From data storage to context architecture
Summary
The enterprise data landscape is currently navigating a structural discontinuity of a magnitude not seen since the advent of the relational database. For the past two decades, the dominant architectural paradigm spanning the Enterprise Data Warehouse (EDW), the Data Lake, and the Lakehouse has been predicated on the storage and processing of information for human consumption. These systems were architected to answer known questions through rigid schemas or to accumulate vast reservoirs of raw data for post-hoc analysis by human analysts. However, the rapid ascendancy of Large Language Models (LLMs) and autonomous AI agentic systems has exposed the fundamental inadequacy of these “storage-first” architectures.
AI systems do not merely require access to data; they require context the semantic, temporal, relational, and governance scaffolding that transforms raw digital signals into meaningful business intelligence. In the absence of this context, probabilistic AI models suffer from hallucination, semantic ambiguity, and “toxic” inference risks. This report presents an exhaustive analysis of the Context Architecture framework, specifically the Deduction-Productisation-Activation model, as the necessary evolution for AI-ready data platforms.
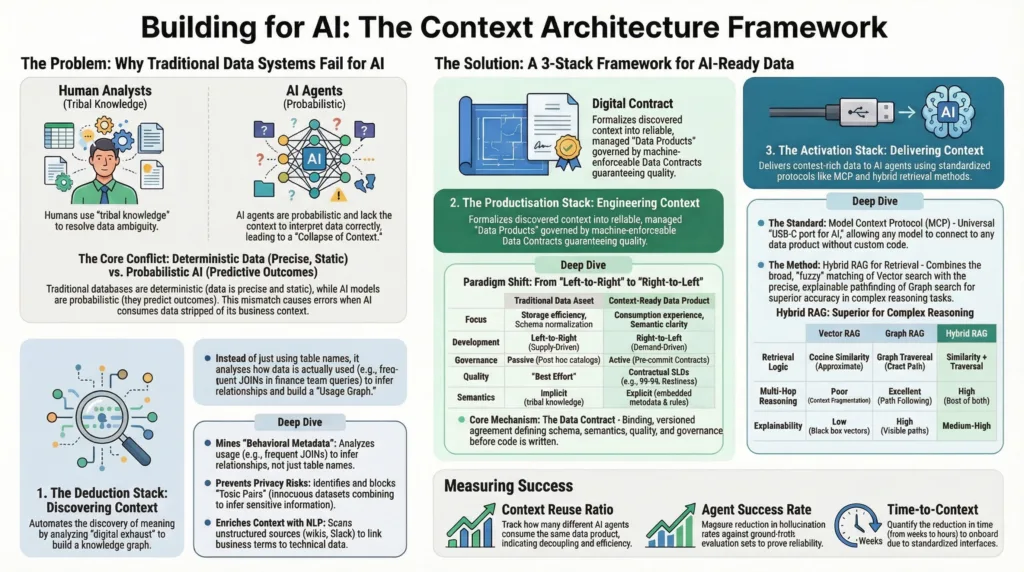
This research synthesizes theoretical foundations from information theory and semantic web research with practical architectural patterns emerging in industry. We explore three critical layers:
-
The Deduction Stack: A mechanism for the automated extraction of semantic context and usage patterns from the “exhaust” of the data ecosystem (query logs, access patterns, behavioral metadata), addressing the scalability limits of manual annotation.
-
The Productisation Stack: The rigorous definition of data as a product through “Right-to-Left” engineering and “Contract-First” development, ensuring that data assets meet the strict reliability standards required by stochastic AI models.
-
The Activation Stack: The delivery of this context to AI agents via standardized interfaces such as the Model Context Protocol (MCP) and Hybrid Retrieval-Augmented Generation (RAG), enabling multi-agent orchestration and dynamic retrieval.
Through a rigorous examination of technical specifications, privacy implications (including the “Toxic Pairs” phenomenon), and comparative benchmarks between Graph and Vector retrieval methods, this report argues that Context Architecture is not merely an optimization of existing infrastructure but a fundamental re-platforming required for the “Agentic Era.”
1. The Theoretical Crisis: The Collapse of Context in the Age of AI
1.1 The Entropic Decay of Meaning in Data Lakes
The history of enterprise data architecture can be viewed as a struggle against entropy. In the era of the Data Warehouse, entropy was managed through high rigidity: schema-on-write, strict normalization (3NF), and heavy governance. While this preserved meaning, it stifled agility and scalability. The reaction to this was the “Big Data” revolution and the advent of the Data Lake, which prioritized volume and velocity over structure.1
The Data Lake introduced the concept of “schema-on-read,” effectively deferring the imposition of meaning until the moment of consumption. For human analysts, this was manageable; they possessed the “tribal knowledge” and cognitive flexibility to interpret a column named amt_1 as “gross revenue” in one context and “net sales” in another. Humans act as the implicit semantic bridge, resolving ambiguity through experience and social communication.
However, non-human agents AI models lack this implicit tribal knowledge. When an LLM retrieves a data point from a lake, it perceives the data through a probabilistic lens, devoid of the historical or social context that grounded the human analyst.1 This phenomenon is the “Collapse of Context.” As data platforms scaled to petabyte ranges, the metadata layer the “data on data” did not scale proportionately. The result is an ecosystem rich in information (bits) but poor in meaning (semantics).
1.2 Deterministic vs. Probabilistic Consumption
The fundamental friction in modern data architecture arises from the mismatch between deterministic storage systems and probabilistic consumers.
-
Deterministic Systems: Databases, Data Warehouses, and APIs are built on binary logic. A query returns a specific row or it does not. The data is static and precise.
-
Probabilistic Consumers: AI Agents and LLMs operate stochastically. They predict the next token based on statistical likelihood. When a probabilistic model consumes deterministic data without explicit semantic guardrails, the risk of “hallucination” increases.2
For example, traditional ETL (Extract, Transform, Load) pipelines often strip away business context during transformation to optimize for storage efficiency. A pipeline might aggregate “Sales” by “Region,” discarding the granular “Customer Interactions” that explain why sales occurred. A human reading a dashboard cares about the aggregate; an AI agent attempting to infer causal relationships for a churn prediction model fails because the causal context has been “optimized” away.2
1.3 Defining Context Architecture
Context Architecture is defined as the discipline of designing and optimizing the information, instructions, and processes that surround an AI model to ensure reliable, measurable results.3 It posits that the value of data for AI lies not in its volume but in its relationships, usage, and constraints.
Unlike traditional architectures that focus on the container (the database, the lake), Context Architecture focuses on the connective tissue. It serves as a meta-layer that sits above the physical storage, orchestrating how meaning is derived (Deduction), packaged (Productisation), and served (Activation) to agents. It transforms the data platform from a passive repository into an active participant in the reasoning process.1
2. The Deduction Stack: The Archeology of Context
The first challenge in building an AI-ready platform is the “Metadata Bottleneck.” Manually annotating petabytes of data with semantic definitions is economically infeasible and prone to human error. The Deduction Stack addresses this by automating the discovery of context. It operates on the theoretical premise that “usage implies meaning” that the way data is queried, joined, and filtered by human experts contains the latent semantic map of the enterprise.4
2.1 Mining Behavioral Metadata and Query Logs
Traditional metadata management relies on “passive” metadata: technical schemas, table names, and column types. The Deduction Stack leverages “active” or “behavioral” metadata the digital exhaust of the data ecosystem.6
2.1.1 Spectral Analysis of Query Logs
Every SQL query executed in an enterprise is a semantic signal. By performing spectral analysis on query logs, the Deduction Stack can reconstruct the implicit relationships between data assets.
-
Co-occurrence Analysis: If Table_A.Column_X and Table_B.Column_Y are frequently used in the JOIN predicates of queries written by the Finance team, the system infers a strong semantic relationship, even if no formal Foreign Key exists.1
-
Filter Similarity: If two disparate datasets are consistently filtered by the same temporal or categorical parameters (e.g., WHERE region = ‘EMEA’), the system deduces they share a common dimension.5
Research into “Workload-Aware” schema matching demonstrates that algorithms trained on query logs can identify joinable tables with significantly higher precision than those relying solely on column name similarity.9 This allows the Deduction Stack to build a “Usage Graph” that prioritizes data based on its actual utility to the business, rather than its theoretical definition.
2.1.2 Graph Theory in Semantic Deduction
The Deduction Stack formalizes these inferred relationships into an enterprise Knowledge Graph.
-
Nodes: Represent data entities (tables, columns), business concepts (Revenue, Churn), and users/teams.
-
Edges: Represent derived relationships (e.g., “Inferred_Join,” “Queried_By,” “Semantically_Similar_To”).
This graph becomes critical for the Activation layer (discussed in Section 4). When an AI agent needs to understand “Customer LTV” (Lifetime Value), it does not just look for a column labeled “LTV.” It traverses the graph to find the data products that the “Risk Team” accesses most frequently, effectively borrowing the subject matter expertise of those users.11 This process, often referred to as Collaborative Filtering for Data, ensures that the AI’s context is grounded in the collective intelligence of the organization.
2.2 Privacy Engineering: The “Toxic Pairs” Phenomenon
One of the most profound risks in the AI era is the ability of models to infer sensitive information from non-sensitive data. The Deduction Stack plays a critical role in identifying and mitigating “Toxic Pairs” or “Toxic Combinations”.1
2.2.1 The Inference Problem and Mosaic Theory
Privacy regulations like GDPR and CCPA protect Personally Identifiable Information (PII). However, AI models, particularly those based on deep learning, excel at Sensitive Data Inference. By combining multiple innocuous datasets, a model can effectively “re-identify” individuals or infer protected attributes (e.g., religion, health status, political affiliation).15
This is known as the Mosaic Effect. A “Toxic Pair” is a specific combination of two or more datasets that, when joined, creates a high probability of sensitive inference.
- Example: Dataset A contains anonymized mobility traces (Time, Location). Dataset B contains public social media check-ins. Individually, they are compliant. Joined, they allow for the precise tracking of an individual’s movements, potentially revealing sensitive visits (e.g., to a medical clinic or place of worship).16
2.2.2 Automated Detection and Inference Control
The Deduction Stack analyzes the potential join paths between data products in the Knowledge Graph. It employs techniques from Differential Privacy to calculate the “privacy budget” or “knowledge gain” of a potential join.18
-
Graph-Based Detection: If the graph shows a path between a “Public” node and a “Sensitive” inference target (via a Toxic Pair edge), the system flags this path.
-
Dynamic Access Control: Unlike static Access Control Lists (ACLs), which block access to specific tables, the Deduction Stack implements Inference Control. It may allow an agent to access Dataset A or Dataset B, but strictly block the simultaneous retrieval of both into the same context window.1 This prevents the “toxic combination” from ever occurring in the model’s working memory.
2.3 Semantic Enrichment via NLP
The Deduction Stack also utilizes Natural Language Processing (NLP) to mine the “unstructured context” surrounding data. It scans wikis, Confluence pages, code comments, and Slack channels to link business vernacular to technical schemas.20
- Context Audit: The system maps the term “ARR” (Annual Recurring Revenue) found in executive presentations to the specific SQL logic used to calculate it in the Data Warehouse.20 This creates a “Semantic Layer” that is not manually curated but algorithmically maintained, ensuring that the context remains fresh as business definitions evolve.
3. The Productisation Stack: The Engineering of Context
While the Deduction Stack discovers context, the Productisation Stack formalizes it. This layer represents the shift from “Data-as-an-Asset” (passive, accumulated) to “Data-as-a-Product” (active, managed, reliable). This transition is non-negotiable for AI because stochastic models require deterministic, reliable inputs to minimize hallucination.
3.1 The “Right-to-Left” Development Paradigm
Traditional data engineering follows a “Left-to-Right” model: Data is extracted from source systems (Left), loaded into a central repository, transformed, and then exposed to consumers (Right).21 This “supply-driven” approach often leads to data swamps where pipelines are built without a clear understanding of the downstream consumption patterns.
Context Architecture advocates for a radical inversion to “Right-to-Left” (or “Demand-Driven”) development.1
-
Define Consumption First (Right): The process begins with the AI agent’s requirements. What is the query pattern? What is the required latency? What is the schema structure (JSON, Graph, Vector)? What is the acceptable error rate?
-
Semantic Modeling: Define the logical data model based on business entities (Customer, Product, Order) rather than source system tables. This model serves as the “contract.”
-
Backward Engineering (Left): Only then is the pipeline engineered to map source data to this contract. This ensures that every data asset has a defined purpose and consumer.21
This approach aligns with Consumer-Driven Contracts (CDC) in software engineering, where the consumer (the AI Agent) defines the expectations that the provider (the Data Platform) must meet.24
3.2 Data Contracts: The API Specification for Data
The mechanism that enforces Right-to-Left development is the Data Contract.26 In the microservices world, APIs are the contract. In the data world, pipelines have historically been brittle because there was no contract; an upstream change in a Salesforce field could silently break a downstream ML model.
A Data Contract is a binding, versioned agreement between the Data Producer and the Data Consumer. It specifies:
-
Schema & Syntax: Field names, data types, and formats (e.g., ISO-8601 dates).
-
Semantics: The business meaning of fields (e.g., “Revenue is recognized on shipping, not ordering”).
-
Service Level Objectives (SLOs):
-
Freshness: “Data updated every 15 minutes.”
-
Completeness: “No more than 0.1% null values in column X.”
-
Accuracy: “Must match the financial ledger within 0.01% variance.”.27
-
Governance: Privacy flags, ownership, and retention policies.
3.2.1 Contract-First Architecture
In a “Contract-First” system, the contract is defined before any ETL code is written.29
-
CI/CD Integration: Data Contracts are integrated into the CI/CD pipeline. If a data producer attempts to push a schema change that violates the contract (e.g., renaming a column used by an AI agent), the deployment is automatically rejected.30
-
Preventing Schema Drift: This mechanism is the only way to guarantee Context Stability for AI agents. An agent relies on stable semantic definitions. If the definition of “churn” changes silently, the agent’s reasoning becomes invalid. Contracts make these definitions explicit and immutable without versioning.26
3.3 Organizational Implications: Domain Ownership
The Productisation Stack inherently requires a shift towards Domain Ownership, a core tenet of the Data Mesh philosophy. Context cannot be engineered by a central IT team that lacks business understanding. The “Marketing Domain” must own the “Campaign Data Product” because they are the only ones who understand the context of a campaign.32
Table 1 illustrates the shift from Traditional Data Assets to Context-Ready Data Products.
| Feature | Traditional Data Asset | Context-Ready Data Product |
|---|---|---|
| Focus | Storage efficiency, Schema normalization | Consumption experience, Semantic clarity |
| Development | Left-to-Right (Supply-Driven) | Right-to-Left (Demand-Driven) |
| Governance | Passive (Post-hoc catalogs) | Active (Pre-commit Contracts) |
| Quality | “Best Effort” | Contractual SLOs (e.g., 99.9% freshness) |
| Semantics | Implicit (tribal knowledge) | Explicit (embedded metadata & rules) |
| Access Interface | SQL Query / ODBC | API, MCP Resource, Vector Embedding |
| Change Mgmt | Ad-hoc, often breaking | Versioned, Contract-driven |
FeatureTraditional Data AssetContext-Ready Data Product****FocusStorage efficiency, Schema normalizationConsumption experience, Semantic clarityDevelopmentLeft-to-Right (Supply-Driven)Right-to-Left (Demand-Driven)GovernancePassive (Post-hoc catalogs)Active (Pre-commit Contracts)Quality“Best Effort”Contractual SLOs (e.g., 99.9% freshness)SemanticsImplicit (tribal knowledge)Explicit (embedded metadata & rules)Access InterfaceSQL Query / ODBCAPI, MCP Resource, Vector EmbeddingChange MgmtAd-hoc, often breakingVersioned, Contract-driven
Table 1: Comparison of Traditional Data Assets vs. Context-Ready Data Products
4. The Activation Stack: The Interface of Intelligence
The Activation Stack is the runtime layer where curated, context-rich data meets the AI agent. It solves the “Last Mile” problem of delivering the right data, in the right format, at the right time. The core technologies driving this layer are the Model Context Protocol (MCP), Retrieval-Augmented Generation (RAG), and Multi-Agent Orchestration.
4.1 The Model Context Protocol (MCP)
The Model Context Protocol (MCP), introduced by Anthropic in late 2024 and rapidly adopted by the industry, is the open standard for connecting AI models to data systems.34 Prior to MCP, connecting an LLM to a database required custom “glue code” for every integration, leading to an $N \times M$ integration complexity problem. MCP standardizes this into a universal protocol, acting as a “USB-C port for AI applications”.37
4.1.1 MCP Architecture and Transport
The MCP specification defines a strict client-host-server architecture 34:
-
MCP Host: The AI application or environment (e.g., Claude Desktop, IDE, Agent Runtime) where the LLM operates.
-
MCP Client: The connector within the host that speaks the protocol. It maintains a 1:1 connection with the server.
-
MCP Server: The external service (The Data Product) that exposes data and capabilities.
-
Transport Layer: MCP utilizes JSON-RPC 2.0 as the transport mechanism. This stateless, lightweight protocol allows for secure, bi-directional message passing. It supports distinct message types:
-
Resources: Passive data reading (e.g., “Read File,” “Fetch Rows”). These are URI-addressable.
-
Tools: Executable functions (e.g., “Run SQL Query,” “Call API”). These allow the agent to perform side effects.
-
Prompts: Pre-defined templates for interaction.39
4.1.2 MCP in the Context Architecture
In this framework, every Data Product created in the Productisation layer is exposed as an MCP Server.40
-
Dynamic Discovery: When an agent connects to the “Finance Data Product” MCP server, it creates a handshake where the server advertises its capabilities (Tools and Resources). The agent “learns” what it can do with the data (e.g., “I can query revenue by region”) without hardcoded logic.41
-
Security & Inference Control: The MCP Server enforces the governance policies defined in the Productisation layer. If a “Toxic Pair” is requested, the MCP Server rejects the JSON-RPC request at the protocol level, preventing the data from ever reaching the model.1
4.2 Retrieval Architectures: Vector vs. Graph RAG
To “activate” context, the system must retrieve the relevant information to feed into the AI’s context window. This is the domain of Retrieval-Augmented Generation (RAG). A critical debate in Context Architecture is the choice between Vector and Graph retrieval.
4.2.1 Vector RAG: The “Fuzzy” Match
Vector RAG converts text into high-dimensional vectors (embeddings) and retrieves data based on cosine similarity.42
-
Strengths: Excellent for unstructured text, highly scalable, handles ambiguous queries and synonyms well.
-
Weaknesses: “Lossy” retrieval. It loses the precise structural relationships between entities. It struggles with “multi-hop” reasoning (e.g., “Who is the CEO of the company that acquired the startup founded by Person X?”). Vector search might find “Person X” and “Startup,” but fail to traverse the acquisition relationship correctly.43
4.2.2 Graph RAG: The “Structured” Path
Graph RAG utilizes the Knowledge Graphs built in the Deduction layer. It retrieves data by traversing explicit edges between nodes.43
-
Strengths: High precision and Explainability. It preserves the “why” of a relationship. It excels at multi-hop reasoning, as the traversal logic perfectly mimics the logical chain of thought.42
-
Weaknesses: Computational complexity in graph construction; requires curated schemas; less tolerant of fuzzy/ambiguous queries.
4.2.3 Benchmarking and the Hybrid Approach
Recent benchmarks, such as GraphRAG-Bench, indicate that Graph RAG significantly outperforms Vector RAG in tasks requiring complex reasoning or evidence aggregation, often by margins of 15-20% in accuracy.44 Specifically, in “multi-hop” scenarios, Vector RAG often suffers from “context fragmentation” retrieving disjointed chunks that the LLM cannot stitch together.
Context Architecture advocates for a Hybrid RAG model.
- Mechanism: The Activation layer uses Vectors to find the “neighborhood” of relevance (semantically similar nodes) and then uses the Graph to navigate the precise “path” of truth within that neighborhood.45 This combines the recall of vectors with the precision of graphs.
| Feature | Vector RAG | Graph RAG | Hybrid RAG |
|---|---|---|---|
| Data Representation | High-dimensional Embeddings | Nodes & Edges (Knowledge Graph) | Embeddings + Graph Structure |
| Retrieval Logic | Cosine Similarity (Approximate) | Graph Traversal (Exact/Path) | Similarity + Traversal |
| Multi-Hop Reasoning | Poor (Context Fragmentation) | Excellent (Path Following) | High (Best of both) |
| Explainability | Low (Black box vectors) | High (Visible paths) | Medium-High |
| Setup Cost | Low (Chunk & Embed) | High (Schema & Extraction) | High |
FeatureVector RAGGraph RAGHybrid RAGData RepresentationHigh-dimensional EmbeddingsNodes & Edges (Knowledge Graph)Embeddings + Graph StructureRetrieval LogicCosine Similarity (Approximate)Graph Traversal (Exact/Path)Similarity + TraversalMulti-Hop ReasoningPoor (Context Fragmentation)Excellent (Path Following)High (Best of both)ExplainabilityLow (Black box vectors)High (Visible paths)Medium-HighSetup CostLow (Chunk & Embed)High (Schema & Extraction)High
Table 2: Comparative Analysis of Retrieval Architectures
4.3 Multi-Agent Orchestration Patterns
The ultimate goal of Activation is to support Multi-Agent Systems (MAS). In these systems, specialized agents (e.g., a “Coder,” a “Researcher,” a “Reviewer”) collaborate to solve complex problems.47
MCP is the enabler of Shared Context in MAS.
-
Pattern 1: The Orchestrator (Lead Agent): A “Lead Agent” receives the user intent. It decomposes the task and assigns sub-tasks to specialized agents. Instead of passing massive text blobs, it passes references (URIs) to MCP Resources. The sub-agents use their own MCP Clients to fetch exactly the data they need from the shared MCP Server.48
-
Pattern 2: The Choreography: Agents communicate directly via Agent-to-Agent (A2A) protocols for coordination, but strictly use MCP for data access. This ensures that all agents are reasoning from the “Single Source of Truth” (the Data Product) rather than hallucinating based on stale memory.38
5. Comparative Architectural Analysis
To understand the novelty of Context Architecture, we must situate it against prevailing paradigms: Data Mesh, Data Fabric, and the Lakehouse.
5.1 Context Architecture vs. Data Mesh
Data Mesh is a socio-technical approach focusing on decentralization and domain ownership.32 It solves the organizational bottleneck of centralized data teams.
-
Intersection: Context Architecture provides the technical implementation for the Data Mesh’s “Data Product” concept. A Data Mesh can exist without being “AI-Ready” (e.g., a mesh of CSV files). Context Architecture enforces the rigor (Contracts, MCP, Semantics) that makes the mesh consumable by machines.2
-
Distinction: Data Mesh is primarily about people and process. Context Architecture is about semantics and protocols.
5.2 Context Architecture vs. Data Fabric
Data Fabric is a technology-centric approach that uses automation and active metadata to weave together disparate data sources.51
-
Intersection: The “Deduction Stack” strongly resembles the active metadata engines of a Data Fabric.
-
Distinction: Data Fabric is often monolithic or platform-centric. Context Architecture is protocol-centric (using MCP). It assumes a heterogeneous environment where data products might live in Snowflake, Databricks, or Postgres, but are unified by the MCP interface rather than a single vendor’s fabric.52
5.3 Context Architecture vs. The Lakehouse
The Lakehouse (e.g., Delta Lake, Iceberg) brings transaction support (ACID) to the Data Lake.
- Distinction: The Lakehouse solves the storage reliability problem (Atomic writes). Context Architecture solves the semantic reliability problem. A Lakehouse is the container; Context Architecture is the content manager. You can build a Context Architecture on top of a Lakehouse, but a Lakehouse alone does not provide the semantic deduction or agentic interfaces required for AI.53
DimensionData MeshData FabricContext ArchitecturePrimary GoalOrg Scalability & AgilityUnified Access & IntegrationAI-Readiness & Agentic ReasoningCore UnitDomain Data ProductMetadata & ConnectorsContext-Ready Product via MCPGovernanceFederated / ComputationalAutomated / CentralizedContract-First & Inference ControlPrimary ConsumerAnalysts / Data ScientistsBusiness Users / ToolsAI Agents / LLMsKey MechanismDecentralizationVirtualization / MetadataDeduction-Productisation-Activation
Table 3: Comparative Analysis of Architectural Frameworks
6. Implementation Strategy: Feasibility and Change Management
Transitioning to a Context Architecture is a high-friction endeavor. It requires not just new technology (Vector DBs, Graph DBs, MCP Servers) but a fundamental rewiring of organizational behavior.
6.1 Cultural Barriers: The “Slow Down to Speed Up” Paradox
The most significant barrier to “Right-to-Left” engineering is cultural.
-
The Friction of Contracts: Domain teams accustomed to “dumping” data into a lake will resist the requirement to define explicit Data Contracts. It introduces friction at the start of the process.33
-
The Paradox: Organizations must be educated that this initial “slowness” prevents the massive “hidden debt” of data cleaning that currently consumes 60-80% of data scientists’ time.2 The “Contract-First” approach shifts the effort from cleaning (reactive) to designing (proactive).
-
Incentive Alignment: Data Producers (e.g., the billing team) are rarely incentivized to provide high-quality context for downstream AI. Management must realign incentives so that “Data Quality” and “Contract Adherence” are KPIs for domain teams, not just data teams.54
6.2 Technical Challenges
-
Complexity of Deduction: Building a reliable “Deduction Engine” that infers meaning from query logs is non-trivial. It requires processing massive logs (petabytes) and handling the “cold start” problem (new data with no usage history).56
-
Latency in Activation: Injecting context via RAG or MCP introduces latency. For real-time agents, the retrieval step must be optimized (e.g., using “warm” context windows or caching frequent graph traversals).
-
Adoption of MCP: While MCP is growing rapidly, it is a nascent standard. Early adopters face the risk of specification changes and limited tooling support compared to established REST APIs.57
6.3 Metrics for Success
Organizations should track specific metrics to validate the architecture’s ROI:
-
Context Reuse Ratio: How many different agents consume the same “Data Product”? High reuse indicates successful semantic decoupling.
-
Agent Success Rate: Measured by specific benchmarks (e.g., “Hallucination Rate” on ground-truth evaluation sets).
-
Toxic Pair Blocking: The number of potentially unsafe inferences detected and blocked by the governance layer.
-
Time-to-Context: The reduction in time required for a new AI agent to be onboarded (from weeks to hours) due to the availability of standardized MCP interfaces.28
7. Future Directions and Research Gaps
7.1 Automated Context Deduction
Current Deduction stacks rely heavily on existing query logs. A major research gap is Unsupervised Context Learning in “greenfield” environments. Can AI agents themselves explore a data warehouse, generating “synthetic queries” to probe relationships, and essentially “write” the metadata back into the Deduction layer? This “Agentic Data Steward” model would close the loop, making the architecture self-healing.
7.2 Dynamic Context Windows
As LLM context windows expand (to 1M+ tokens), the trade-off between RAG (Retrieval) and In-Context Learning (stuffing the whole database in the prompt) shifts.36 Future Context Architectures must implement Dynamic Context Management algorithms that decide in real-time whether to retrieve a specific data point or persist it in the agent’s working memory based on access frequency and relevance decay.
7.3 Multi-Modal Context
The current framework focuses on text and structured data. Future iterations must handle Multi-Modal Context images, video, and audio. Defining “Data Contracts” for video streams (e.g., semantic tagging of frames) and building “Deduction” engines for visual data remain open research challenges.
8. Conclusion
The transition from “Data Storage” to “Context Architecture” represents the maturation of the AI data stack. It acknowledges that for AI to be truly “Agentic” to act with autonomy, reasoning, and reliability it requires more than just access to bytes; it requires a high-fidelity map of meaning.
By implementing the Deduction Stack, organizations can mine the tacit knowledge embedded in their legacy systems. Through the Productisation Stack, they can harden this knowledge into reliable, contract-governed assets using “Right-to-Left” engineering. And via the Activation Stack, using protocols like MCP and Hybrid RAG, they can empower a new generation of multi-agent systems to reason, act, and create value safely.
The “Context Architecture” is not just a technical specification; it is the blueprint for the intelligent enterprise. It shifts the value proposition of the data team from “moving data” to “managing context,” positioning them as the indispensable architects of the AI’s reality.
Geciteerd werk
-
Rise of The Context Architecture: Where Meta is More Vital Than Information, Medium, geopend op december 9, 2025, https://medium.com/@community_md101/rise-of-the-context-architecture-where-meta-is-more-vital-than-information-9e9d7ebb2056
-
AI-Ready Data: A Technical Assessment. The Fuel and the Friction., Medium, geopend op december 9, 2025, https://medium.com/@community_md101/ai-ready-data-a-technical-assessment-the-fuel-and-the-friction-c17ce0941f9b
-
Context Architecture: The Foundation of Enterprise AI Systems …, geopend op december 9, 2025, https://alpineintelligence.ch/context-architecture-the-foundation-of-enterprise-ai-systems/
-
US9256422B2, Systems and methods for finding project-related information by clustering applications into related concept categories, Google Patents, geopend op december 9, 2025, https://patents.google.com/patent/US9256422B2/en
-
Examining Usage Protocols for Service Discovery, ResearchGate, geopend op december 9, 2025, https://www.researchgate.net/publication/221050230_Examining_Usage_Protocols_for_Service_Discovery
-
Active Metadata: Powering the Next Generation of Data Intelligence, Fresh Gravity, geopend op december 9, 2025, https://www.freshgravity.com/blogs/active-metadata-powering-the-next-gen-of-data-intelligence/
-
Metadata Management: Build a Framework that Fuels Data Value, Alation, geopend op december 9, 2025, https://www.alation.com/blog/metadata-management-framework/
-
OmniMatch: Joinability Discovery in Data Products, VLDB Endowment, geopend op december 9, 2025, https://www.vldb.org/pvldb/vol18/p4588-koutras.pdf
-
Redbench: Workload Synthesis From Cloud Traces, arXiv, geopend op december 9, 2025, https://arxiv.org/html/2511.13059v1
-
Workload-Aware Query Recommendation Using Deep Learning, OpenProceedings.org, geopend op december 9, 2025, https://openproceedings.org/2023/conf/edbt/paper-173.pdf
-
A Case for Usage Tracking to Relate Digital Objects, Google Research, geopend op december 9, 2025, https://research.google.com/pubs/archive/33381.pdf
-
Populating a Graph Database to Run a Usage- Based Discovery Tool, geopend op december 9, 2025, https://ntrs.nasa.gov/api/citations/20210024652/downloads/2021_423_Inverso_poster_final_Populating%20a%20Graph%20Database%20to%20Run%20a%20Usage%20Based%20Discovery%20Tool.pdf
-
AI Inventory: Map AI Systems, Data, and Risk, Wiz, geopend op december 9, 2025, https://www.wiz.io/academy/ai-security/ai-inventory
-
DSPM for AI: Navigating Data and AI Compliance Regulations, Palo Alto Networks, geopend op december 9, 2025, https://www.paloaltonetworks.com/cyberpedia/dspm-data-ai-compliance
-
Colorado Privacy Act Regulations, geopend op december 9, 2025, https://privacy.gtlaw.com/cpa-regulations/
-
A First Look at the Colorado Privacy Act Proposed Rules | Davis Wright Tremaine, geopend op december 9, 2025, https://www.dwt.com/blogs/privacy-security-law-blog/2022/10/colorado-privacy-act-proposed-rules-data-privacy
-
Hidden Data Combinations and Facing the Challenge of CCPA, TDWI, geopend op december 9, 2025, https://tdwi.org/articles/2020/03/20/diq-all-hidden-data-combinations-and-ccpa.aspx
-
Sensitive Data and Database Inference, Phoenix!, geopend op december 9, 2025, https://phoenix.goucher.edu/~kelliher/s2010/cs325/apr14.html
-
Privacy Risks and Preservation Methods in Explainable Artificial Intelligence: A Scoping Review, arXiv, geopend op december 9, 2025, https://arxiv.org/html/2505.02828v2
-
Context Engineering: The Foundation Your AI Team Actually Needs …, geopend op december 9, 2025, https://www.fylle.ai/ai/context-engineering-the-foundation-your-ai-team-actually-needs/
-
Model-Driven Data Delivery | Oct, 2025 | Medium, geopend op december 9, 2025, https://medium.com/@jacovanderlaan/model-driven-data-delivery-a437f4b22322
-
Data Modelling Best Practices to Support AI Initiatives at Scale | Modern Data Blog, geopend op december 9, 2025, https://www.moderndata101.com/blogs/data-modelling-best-practices-to-support-ai-initiatives-at-scale
-
How a Data Product Strategy Impacts Business and Tech Teams, geopend op december 9, 2025, https://www.themoderndatacompany.com/blog/how-a-data-product-strategy-impacts-both-business-and-tech-stakeholders
-
Fundamentals of Software Engineering: From Coder to Engineer 1, DOKUMEN.PUB, geopend op december 9, 2025, https://dokumen.pub/fundamentals-of-software-engineering-from-coder-to-engineer-1.html
-
Practical Data Science with Python 3 978-1-4842-4859-1, dokumen.pub, geopend op december 9, 2025, https://dokumen.pub/practical-data-science-with-python-3-978-1-4842-4859-1.html
-
Model as a Data Contract: The Contract-First System Behind Dynamic Semantics, Medium, geopend op december 9, 2025, https://medium.com/@community_md101/model-as-a-data-contract-the-contract-first-system-behind-dynamic-semantics-de31aae1b8c6
-
Data Contracts Are Exploding In 2025 What They Are, Why They Matter, And How To Use Them (With Examples + Tools), PW Skills, geopend op december 9, 2025, https://pwskills.com/blog/data-contracts/
-
Metrics for Measuring Data Product Success, Orchestra, geopend op december 9, 2025, https://www.getorchestra.io/guides/metrics-for-measuring-data-product-success
-
Data Contracts: The Cornerstone of Modern Data Stack Architecture | by Manojit Saha, geopend op december 9, 2025, https://medium.com/@manojit.saha/data-contracts-the-cornerstone-of-modern-data-stack-architecture-eed3b9655b7e
-
Data Contract First Governance | Webinar, Corinium Global Intelligence, geopend op december 9, 2025, https://www.coriniumintelligence.com/contract-first-governance
-
Data Contracts in Action: Tools | by Peter Flook | Sep, 2024 | Data Engineer Things, geopend op december 9, 2025, https://blog.dataengineerthings.org/data-contracts-in-action-tools-303bc7fbceb5
-
Data Mesh: A Paradigm Shift in Managing Data at Scale, Decube, geopend op december 9, 2025, https://www.decube.io/post/data-mesh-data-management
-
Data Product Marketplace | Quantyca, geopend op december 9, 2025, https://www.quantyca.it/en/usecase/data-product-marketplace/
-
What is Model Context Protocol (MCP)? A guide, Google Cloud, geopend op december 9, 2025, https://cloud.google.com/discover/what-is-model-context-protocol
-
Introducing the Model Context Protocol, Anthropic, geopend op december 9, 2025, https://www.anthropic.com/news/model-context-protocol
-
Context is Everything: The Massive Shift Making AI Actually Work in the Real World, geopend op december 9, 2025, https://www.philmora.com/the-big-picture/context-is-everything-the-massive-shift-making-ai-actually-work-in-the-real-world
-
Model Context Protocol, geopend op december 9, 2025, https://modelcontextprotocol.io/
-
Agentic AI: Model Context Protocol, A2A, and automation’s future, Dynatrace, geopend op december 9, 2025, https://www.dynatrace.com/news/blog/agentic-ai-how-mcp-and-ai-agents-drive-the-latest-automation-revolution/
-
What is Model Context Protocol (MCP)?, IBM, geopend op december 9, 2025, https://www.ibm.com/think/topics/model-context-protocol
-
Daloopa expands financial data Model Context Protocol (MCP) through a new connector with OpenAI, geopend op december 9, 2025, https://www.prnewswire.com/news-releases/daloopa-expands-financial-data-model-context-protocol-mcp-through-a-new-connector-with-openai-302636805.html
-
Open Protocols for Agent Interoperability Part 1: Inter-Agent Communication on MCP, AWS, geopend op december 9, 2025, https://aws.amazon.com/blogs/opensource/open-protocols-for-agent-interoperability-part-1-inter-agent-communication-on-mcp/
-
Graph RAG vs Vector RAG: Solving Gartner’s Challenges, FalkorDB, geopend op december 9, 2025, https://www.falkordb.com/blog/graph-rag-vs-vector-rag-solving-gartner-challenges/
-
geopend op december 9, 2025, https://www.chitika.com/graph-rag-vs-vector-rag/#:~:text=Graph%20RAG%20offers%20transparency%20by,outcomes%2C%20hybrid%20systems%20are%20emerging.
-
GraphRAG-Bench: Challenging Domain-Specific Reasoning for Evaluating Graph Retrieval-Augmented Generation, arXiv, geopend op december 9, 2025, https://arxiv.org/html/2506.02404v1
-
What Really Matters to Better GraphRAG Implementation? Part 1 | by Fanghua (Joshua) Yu, Medium, geopend op december 9, 2025, https://medium.com/@yu-joshua/what-really-matters-to-better-graphrag-implementation-part-1-e02fff773c48
-
Benchmarking Vector, Graph and Hybrid Retrieval Augmented Generation (RAG) Pipelines for Open Radio Access Networks (ORAN), arXiv, geopend op december 9, 2025, https://arxiv.org/html/2507.03608v1
-
The Model Context Protocol (MCP): A New Standard for Multi-Agent Intelligence in AI Systems | by Harun Raseed Basheer | Medium, geopend op december 9, 2025, https://medium.com/@harun.raseed093/the-model-context-protocol-mcp-a-new-standard-for-multi-agent-intelligence-in-ai-systems-98541a236d4d
-
Building Scalable AI Agents: Design Patterns With Agent Engine On Google Cloud, geopend op december 9, 2025, https://cloud.google.com/blog/topics/partners/building-scalable-ai-agents-design-patterns-with-agent-engine-on-google-cloud
-
Implementing Multi-Agent Systems with MCP: AI Architect Guide | Blog, Codiste, geopend op december 9, 2025, https://www.codiste.com/multi-agent-ai-systems-mcp-implementation
-
Agentic MCP and A2A Architecture: A Comprehensive Guide | by Anil Jain | AI / ML Architect, geopend op december 9, 2025, https://medium.com/@anil.jain.baba/agentic-mcp-and-a2a-architecture-a-comprehensive-guide-0ddf4359e152
-
Shared Data Experience (SDX), Cloudera, geopend op december 9, 2025, https://www.cloudera.com/products/cloudera-data-platform/sdx.html
-
(PDF) An Overarching Guide to Data Governance, ResearchGate, geopend op december 9, 2025, https://www.researchgate.net/publication/380143909_An_Overarching_Guide_to_Data_Governance
-
How to Build Data Products Develop: Part 2/4 | by Modern Data 101 | Medium, geopend op december 9, 2025, https://medium.com/@community_md101/how-to-build-data-products-develop-part-2-4-73946ecb4f84
-
Breaking Down Data Silos: Essential Considerations, Gable.ai, geopend op december 9, 2025, https://www.gable.ai/blog/breaking-down-data-silos
-
Approaches to Data as a Business Discipline for AI, geopend op december 9, 2025, https://research.isg-one.com/analyst-perspectives/approaches-to-data-as-a-business-discipline-for-ai
-
Graph Data Science, TigerGraph, geopend op december 9, 2025, https://www.tigergraph.com/glossary/graph-data-science/
-
Model Context Protocol, Wikipedia, geopend op december 9, 2025, https://en.wikipedia.org/wiki/Model_Context_Protocol
-
Data Products: A Case Against Medallion Architecture | by Modern Data 101 | Medium, geopend op december 9, 2025, https://medium.com/@community_md101/data-products-a-case-against-medallion-architecture-139096ceea08
-
Writing models backwards: An unorthodox approach to data transformation, #7 by gal_polak, Show and Tell, dbt Community Forum, geopend op december 9, 2025, https://discourse.getdbt.com/t/writing-models-backwards-an-unorthodox-approach-to-data-transformation/2287/7
-
Improving Code Search Using Learning-to-Rank and Query Reformulation Techniques, SEAL, geopend op december 9, 2025, https://seal-queensu.github.io/publications/pdf/Niu_Haoran_201507_MASC.pdf
-
A Semantic Perspective on Query Log Analysis, CEUR-WS.org, geopend op december 9, 2025, https://ceur-ws.org/Vol-1175/CLEF2009wn-LogCLEF-HofmannEt2009.pdf
-
VectorRAG vs. GraphRAG: a convincing comparison, Lettria, geopend op december 9, 2025, https://www.lettria.com/blogpost/vectorrag-vs-graphrag-a-convincing-comparison
-
GraphRAG-Bench: Evaluating Graph Retrieval Models, Emergent Mind, geopend op december 9, 2025, https://www.emergentmind.com/topics/graphrag-bench
| Dimension | Data Mesh | Data Fabric | Context Architecture |
|---|---|---|---|
| Primary Goal | Org Scalability & Agility | Unified Access & Integration | AI-Readiness & Agentic Reasoning |
| Core Unit | Domain Data Product | Metadata & Connectors | Context-Ready Product via MCP |
| Governance | Federated / Computational | Automated / Centralized | Contract-First & Inference Control |
| Primary Consumer | Analysts / Data Scientists | Business Users / Tools | AI Agents / LLMs |
| Key Mechanism | Decentralization | Virtualization / Metadata | Deduction-Productisation-Activation |
Presentatie: From data storage to context architecture
From data storage to context architecture
From data storage to context architecture
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.