 3.7 Sonnet met RAG en tool gebruik |
| Fine-tuning | Basis fine-tuning met HF Transformers | PEFT met LoRA en QLoRA | PEFT met custom architecturen en Axolotl |
| Hyperparameter Tuning | Handmatige grid search | Optuna met Bayesiaanse optimalisatie | Ray Tune met population-based training |
| Experiment Tracking | Basis MLflow tracking | MLflow met artifact management | MLflow met geautomatiseerde evaluatie en vergelijking |
| Model Registry | Version control systemen | MLflow Model Registry | MLflow Model Registry met approval workflows |
| Model API | Flask applicaties | FastAPI met basis validatie | FastAPI met security controls en gateway integratie |
| Inference Server | Direct model serving | TorchServe voor basis modellen | Triton Inference Server met dynamic batching |
| Caching | In-memory application caching | Redis voor embeddings | Redis met gespecialiseerde datastructuren en persistentie |
CapaciteitBeginnende fase (L1-L2)Groeifase (L3)Geavanceerde fase (L4-L5)ML FrameworkPyTorch voor standaardtakenPyTorch met gedistribueerde trainingPyTorch met custom CUDA kernels en quantizationTraditional MLScikit-learn en XGBoostXGBoost met hyperparameter tuningXGBoost met geavanceerde feature interaction modelleringLLM FoundationOpen-source modellen (LLAMA)Claude 3.7 Sonnet met basis promptingClaude 3.7 Sonnet met RAG en tool gebruikFine-tuningBasis fine-tuning met HF TransformersPEFT met LoRA en QLoRAPEFT met custom architecturen en AxolotlHyperparameter TuningHandmatige grid searchOptuna met Bayesiaanse optimalisatieRay Tune met population-based trainingExperiment TrackingBasis MLflow trackingMLflow met artifact managementMLflow met geautomatiseerde evaluatie en vergelijkingModel RegistryVersion control systemenMLflow Model RegistryMLflow Model Registry met approval workflowsModel APIFlask applicatiesFastAPI met basis validatieFastAPI met security controls en gateway integratieInference ServerDirect model servingTorchServe voor basis modellenTriton Inference Server met dynamic batchingCachingIn-memory application cachingRedis voor embeddingsRedis met gespecialiseerde datastructuren en persistentie
Implementatieprioriteit: Focus initieel op ML frameworks, experiment tracking en basis model registry capaciteiten, uitbreidend naar geavanceerde fine-tuning en inference optimalisatie naarmate de schaal toeneemt.
Model Deployment & Optimization
| Capaciteit | Beginnende fase (L1-L2) | Groeifase (L3) | Geavanceerde fase (L4-L5) |
|---|---|---|---|
| Model Serving | Directe deployment | BentoML met containerisatie | BentoML met adaptieve batching |
| Inference Optimization | Basis optimalisatie | ONNX Runtime met standaard optimalisaties | TensorRT met custom optimalisatieprofielen |
| Model Compression | Standaard quantization | DeepSpeed met ZeRO optimalisatie | DeepSpeed met MoE en gespecialiseerde kernels |
| Model Monitoring | Handmatige monitoring | Evidently met basis metrics | Evidently met custom metrics en geautomatiseerde retraining |
| Model Evaluation | Standaard metrics | W&B met custom visualisaties | W&B met geïntegreerde A/B testing |
CapaciteitBeginnende fase (L1-L2)Groeifase (L3)Geavanceerde fase (L4-L5)Model ServingDirecte deploymentBentoML met containerisatieBentoML met adaptieve batchingInference OptimizationBasis optimalisatieONNX Runtime met standaard optimalisatiesTensorRT met custom optimalisatieprofielenModel CompressionStandaard quantizationDeepSpeed met ZeRO optimalisatieDeepSpeed met MoE en gespecialiseerde kernelsModel MonitoringHandmatige monitoringEvidently met basis metricsEvidently met custom metrics en geautomatiseerde retrainingModel EvaluationStandaard metricsW&B met custom visualisatiesW&B met geïntegreerde A/B testing
Implementatieprioriteit: Begin met basis model serving en standaard monitoring, introduceer optimalisatie en compressie wanneer prestatievereisten toenemen.
Orchestration & Quality
CapaciteitBeginnende fase (L1-L2)Groeifase (L3)Geavanceerde fase (L4-L5)ML Pipeline OrchestrationScript-gebaseerde pipelinesApache Airflow met basis DAGsKubeflow Pipelines met hybride uitvoeringJob OrchestrationGeplande takenPrefect met monitoringPrefect met dynamische workflow generatieData QualityBasis unit testsGreat Expectations met standaard suiteGreat Expectations met custom validators en remediationParameter StoreConfiguratiebestandenAWS Parameter StoreHashiCorp Vault met secret rotationMessage QueueBasis Kafka topicsKafka met schema registryKafka met exactly-once semanticsCI/CD for MLHandmatige deploymentGitHub Actions met testingGitHub Actions met canary deployments en promotie
Implementatieprioriteit: Focus initieel op job orchestration en data quality, voeg geavanceerd pipeline management toe wanneer modelcomplexiteit toeneemt.
Deployment & Front-End
CapaciteitBeginnende fase (L1-L2)Groeifase (L3)Geavanceerde fase (L4-L5)Web Front-endReact met standaard componentenNext.js met SSRNext.js met Edge FunctionsMobile Front-endNative appsFlutter voor cross-platformFlutter met platform channelsProgramming LanguagePython voor alle componentenPython met gespecialiseerde librariesPython met Rust voor performancekritische paden
Implementatieprioriteit: Begin met standaard webinterfaces met React, vorder naar Next.js wanneer applicatiecomplexiteit toeneemt.
IV. Maturiteitsbeoordeling voor Data en AI Transformatie
Voordat organisaties beginnen aan de reis van data- en AI-transformatie, is het cruciaal om hun huidige capaciteiten en maturiteitsniveaus op deze gebieden te begrijpen. Deze beoordeling helpt bij het identificeren van bestaande sterktes, het aanwijzen van zwakke punten of hiaten, en het prioriteren van inspanningen voor toekomstige ontwikkeling. Zonder duidelijk begrip van het startpunt riskeren organisaties verkeerde toewijzing van middelen, onrealistische verwachtingen, en uiteindelijk het niet behalen van hun transformatiedoelstellingen.
4.1 Maturiteitsniveaus
Het volgende maturiteitsmodel stelt organisaties in staat hun huidige staat te evalueren en progressiedoelen te definiëren over vijf niveaus:
Niveau 1: Initieel/Ad Hoc
-
Kenmerken: Geïsoleerde proof-of-concepts, beperkte infrastructuur, handmatige processen
-
Bedrijfsimpact: Minimaal, primair gericht op technologie-exploratie
Niveau 2: Herhaalbaar
-
Kenmerken: Gestandaardiseerde datapipelines, basis MLOps, beperkte monitoring
-
Bedrijfsimpact: Geïsoleerde use cases leveren meetbare maar beperkte waarde
Niveau 3: Gedefinieerd
-
Kenmerken: Enterprise dataplatform, geautomatiseerde pipelines, systematische MLOps
-
Bedrijfsimpact: Meerdere bedrijfsonderdelen benutten capaciteiten met consistente resultaten
Niveau 4: Beheerd
-
Kenmerken: Schaalbare infrastructuur, geavanceerde optimalisatie, systematische governance
-
Bedrijfsimpact: Concurrentievoordeel in specifieke domeinen, meetbaar ROI
Niveau 5: Optimaliseren
-
Kenmerken: Zelfverbeterende systemen, edge deployment, hybride mens-AI workflows
-
Bedrijfsimpact: Nieuwe businessmodellen, duurzaam concurrentievoordeel
4.2 Dimensies van maturiteitsbeoordeling
Een uitgebreide maturiteitsbeoordeling moet verschillende belangrijke dimensies overwegen: data maturiteit, AI maturiteit, en organisatorische en culturele maturiteit.
Data Maturiteit
Omvat verschillende aspecten van hoe een organisatie haar data beheert, waaronder:
-
Effectiviteit van data governance en kwaliteitsprocessen
-
Robuustheid van de data-infrastructuur en -architectuur
-
Niveau van data-geletterdheid en -vaardigheden binnen het personeelsbestand
-
Sterkte van data security- en privacymaatregelen
Een veelvoorkomende uitdaging, vooral in de initiële fasen van AI-adoptie, is het gebrek aan relevante, gestructureerde en hoogwaardige data. Veel organisaties worstelen met het effectief benutten van hun eigen data voor AI-gedreven oplossingen, wat de kritieke noodzaak benadrukt om data-maturiteit aan te pakken als fundamentele stap.
AI Maturiteit
Richt zich op:
-
Begrip en bewustzijn van AI-mogelijkheden binnen de organisatie
-
Maturiteitsniveau van bestaande AI-initiatieven
-
Beschikbaarheid van AI-gerelateerde vaardigheden en talent binnen de organisatie
-
Aanwezigheid van ethische overwegingen en governance frameworks voor AI-ontwikkeling en -deployment
Succesvolle AI-adoptie vereist niet alleen technische expertise maar ook een ondersteunende organisatiecultuur die experimenteren en het vermogen om te leren van mislukkingen bevordert. Het cultiveren van zo’n cultuur is essentieel voor het navigeren van de dynamische en vaak onvoorspelbare aard van AI-projecten.
Organisatorische en Culturele Maturiteit
Onderzoekt de bredere context waarbinnen data- en AI-initiatieven zullen worden geïmplementeerd:
-
Niveau van leiderschapstoewijding en visie voor data en AI
-
Prevalentie van een cultuur die experimenteren en leren omarmt
-
Verandermanagementcapaciteiten van de organisatie
-
Mate van samenwerking tussen business- en IT-stakeholders
4.3 Beoordelingsraamwerk
DimensieMaturiteitsniveauKernkenmerkenPotentiële beoordelingsvragen/indicatorenDataInitieelData is versnipperd, inconsistente kwaliteit, beperkte governanceWorden er vaak datakwaliteitsproblemen aangetroffen? Is er een centraal data-governanceorgaan?OntwikkelendEnkele datakwaliteitsinitiatieven, basisgovernance aanwezig, toenemend bewustzijnZijn er gedefinieerde rollen voor data-eigenaarschap? Worden datakwaliteitsmetrieken bijgehouden?GedefinieerdGevestigd data-governanceframework, consistente datakwaliteit, data-integratie-inspanningen gaandeIs er een formele datastrategie? Worden datastandaarden afgedwongen?BeheerdProactieve datakwaliteitsmonitoring, volwassen data-governance, geïntegreerde dataomgevingWordt data strategisch gebruikt voor besluitvorming? Worden data-assets actief beheerd?OptimaliserenData is een strategisch asset, continue datakwaliteitsverbetering, geavanceerde data-analysevaardighedenBenut de organisatie data voor innovatie en concurrentievoordeel?AIInitieelBeperkt bewustzijn van AI, weinig of geen AI-initiatievenZijn er momenteel AI-projecten gaande? Is er begrip van AI’s potentieel?OntwikkelendVerkennende AI-projecten, basis AI-vaardigheden aanwezig, initiële ethische overwegingenZijn er toegewijde AI-resources of teams? Worden ethische implicaties besproken?GedefinieerdGedefinieerde AI-strategie, gevestigde AI-ontwikkelingsprocessen, groeiend AI-talentIs AI afgestemd op bedrijfsdoelstellingen? Zijn er gedefinieerde AI-governancebeleid?BeheerdGeïntegreerde AI-oplossingen, volwassen AI-ontwikkelingslevenscyclus, proactief risicomanagementLevert AI meetbare bedrijfswaarde? Worden AI-modellen continu gemonitord?OptimaliserenAI is kern voor bedrijfsoperaties, continue AI-innovatie, sterk ethisch frameworkIs de organisatie een leider in AI-adoptie binnen haar industrie?Organisatie & CultuurInitieelBeperkte leiderschapsfocus op data/AI, weerstand tegen verandering, geïsoleerde samenwerkingIs er een duidelijke visie voor data en AI van het leiderschap? Is cross-functionele samenwerking gebruikelijk?OntwikkelendGroeiend leiderschapsbewustzijn, enige openheid voor verandering, toenemende samenwerkingWorden data en AI besproken op leiderschapsniveau? Zijn er initiatieven om samenwerking te bevorderen?GedefinieerdSterke leiderschapstoewijding, cultuur van experimenteren ontstaat, gevestigd verandermanagementPromoot leiderschap actief data- en AI-initiatieven? Wordt experimenteren aangemoedigd?BeheerdData-gedreven besluitvorming ingebed, proactief verandermanagement, sterke cross-functionele teamsWorden belangrijke beslissingen geïnformeerd door data- en AI-inzichten? Is de organisatie wendbaar en adaptief?OptimaliserenData en AI zijn centraal in het organisatie-DNA, continue adaptatie, naadloze samenwerkingWordt de organisatie erkend voor haar data- en AI-capaciteiten en -cultuur?
V. Een Gefaseerde Roadmap voor het Operationaliseren van Data, AI en Toekomstige Capaciteiten
Het adopteren van data, AI en toekomstige capaciteiten is een complexe onderneming die een gestructureerde en incrementele benadering vereist. Een gefaseerde implementatiemethodologie biedt verschillende voordelen, waaronder het vermogen om risico’s te beperken, iteratief leren en aanpassing te faciliteren, en betere afstemming met evoluerende bedrijfsbehoeften te waarborgen. Deze benadering contrasteert met een “big bang”-implementatie, die vaak hogere risico’s en lagere slagingskansen met zich meebrengt.
De volgende roadmap biedt een gestructureerde aanpak voor capaciteitsontwikkeling over maturiteitsniveaus:
Fase 1: Foundation (3-6 maanden)
-
Vestig kerndataengineeringcapaciteiten (batch processing met PySpark)
-
Implementeer PostgreSQL en initiële data warehouse (Snowflake)
-
Deploy MLflow voor experiment tracking
-
Creëer gestandaardiseerde modeltrainingsomgeving met PyTorch
-
Implementeer basis CI/CD met GitHub Actions
Succesindicatoren:
-
Datapipeline-betrouwbaarheid (>95% voltooiingspercentage)
-
Modelexperiment-reproduceerbaarheid (100%)
-
Ontwikkeling-naar-deployment tijd (<2 weken)
Fase 2: Standardization (6-12 maanden)
-
Implementeer feature store (Feast.dev)
-
Standaardiseer model registry en versioning
-
Deploy streaming-capaciteiten met Apache Flink
-
Vestig geautomatiseerde kwaliteitscontroles met Great Expectations
-
Implementeer FastAPI voor model serving
Succesindicatoren:
-
Feature-hergebruik over modellen (>30%)
-
Model deployment frequentie (wekelijks)
-
Geautomatiseerde kwaliteitsvalidatiedekking (>80% van datasets)
Fase 3: Scale (12-18 maanden)
-
Implementeer gedistribueerde trainingscapaciteiten
-
Deploy gespecialiseerde databases (vector, graph) voor gerichte use cases
-
Vestig geavanceerde monitoring met Evidently
-
Implementeer modeloptimalisatie met ONNX Runtime
-
Deploy Kubeflow Pipelines voor complexe workflows
Succesindicatoren:
-
Trainingtijdreductie (>50%)
-
Query-latentiereductie (>30%)
-
End-to-end pipeline-automatisering (>90%)
Fase 4: Optimization (18+ maanden)
-
Implementeer geavanceerde fine-tuning-capaciteiten
-
Deploy edge inference-capaciteiten
-
Vestig hybride modelarchitecturen
-
Implementeer geavanceerde modelcompressie
-
Deploy geavanceerde orchestratie met Prefect
Succesindicatoren:
-
Modelgroottereductie (>70%)
-
Inference-latentiereductie (>50%)
-
Resource-utilisatie-efficiëntie (>40% verbetering)
Gedetailleerde stappen en overwegingen per implementatiefase
Fase 1: Foundation, Gedetailleerde stappen
-
Voer een initiële beoordeling uit van de huidige data- en AI-gereedheid
-
Identificeer strategische use cases die direct aansluiten bij bedrijfsdoelstellingen
Vestig een robuuste data-architectuur en de nodige infrastructuur
-
Implementeer PySpark voor batch processing
-
Deploy PostgreSQL voor relationele dataopslag
-
Set up Snowflake voor analytische workloads
Implementeer basis MLOps-platforms
-
MLflow voor experiment tracking
-
Basis model registry met version control
-
Creëer gestandaardiseerde modeltrainingsomgeving met PyTorch
-
Ontwikkel een voorlopig governance-framework
-
Implementeer basis security-maatregelen
Fase 2: Standardization, Gedetailleerde stappen
- Bouw op fase 1-fundamenten met gestandaardiseerde componenten
Implementeer een feature store met Feast.dev
-
Centraliseer feature-definities
-
Enable feature-versioning
-
Faciliteer feature-hergebruik
Standaardiseer model registry en versioning
-
MLflow Model Registry met basisworkflows
-
Traceer volledige modellineage
Deploy streaming-capaciteiten
-
Apache Flink met basic state management
-
Kafka met schema registry
Vestig geautomatiseerde kwaliteitscontroles
-
Great Expectations met standaard validatiesuites
-
Data quality monitoring en alerting
Implementeer API’s voor model serving
-
FastAPI met input validatie
-
Basis security controls
Fase 3: Scale, Gedetailleerde stappen
Implementeer gedistribueerde trainingscapaciteiten
-
PyTorch met distributed training
-
Ray of Horovod voor parallellisatie
Deploy gespecialiseerde databases voor gerichte use cases
-
Weaviate voor vector-gebaseerde zoekoperaties
-
Neo4j voor graph-gebaseerde analyses
Vestig geavanceerde monitoring
-
Evidently met custom metrics
-
Drift-detectie en alarmsystemen
Implementeer model- en inferenceoptimalisatie
-
ONNX Runtime voor cross-framework compatibiliteit
-
TensorRT voor high-performance inference
Deploy geavanceerde orchestratie
-
Kubeflow Pipelines voor end-to-end ML-workflows
-
Geautomatiseerde retraining-pipelines
Fase 4: Optimization, Gedetailleerde stappen
Implementeer geavanceerde fine-tuning-capaciteiten
-
PEFT met LoRA/QLoRA voor efficiënte adaptatie
-
Axolotl voor geavanceerde fine-tuning-workflows
Deploy edge inference-capaciteiten
-
TensorRT voor optimale hardware-utilisatie
-
Modelquantisatie voor resource-efficiëntie
Vestig hybride modelarchitecturen
-
Ensemble-benaderingen voor verhoogde nauwkeurigheid
-
MoE (Mixture of Experts) voor domeinadaptatie
Implementeer geavanceerde modelcompressie
-
DeepSpeed met ZeRO-optimalisaties
-
Kennisdistillatie-technieken
Deploy geavanceerde orchestratie
-
Prefect met dynamische workflow-generatie
-
Event-gedreven architectuur voor real-time aanpassingen
VI. Governance Framework
Succesvolle implementatie vereist robuuste governance over vijf dimensies:
6.1 Security & Compliance
-
Implementeer Zero Trust-principes voor AI-systemen
-
Vestig model risk classificatieframework afgestemd op regulatieve vereisten
-
Implementeer Privacy-by-Design met federated learning waar toepasselijk
-
Deploy continue securityvalidatie over de ML-pipeline
6.2 Data Governance
-
Vestig data quality SLA’s per domein
-
Implementeer geautomatiseerde lineage tracking
-
Deploy toegangscontroles gebaseerd op data-sensitiviteitsclassificatie
-
Vestig dedicated governance voor synthetische en verrijkte datasets
6.3 Model Governance
-
Implementeer modelkaarten die beoogde use cases en beperkingen documenteren
-
Vestig goedkeuringsworkflows gebaseerd op risicoclassificatie
-
Deploy geautomatiseerde biasdetectie en mitigatiewerkstromen
-
Implementeer modelversioning met immutable artifacts
6.4 Operationele Governance
-
Vestig SLA’s voor modelprestaties en beschikbaarheid
-
Implementeer kostenbeheerframeworks voor computeresources
-
Deploy geautomatiseerde resourcescaling gebaseerd op utilisatiepatronen
-
Vestig incidentmanagementprotocollen voor modeldegradatie
6.5 Ethische Governance
-
Implementeer fairness-metrics passend bij het domein
-
Vestig reviewprocessen voor high-stakes beslissingen
-
Deploy transparantiemechanismen voor modelbeslissingen
-
Implementeer gebruikersfeedbackloops voor continue verbetering
VII. Agile en Lean Methodologieën voor Effectieve Data- en AI-Adoptie
Agile en Lean methodologieën bieden waardevolle principes en praktijken die de effectiviteit van data- en AI-adoptie-initiatieven significant kunnen verbeteren. Agile benadrukt iteratieve ontwikkeling, nauwe samenwerking, flexibiliteit in planning, en een focus op het leveren van waarde in korte cycli. Lean richt zich op het maximaliseren van waarde voor klanten terwijl verspilling wordt geminimaliseerd en processen continu worden verbeterd.
Voordelen van Agile voor AI-implementatie
Het toepassen van Agile methodologieën op data- en AI-projecten is bijzonder voordelig vanwege de inherente onzekerheid en de noodzaak voor experimenteren in deze domeinen. De iteratieve aard van Agile stelt teams in staat om te beginnen met basisprototypes, geleidelijk aan features te verbeteren op basis van feedback en leren, en snel aan te passen aan nieuwe inzichten uit data.
Cross-functionele samenwerking tussen data scientists, engineers, en business stakeholders, een kernprincipe van Agile, zorgt ervoor dat diverse perspectieven worden geïntegreerd gedurende het hele ontwikkelingsproces. De “Create, Train, Deploy”-fasen van AI/ML-projecten sluiten goed aan bij Agile’s sprint-gebaseerde aanpak.
In tegenstelling tot de Waterval-methodologie, die een rigide, sequentiële aanpak volgt en over het algemeen niet goed past bij de verkennende aard van data- en AI-projecten, maken Agile’s flexibiliteit en aanpassingsvermogen het een betere fit voor het managen van de complexiteiten en evoluerende vereisten die vaak worden aangetroffen in deze initiatieven.
Lean principes in data- en AI-projecten
Lean-principes kunnen data- en AI-adoptie complementeren door een sterke focus te waarborgen op het leveren van bedrijfswaarde en het elimineren van verspilling in het proces. AI zelf kan worden gezien als een agent van continue optimalisatie, in lijn met Lean’s nadruk op continue verbetering.
Door personeelskennis en feedback gedurende het hele AI-implementatieproces te incorporeren, kunnen organisaties Lean-principes benutten om risico’s te beheersen en personeelsbetrokkenheid te verzekeren. Lean’s focus op het identificeren en elimineren van inefficiënties kan organisaties helpen hun datapipelines en AI-workflows te optimaliseren, waardoor wordt verzekerd dat resources effectief worden gebruikt.
Integratie met de gefaseerde roadmap
Het integreren van Agile en Lean principes binnen de voorgestelde gefaseerde roadmap kan de effectiviteit ervan verbeteren. Bijvoorbeeld, elke fase kan worden benaderd met Agile sprints, wat iteratieve vooruitgang en continue feedback mogelijk maakt. Lean-principes kunnen worden toegepast om knelpunten in datavoorbereiding, modelontwikkeling, en deploymentprocessen te identificeren en elimineren.
Door deze methodologieën in te bedden, kunnen organisaties een cultuur van continue verbetering bevorderen, snel aanpassen aan veranderende omstandigheden, en de waarde die uit hun data- en AI-investeringen wordt verkregen maximaliseren.
VIII. De Rol van IT Service Management bij het Ondersteunen van AI
IT Service Management (ITSM) frameworks, zoals ITIL (Information Technology Infrastructure Library), spelen een cruciale rol bij het waarborgen van effectief beheer en levering van IT-diensten, inclusief die met AI en toekomstige capaciteiten. ITIL biedt een set best practices voor het afstemmen van IT-diensten op bedrijfsbehoeften.
Transformatieve impact van AI op ITSM
AI en automatisering transformeren traditionele IT-processen, verbeteren service delivery, en reduceren handmatige werklast. AI kan worden toegepast op verschillende ITIL-practices, waaronder:
-
Incident management: Automatiseren van detectie en resolutie
-
Problem management: Identificeren van root causes
-
Change management: Beoordelen van risico’s
-
Service desk automatisering: Gebruik van chatbots
-
Knowledge management: Creëren van intelligente kennisbanken
Deze toepassingen van AI kunnen leiden tot verhoogde efficiëntie, gereduceerde kosten, en verbeterde klanttevredenheid.
ITIL 4 en AI-integratie
ITIL 4, de nieuwste versie van het framework, erkent het groeiende belang van AI en machine learning binnen zijn managementpraktijken. Er is een verschuiving naar Experience Level Agreements (XLA’s), die gebruikerstevredenheid prioriteren, en AI kan een rol spelen in het monitoren en verbeteren van de gebruikerservaring door real-time sentimentanalyse en proactieve issue-resolutie.
De principes van ITIL worden ook toegepast buiten traditionele IT naar Enterprise Service Management (ESM), waarbij AI service delivery over verschillende bedrijfsfuncties verder verbetert.
Toekomst van ITSM in een AI-gedreven wereld
Vooruitkijkend zal de toekomst van ITIL in een AI-gedreven wereld waarschijnlijk verdere integratie van AI en automatisering in zijn kernprocessen omvatten. Hoewel ITIL 4 de significantie van AI erkent, moet de huidige begeleiding mogelijk evolueren om meer uitgebreide en handelbare strategieën te bieden voor organisaties die AI volledig willen benutten in hun ITSM-practices.
De sleutel zal zijn om de gevestigde principes van ITIL te balanceren met de nieuwe capaciteiten geboden door AI om te verzekeren dat IT service management relevant en effectief blijft in het snel veranderende technologische landschap.
IX. Het Meten van Succes
Organisaties moeten implementatievoortgang bijhouden over drie dimensies:
9.1 Technische Metrics
-
Infrastructuur-utilisatie-efficiëntie
-
Modelprestatiesstabiliteit
-
Pipeline-betrouwbaarheid en -herstel
-
Systeem-schaalbaarheid onder belasting
9.2 Operationele Metrics
-
Tijd van ontwikkeling naar productie
-
Modelonderhoudsefficiëntie
-
Incident-responstijd
-
Resource-utilisatie-efficiëntie
9.3 Bedrijfsimpact Metrics
-
Omzetimpact van AI-capaciteiten
-
Kostenreductie door automatisering
-
Besluitkwaliteitsverbetering
-
Klantervaring-verbetering
Organisaties moeten baselines vestigen voor elke metriccategorie en verbetering per kwartaal bijhouden.
X. Conclusie: De Weg Voorwaarts
De reis naar geavanceerde data- en AI-capaciteiten is transformatief maar uitdagend. Organisaties moeten:
-
Beginnen met beoordeling: Begrijp huidige capaciteiten over alle domeinen
-
Prioriteren op basis van bedrijfswaarde: Identificeer high-impact use cases om initiële implementatie te drijven
-
Incrementeel bouwen: Volg de maturiteitsgebaseerde roadmap in plaats van te proberen fases over te slaan
-
Continue meten: Vestig duidelijke metrics die technische capaciteiten verbinden met bedrijfsresultaten
-
Governance evolueert: Pas governance-frameworks aan naarmate capaciteiten rijpen
Door deze gestructureerde aanpak te volgen, kunnen organisaties data en AI transformeren van experimentele initiatieven naar kernstrategische capaciteiten die duurzaam concurrentievoordeel leveren.
Referenties
-
Gartner. (2023). AI Maturity Model. Gartner Research.
-
Davenport, T., & Harris, J. (2017). Competing on Analytics: The New Science of Winning. Harvard Business Review Press.
-
Loukides, M., Lorica, B., & Swoyer, S. (2021). Enterprise AI/ML Adoption Patterns. O’Reilly Media.
-
Sculley, D., et al. (2015). Hidden Technical Debt in Machine Learning Systems. Advances in Neural Information Processing Systems.
-
Forrester Research. (2023). The Forrester Wave™: AI Infrastructure, Q2 2023.
-
McKinsey Global Institute. (2023). The State of AI in 2023: Generative AI’s Breakout Year.
-
The Open Group. (2022). TOGAF® Standard, 10th Edition. The Open Group.
-
Zachman, J. (2016). The Zachman Framework for Enterprise Architecture. Zachman International.
-
ITIL. (2019). ITIL 4 Foundation, AXELOS Global Best Practice.
-
Schwaber, K., & Sutherland, J. (2020). The Scrum Guide.
Tabellen uit het originele artikel
Tabel 5
| Capaciteit | Beginnende fase (L1-L2) | Groeifase (L3) | Geavanceerde fase (L4-L5) |
|---|---|---|---|
| ML Pipeline Orchestration | Script-gebaseerde pipelines | Apache Airflow met basis DAGs | Kubeflow Pipelines met hybride uitvoering |
| Job Orchestration | Geplande taken | Prefect met monitoring | Prefect met dynamische workflow generatie |
| Data Quality | Basis unit tests | Great Expectations met standaard suite | Great Expectations met custom validators en remediation |
| Parameter Store | Configuratiebestanden | AWS Parameter Store | HashiCorp Vault met secret rotation |
| Message Queue | Basis Kafka topics | Kafka met schema registry | Kafka met exactly-once semantics |
| CI/CD for ML | Handmatige deployment | GitHub Actions met testing | GitHub Actions met canary deployments en promotie |
Tabel 6
| Capaciteit | Beginnende fase (L1-L2) | Groeifase (L3) | Geavanceerde fase (L4-L5) |
|---|---|---|---|
| Web Front-end | React met standaard componenten | Next.js met SSR | Next.js met Edge Functions |
| Mobile Front-end | Native apps | Flutter voor cross-platform | Flutter met platform channels |
| Programming Language | Python voor alle componenten | Python met gespecialiseerde libraries | Python met Rust voor performancekritische paden |
Tabel 7
| Dimensie | Maturiteitsniveau | Kernkenmerken | Potentiële beoordelingsvragen/indicatoren |
|---|---|---|---|
| Data | Initieel | Data is versnipperd, inconsistente kwaliteit, beperkte governance | Worden er vaak datakwaliteitsproblemen aangetroffen? Is er een centraal data-governanceorgaan? |
| Ontwikkelend | Enkele datakwaliteitsinitiatieven, basisgovernance aanwezig, toenemend bewustzijn | Zijn er gedefinieerde rollen voor data-eigenaarschap? Worden datakwaliteitsmetrieken bijgehouden? | |
| Gedefinieerd | Gevestigd data-governanceframework, consistente datakwaliteit, data-integratie-inspanningen gaande | Is er een formele datastrategie? Worden datastandaarden afgedwongen? | |
| Beheerd | Proactieve datakwaliteitsmonitoring, volwassen data-governance, geïntegreerde dataomgeving | Wordt data strategisch gebruikt voor besluitvorming? Worden data-assets actief beheerd? | |
| Optimaliseren | Data is een strategisch asset, continue datakwaliteitsverbetering, geavanceerde data-analysevaardigheden | Benut de organisatie data voor innovatie en concurrentievoordeel? | |
| AI | Initieel | Beperkt bewustzijn van AI, weinig of geen AI-initiatieven | Zijn er momenteel AI-projecten gaande? Is er begrip van AI’s potentieel? |
| Ontwikkelend | Verkennende AI-projecten, basis AI-vaardigheden aanwezig, initiële ethische overwegingen | Zijn er toegewijde AI-resources of teams? Worden ethische implicaties besproken? | |
| Gedefinieerd | Gedefinieerde AI-strategie, gevestigde AI-ontwikkelingsprocessen, groeiend AI-talent | Is AI afgestemd op bedrijfsdoelstellingen? Zijn er gedefinieerde AI-governancebeleid? | |
| Beheerd | Geïntegreerde AI-oplossingen, volwassen AI-ontwikkelingslevenscyclus, proactief risicomanagement | Levert AI meetbare bedrijfswaarde? Worden AI-modellen continu gemonitord? | |
| Optimaliseren | AI is kern voor bedrijfsoperaties, continue AI-innovatie, sterk ethisch framework | Is de organisatie een leider in AI-adoptie binnen haar industrie? | |
| Organisatie & Cultuur | Initieel | Beperkte leiderschapsfocus op data/AI, weerstand tegen verandering, geïsoleerde samenwerking | Is er een duidelijke visie voor data en AI van het leiderschap? Is cross-functionele samenwerking gebruikelijk? |
| Ontwikkelend | Groeiend leiderschapsbewustzijn, enige openheid voor verandering, toenemende samenwerking | Worden data en AI besproken op leiderschapsniveau? Zijn er initiatieven om samenwerking te bevorderen? | |
| Gedefinieerd | Sterke leiderschapstoewijding, cultuur van experimenteren ontstaat, gevestigd verandermanagement | Promoot leiderschap actief data- en AI-initiatieven? Wordt experimenteren aangemoedigd? | |
| Beheerd | Data-gedreven besluitvorming ingebed, proactief verandermanagement, sterke cross-functionele teams | Worden belangrijke beslissingen geïnformeerd door data- en AI-inzichten? Is de organisatie wendbaar en adaptief? | |
| Optimaliseren | Data en AI zijn centraal in het organisatie-DNA, continue adaptatie, naadloze samenwerking | Wordt de organisatie erkend voor haar data- en AI-capaciteiten en -cultuur? |
Een strategisch framework voor Data, AI en capaciteit adoptie.
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.