From human centric to agent native web search
An Architectural, Economic, and Security Analysis of the New Information Fabric
Section 01: Executive Summary: 15 Key Insights
This report provides an exhaustive analysis of the ongoing, fundamental transformation of web search. It details the paradigm shift from a human-centric, ad-click-driven infrastructure (1998-2025) to an AI-native, agent-centric, and API-driven global information fabric. The analysis integrates technical architecture, economic modeling, advanced security threats, and regulatory governance to provide a holistic, forward-looking assessment for leaders, architects, and policymakers.
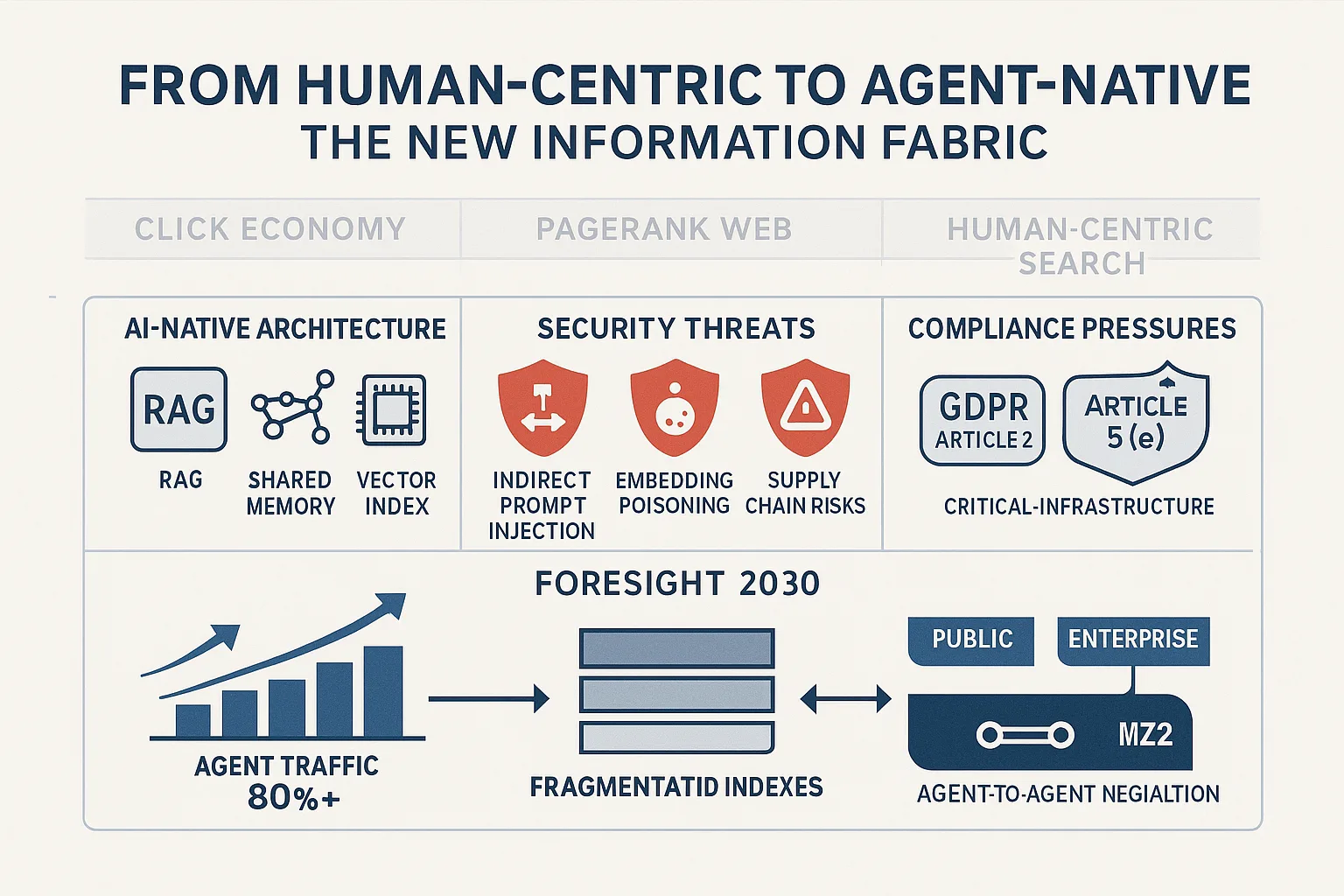
The 15 key strategic findings of this analysis are as follows:
-
The End of the Click Economy: The “zero-click” paradigm, driven by AI-generated answers, is causing a “traffic loss of catastrophic proportions” 1 and the collapse of the traditional ad-based, click-through-rate (CTR) monetization model that defined the web for 25 years.1
-
The New 10x Cost-to-Serve: The new economic driver is the “high cost-to-serve” of generative AI.2 An AI-powered search query is estimated to be up to 10x more costly than a standard keyword search, shifting the entire economic basis from capturing human attention to managing GPU compute costs.2
-
The Re-definition of “Search”: The core problem of search is no longer “ranking URLs for humans to click” (the Google model). It is now “optimizing context and tokens for models to reason over”.4 The key asset is no longer the URL, but the “information-dense excerpt”.4
-
Market Validation via Vertical Lock-in: Microsoft’s strategic deprecation of the general-purpose Bing Search API (retiring August 2025) 5 and the forced migration of users to the ecosystem-locked “Grounding with Bing Search as part of Azure AI Agents” 5 is the clearest market signal of this irreversible pivot to a vertically integrated, agent-native value chain.
-
A New Foundational Architecture: Shared Memory: Scalable multi-agent systems are architecturally impossible without “memory engineering”.7 A “shared persistent memory system” or “computational exocortex” 7, an external, stateful database for all agents, has emerged as a critical, non-negotiable component for preventing work duplication and inconsistent states.8
-
The Primary Systemic Risk: Model Collapse: The single greatest long-term threat to the entire AI ecosystem is “recursive web inflation.” As AI floods the web with synthetic content 10, AI-native crawlers will index it. Future models trained on this contaminated data will suffer “model collapse,” a phenomenon where the model forgets rare, human “tail data” and degenerates.11
-
The Core Operational Tension: Drift vs. Freshness: AI-native stacks are in a state of constant instability, balancing LLM model drift (the model’s reasoning changes) 14 against index freshness (the world’s facts change). This “context drift” 15 creates a high-stakes, co-dependent conflict between MLOps and DataOps.
-
The Primary Security Threat: Indirect Prompt Injection: The attack surface has shifted from the application to the data. The dominant threat is now OWASP LLM01: Indirect Prompt Injection 16, where an attacker plants a malicious payload on an ordinary webpage, which is then retrieved by an agent’s RAG pipeline and executed by the LLM, leading to data exfiltration or manipulation.17
-
The Advanced Supply Chain Attack: Embedding Poisoning: A new, highly effective (96.43% success rate) 19 supply chain attack, Search-based Embedding Poisoning (SEP), has been demonstrated. It injects “imperceptible perturbations” directly into the embedding layer, bypassing safety alignment mechanisms at the model-deployment phase.20
-
The Only Viable Defense: Zero Trust: Perimeter security is obsolete. The only defensible model is a Zero Trust Architecture (NIST SP 800-207) 22 applied to the RAG pipeline. This framework assumes all retrieved content is malicious and requires continuous verification of every agent action and immutable data provenance for every generated answer.23
-
The Fundamental Governance Conflict (GDPR): Agentic AI is on a direct collision course with EU law. Agent persistent memory 25 architecturally conflicts with GDPR Article 5(e) (storage limitation) 26, and agent autonomy conflicts with Article 22 (automated decision-making) 26, which mandates a right to “human intervention”.28
-
The New Regulatory Burden (NIS2): The EU’s NIS2 Directive explicitly re-classifies “online search engines” as “operators of essential services”.29 This makes AI-native search providers critical infrastructure, legally mandating stringent supply chain security (e.g., against SEP) and 24-hour “early warning” incident reporting.29
-
The New Evaluation Standard: Agentic Persistence: Classical IR metrics (e.g., nDCG@10) 32 are obsolete. The new standard is exemplified by the BrowseComp benchmark 33, which measures agentic persistence, “strategic perseverance” 34, and the ability to assemble fragmented clues over “multi-step internet browsing”.33
-
Foresight 2030 (The Web): An Agent-Centric Fabric: By 2030, non-human (agent) traffic is projected to exceed 80%.35 The web will no longer be a visual, human-centric medium but an API-driven, machine-readable fabric.36
-
Foresight 2030 (The Stack): A Fragmented, Negotiated Fabric: The “one web index” model will fragment due to cost and security pressures, leading to a new ecosystem of public, enterprise 38, and sovereign indexes. This will necessitate a new “agent-to-agent (A2A) negotiation layer” 40 built on open standards 41 to act as the global information fabric.
Section 02: Historical Context: The PageRank-Centric Web (1996-2025)
To comprehend the magnitude of the current architectural and economic transformation, one must first deconstruct the foundational paradigm that governed the web for its first 25 years. This was the human-centric era, defined and dominated by a single, revolutionary algorithm: PageRank.
The Pre-Google Era (1993-1998): The Problem of Discovery
The nascent web of the early 1990s was a disconnected repository of files. The primary challenge was not quality but discovery. The first generation of “search engines” were simple tools built to address this. Archie (1990), the very first, was not a web crawler but an index of FTP file listings.42 It was followed by directory-based tools like Veronica 42 and, most famously, Yahoo! (1994).44 Yahoo! was initially a human-curated directory, where information seekers could browse categories rather than perform a keyword search.44
Simultaneously, the first true crawlers emerged. The World Wide Web Wanderer (1993) was the first robot, designed simply to track the web’s growth.42 Excite, which began as Architext in 1993, offered keyword search capabilities alongside its directory 42, and WebCrawler (1994) was the first to offer “full text” search, allowing users to search for any word on any webpage.44
This first generation of tools (Excite, Lycos, Infoseek, Inktomi, AltaVista) 44 solved the problem of discovery. However, they lacked a mechanism for authority or quality. Their reliance on full-text keyword matching made them trivially easy to manipulate. The earliest Search Engine Optimization (SEO) was simple “keyword stuffing,” which led to poor, irrelevant, and often-manipulated search results.47 Search engines like Inktomi became commoditized backends, powering portals like Goto.com and MSN Search, which then layered their own monetization (e.g., paid links) on top.48
The PageRank Revolution (1998): Authority as the Solution
The 1998 paper from Sergey Brin and Larry Page, “The Anatomy of a Large-Scale Hypertextual Web Search Engine,” 49 introduced a fundamentally new concept. The problem, they argued, was not finding pages but ranking them. Their solution, PageRank, was a link analysis algorithm that repurposed the web’s own “citation (link) graph” 50 as a global voting system to measure authority.
The algorithm’s brilliance was its recursive definition: “A page that is linked to by many pages with high PageRank receives a high rank itself”.51 A hyperlink was counted as a “vote of support”.51 PageRank was, in effect, a method for “objectively and mechanically… measuring the human interest and attention devoted to” web pages.52 This “wisdom-of-crowds” justification 50 provided a robust, global authority score that was highly resistant to the simple keyword-stuffing manipulation that plagued its predecessors.47
The Economic Model (2000-2025): Clicks as Currency
PageRank’s stable, high-quality authority signal did more than create a good user experience; it created a new, sustainable economic model. The core architecture of the Google paradigm was as follows:
-
A human user inputs keywords.
-
The engine returns a ranked list of URLs.
-
The user clicks a URL to navigate to a page.
This click became the fundamental, monetizable unit of the human-centric web. It created the inventory for the sponsored search advertising model 53, which became the economic engine for the entire Web 2.0 ecosystem.1
The profound second-order effect of this architecture was the creation of the multi-billion-dollar SEO industry.43 The entire industry is a direct economic consequence of a human-centric, link-authority-based algorithm. Its goal is to analyze and influence human-centric authority signals (backlinks, content relevance) to capture human traffic, which is then monetized via ads.
This entire, 25-year-old paradigm, built on human users, PageRank authority, and ad-click currency, is the system that is now collapsing. The shift to an agent-centric web is not an evolution; it is a replacement of every foundational assumption, as detailed in Table 1.
Table 1: The Paradigm Shift: Human-Centric vs. Agent-Centric Search
| Feature | Paradigm 1: Human-Centric (1998-2025) | Paradigm 2: Agent-Centric (2025-) |
|---|---|---|
| Primary User | Human Eyeballs | AI Agent ^35 |
| Primary Goal | Discovery & Navigation | Task Completion & Reasoning ^39 |
| Core Problem | Ranking a list of URLs | Synthesizing a trusted, token-efficient answer |
| Key Algorithm | PageRank (Link-based Authority) ^51 | RAG + TTC (Hybrid Retrieval & Reasoning) ^54 |
| Query Type | Keywords ^47 | Semantic Objectives / Natural Language ^4 |
| Monetization | Ad-Click Revenue ^1 | API Call / GPU Compute Cost ^2 |
| Key Asset | The URL / Click-Through Rate (CTR) ^1 | Token-Efficient Context ^4 |
| Primary Attack | SEO / Link Spam ^47 | Index Poisoning / Prompt Injection ^18 |
Feature****Paradigm 1: Human-Centric (1998-2025)****Paradigm 2: Agent-Centric (2025-)****Primary UserHuman EyeballsAI Agent 35Primary GoalDiscovery & NavigationTask Completion & Reasoning 39Core ProblemRanking a list of URLsSynthesizing a trusted, token-efficient answerKey AlgorithmPageRank (Link-based Authority) 51RAG + TTC (Hybrid Retrieval & Reasoning) 54Query TypeKeywords 47Semantic Objectives / Natural Language 4MonetizationAd-Click Revenue 1API Call / GPU Compute Cost 2Key AssetThe URL / Click-Through Rate (CTR) 1Token-Efficient Context 4Primary AttackSEO / Link Spam 47Index Poisoning / Prompt Injection 18
Section 03: Technical Decomposition: The AI-Native Search Architecture
The new agent-centric paradigm is enabled by a fundamentally different technical stack. While classical search was an information retrieval system, AI-native search is a retrieval and reasoning system. It is not designed to return a list but to synthesize an answer. This requires a hybrid architecture that balances classical precision with semantic depth, underpinned by a new, complex vector processing pipeline.
The Hybrid Retrieval Core: Sparse + Dense Fusion
AI-native search is not, as commonly misunderstood, a simple replacement of keyword search with “vector search.” Instead, it is a fused architecture that retains the strengths of classical Information Retrieval (IR) while integrating the power of dense embeddings.32
-
Sparse Retrieval (The Survivor): This is the classical IR model, most commonly BM25.57 It operates on sparse vectors (e.g., bag-of-words) and excels at lexical, keyword-based matching.59 It is retained for its high precision on exact-match queries and its ability to handle out-of-vocabulary terms that dense models may miss.
-
Dense Retrieval (The Evolver): This is the vector-based semantic search. Documents are passed through an embedding model (e.g., OpenAI’s text-embedding-3-large 57) to create dense vector representations. This allows the system to find semantically or conceptually related documents, even if they do not share a single keyword with the query.59
-
Fusion: The two resulting ranked lists (one sparse, one dense) are combined to produce a single, robust candidate set. This is often achieved using ranklist fusion techniques like Reciprocal Rank Fusion (RRF) 60 or by applying a linear combination of relevance signals (e.g., BM25 score + cosine similarity) with tunable boost parameters.57
Vector Pipeline Architecture: The Embedding Engine
The core asset of the new search is the vector index. Storing and searching billions of high-dimensional vectors (embeddings) at high speed and low cost requires a specialized pipeline. This pipeline relies on Approximate Nearest Neighbor (ANN) search algorithms 61 rather than exact search.
-
Indexing Structures (HNSW vs. IVF): Two primary structures dominate.
-
HNSW (Hierarchical Navigable Small World): This is a graph-based algorithm that structures data into a multi-layered graph, enabling “coarse-to-fine” logarithmic-time search.61 Its primary trade-off is performance versus cost: HNSW can achieve extremely high recall (>95%) at sub-millisecond latencies.61 However, it suffers from an enormous memory footprint that scales linearly with dataset size, potentially exceeding 1 TB for billion-scale datasets.61
-
IVF (Inverted File Index): This approach uses k-means clustering to partition the vector space into clusters, each represented by a centroid.62 It is significantly more memory-efficient than HNSW but can have lower recall.
-
Quantization (Compression): To mitigate the memory and computational costs of high-dimensional vectors, compression techniques are essential.
-
PQ (Product Quantization): This technique partitions vectors into subspaces and uses codebooks to approximate distances.61 It is highly effective at balancing memory efficiency and search speed, especially when paired with IVF (IVF-PQ).62 However, PQ’s “global” nature can lead to accuracy degradation if the data distribution varies significantly.61
Query Planning and Execution
The AI-native architecture must serve an AI agent, not a human. A human issues a query; an agent issues a task or objective. This requires a “query planning” layer. A complex, multi-hop objective (e.g., “Analyze the Q2 2025 financial performance of the top three EV companies and summarize their supply chain risks”) cannot be answered in a single retrieval.
The architecture must support a semantic reformulation loop where the agent:
-
Decomposes the objective into a task tree of sub-queries.
-
Executes an initial retrieval.
-
Reasons over the retrieved context.
-
Dynamically reformulates new, more specific queries to fill knowledge gaps.
-
Interleaves retrieval and generation steps in a dynamic path.65
The Core Architectural Tension: Drift vs. Freshness
This new, complex stack introduces a fundamental operational conflict that did not exist in classical search: the tension between model quality and index freshness.
-
Model Drift: The Large Language Model (LLM) at the core of the reasoning engine is not static. As it is fine-tuned, updated, or retrained, its performance and qualitative behavior can change, a phenomenon known as “model drift”.14 This is a standard MLOps challenge.
-
Context Drift: The “ground truth” of the world, represented by the retrieval index, is also not static. A company’s refund policy, a medical coding rule, or a breaking news event changes the “right answer”.15 The rebuilding of the search index to reflect this new reality is explicitly defined as “concept or context drift”.15
This creates a high-stakes, co-dependent battle. AI models have a strong recency bias and perform better when citing fresher content.67 A stale index (low freshness) will cause the agent to retrieve outdated information and confidently “hallucinate” incorrect facts.15
However, the solution to context drift, re-crawling and re-embedding the index, can itself cause system failure. The agent’s query-planning logic may have been optimized for the structure and content of the old index. When the index is suddenly updated, the agent’s learned reasoning patterns may break. Therefore, the DataOps team managing index freshness 68 and the MLOps team managing model drift 14 are locked in a continuous, unstable operational balance, where a fix for one can break the other.
Section 04: Index Engineering: The New Frontier of Curation and Defense
In the PageRank paradigm, the index was a reflection of the web. In the AI-native paradigm, the index must be a curated, security-hardened asset. The astronomical cost of embedding and the new adversarial vectors of data poisoning fundamentally change the philosophy of crawling and indexing.
Recrawl Strategy: From Brute-Force to Intelligent Policy
Classical crawlers were optimized to minimize age (the time since a page changed) and maximize freshness (the binary state of being up-to-date).68 This often involved brute-force crawling strategies based on statistical update models, such as Poisson distributions.68
This “dense crawl” model is economically non-viable for an AI-native index. The “high cost-to-serve” 2 is not just in querying but also in building the index. The GPU burn-rate required to re-embed the entire web daily is prohibitive.69
The new architecture thus requires an “RL sparse recrawl” policy. This implies that a Reinforcement Learning (RL) agent, or a similar sophisticated policy, now manages the URL frontier and crawl budget. This agent must be trained to optimize a complex, multi-objective function:
-
Cost (GPU Burn): Minimize the number of pages re-embedded.69
-
Freshness & Novelty: Prioritize domains with high change rates or that contain novel, high-value information, while deprioritizing static content.68
-
Security (Adversarial Defense): This is the new, critical variable. The crawl policy must learn to actively deprioritize or sandbox domains suspected of “index poisoning” or being part of “large-scale adversarial saturation” campaigns (i.e., AI-generated spam farms).
Authority Scoring for a Post-PageRank World
The PageRank algorithm 51 is foundationally broken in an agent-centric world. Its core signal, the “citation (link) graph” 50, is no longer trustworthy. In an era of generative AI, an adversary can create infinite fake pages with infinite fake citations, making link-based authority meaningless.
The AI-native index requires a new, multi-modal “authority score.” This score is not about links; it is a trust and provenance score designed explicitly to mitigate hallucination propagation. The indexer must score content based on a new set of signals:
-
Domain Provenance: The age, history, and reputation of the source.
-
Human Traffic Signals: Data (where available) on whether actual humans are viewing and trusting the content.
-
Cross-Source Consistency: Whether the information on a page agrees or disagrees with other high-trust sources. Disagreement can be a key signal for either high-value novelty or disinformation.
-
Content Structure: Whether the page is formatted for human consumption or is clearly AI-generated spam (e.g., malformed HTML, keyword-stuffed text).67
Security-Hardened Curation
The index is no longer a neutral repository; it is the primary data supply chain for every agent on the platform. As such, it must be treated as a primary, high-value target for attack. The index engineering pipeline must become an adversarial filtering process.
This involves active “index poisoning and poisoning defense.” The crawler and indexer must be designed to detect and neutralize content specifically engineered to be retrieved by RAG agents. This includes filtering for “indirect prompt injections” (see Section 08) and content designed to skew the embedding space. The index, in short, is no longer just built; it is defended.
Section 05: Agent-Centric Search Pipelines and Orchestration Patterns
The primary user of the new search is an AI agent. This “user” is not a human browsing but an automated system acting. This requires an entirely new set of “scaffolding”, the architectural components that enable an LLM to reason, plan, and execute complex tasks.
The Reasoning Synergy: RAG + TTC
The agent’s “brain” is a synergy of two key processes: Retrieval-Augmented Generation (RAG) and Test-Time Compute (TTC).
-
RAG (The Knowledge): RAG is the foundational mechanism for grounding an LLM in dynamic, external knowledge, allowing it to access data beyond its static training set.70 This bridges the gap between the static model and the real-time world.61
-
TTC (The Thought): Test-Time Compute (TTC) is a newer concept that allows a model to “think” during inference by allocating additional computational resources to more challenging tasks.55 Instead of a single, fast answer, TTC enables iterative processes, allowing the model to evaluate multiple solutions or reasoning paths before responding.55
The combination of these two creates Agentic RAG. This is not a single, passive retrieval. It is an active, intelligent feedback loop.54 The agent retrieves (RAG), reasons on the context (TTC), identifies gaps, reformulates a new query (TTC), and retrieves again (RAG). This loop continues until the task is complete, allowing the agent to dynamically “try one more time” 65 and assemble fragmented clues from multiple sources.34
Orchestration Patterns: From Flat to Hierarchical
Simply connecting multiple agents in a “flat” system fails at scale. Production deployments have shown that without coordination, agents “duplicate work, operate on inconsistent states, and burn through token budgets”.7
The solution that has emerged as the dominant, scalable pattern is hierarchical multi-agent orchestration.72 Frameworks like “AgentOrchestra” 72 provide a clear blueprint for this architecture:
-
Central Planning Agent: This is the “conductor” 72 or “central orchestrator”.72 It serves as the high-level brain, dedicated to reasoning, task decomposition, and adaptive planning. It maintains a “global perspective” and delegates sub-tasks.72
-
Specialized Sub-Agents: These are the “musicians” or “specialized agents”.72 The planner delegates sub-tasks to a team, which may include a “web navigation agent,” “data analysis agent,” “SQL Agent” 74, or “file operations agent”.73 Each agent is equipped with specific tools to execute its narrow function.
The Foundational Requirement: Shared Memory Engineering
This hierarchical orchestration is architecturally impossible without one final, critical component: a shared state. “Memory engineering” is the missing foundation for scalable multi-agent systems.7
The central problem is that agents, built on stateless LLMs, must operate in a stateful world. “Most multi-agent AI systems fail not because agents can’t communicate, but because they can’t remember”.7
The solution is a “shared persistent memory system,” a “computational exocortex” 7, or “shared memory structure” 8 that all agents can read from and write to. This component, which may be a vector database, a high-speed cache, or a message pool, acts as the collective memory and shared reality for the entire “orchestra”.75 It stores “memory units” (intermediate findings, artifacts, user context) 7, allowing an agent to see what other agents have already done, thereby preventing work duplication, resolving inconsistent states, and dramatically reducing communication overhead.7 This “Cache-Augmented Generation” (CAG) 76 is the true enabler of collective agent intelligence.
Failure Modes and Rollback
In this new paradigm, failure has kinetic consequences. Unlike generative AI, which produces content for a human to review, an agent acts.77 It can “push malformed pricing data into production” 78 or “book flights” 77, resulting in direct financial loss and safety risks.77
A critical failure mode is the recursive API call loop 79 or tool misuse, where an agent gets stuck or performs a destructive action. Traditional database rollback strategies are insufficient, as they would destroy hours of accumulated agent context.
The correct mitigation strategy is context snapshotting. At critical decision points (e.g., before an API call), the agent’s full state and memory are captured as a lightweight snapshot.80 If a failure occurs, the system does not restart from scratch; it resumes from the last known-good snapshot, preserving the accumulated reasoning and context.80
Section 06: Vendor Landscape and Architecture Trade-Off Map
The collapse of the old paradigm has triggered a Cambrian explosion of new, API-first vendors building the infrastructure for the agent-centric web. Simultaneously, incumbents are making massive strategic pivots to avoid being commoditized.
The AI-Native Challengers
A new class of startup has emerged, building proprietary search indexes from the ground up for AI agents.
-
Parallel AI: This vendor’s philosophy is the thesis of the new paradigm. They state that “AI… needs fundamentally different infrastructure”.4 Their architecture is not designed to “rank URLs for humans to click” but to optimize “what tokens should go in an agent’s context window”.4 This is achieved through “token-relevance ranking” (prioritizing pages based on token-level relevance, not human engagement) and delivering “information-dense excerpts” (compressed, high-signal tokens for reasoning).4
-
Exa (formerly Metaphor): Exa positions itself as a “privacy-focused” 81 deep-research engine. It emphasizes semantic depth and “full developer control” (e.g., filtering, date-range).81 Critically, it offers full content retrieval (“get contents”), not just snippets or URLs, making it suitable for deep, multi-hop reasoning tasks.81
-
Tavily: Tavily’s architecture is fundamentally different. It is not a proprietary index but a wrapper that “relies on routing queries to Google”.81 Its value proposition is not index-based but rather “low overhead setup and speed of integration”.82 It is architected for fast RAG workflows that need structured answers quickly, rather than deep research.82
The Incumbent’s Gambit: Microsoft’s Vertical Play
The most significant strategic move in the market has come from the largest incumbent. Microsoft has announced the full retirement of the general-purpose Bing Search APIs, effective August 11, 2025.5
This is not a simple product deprecation; it is a profound strategic pivot. Microsoft is forcing users to migrate to “Grounding with Bing Search as part of Azure AI Agents”.5
This move is a classic vertical integration and ecosystem-lock-in strategy.
-
Abandon the Commodity: Microsoft recognizes that a general-purpose, horizontal “search result” API is a low-value, low-margin commodity.
-
Capture the Value: The true value and “stickiness” is at the high-level agentic orchestration layer.83
-
Force the Migration: By retiring the general API, Microsoft forces any developer who needs real-time web grounding for their AI into the Azure ecosystem.6
-
The Result: They are abandoning the old, low-margin business (search results) to capture the new, high-margin, vertically integrated business (Azure-hosted agentic reasoning). This move is the single clearest market validation of the agent-centric paradigm.
Table 2: AI-Native Search Vendor Architecture Comparison
| Vendor | Index Source | Core Philosophy | Key Output | Latency / Depth |
|---|---|---|---|---|
| Tavily | Google (Wrapper) ^81 | Fast RAG integration; low overhead ^82 | Structured answers ^82 | Low Latency / Shallow Depth ^82 |
| Exa | Proprietary ^81 | Semantic Depth & Full Control ^81 | Full Page Content ^81 | High Latency / Deep Research ^82 |
| Parallel AI | Proprietary ^4 | Token-Relevance Ranking ^4 | Information-Dense Excerpts ^4 | Single-Call Resolution ^4 |
| Microsoft (New) | Bing | Ecosystem-Locked Grounding ^6 | Agent Response (in Azure) ^83 | Azure-Dependent ^6 |
VendorIndex SourceCore PhilosophyKey OutputLatency / Depth****TavilyGoogle (Wrapper) 81Fast RAG integration; low overhead 82Structured answers 82Low Latency / Shallow Depth 82ExaProprietary 81Semantic Depth & Full Control 81Full Page Content 81High Latency / Deep Research 82Parallel AIProprietary 4Token-Relevance Ranking 4Information-Dense Excerpts 4Single-Call Resolution 4**Microsoft (New)**BingEcosystem-Locked Grounding 6Agent Response (in Azure) 83Azure-Dependent 6
Section 07: Economic Models: The Collapse of Clicks and the Rise of Compute
The agent-centric transformation is, at its core, an economic one. It represents the collapse of the 25-year-old ad-click economy and its replacement with a new, far more costly model based on GPU compute.
The Collapse of the Ad-Click Economy
The introduction of AI-native search and “AI Overviews” (like Google’s) 1 is an existential threat to the ad-based web. These tools eliminate the click. The user receives a synthesized answer on the results page, removing any incentive to click through to external publisher websites.
The economic consequences are immediate and severe:
-
CTR Collapse: This shift is causing “a reduction in its click-through rate from 5.1 percent to 0.6 percent” for some publishers 1 and a general “traffic loss of catastrophic proportions”.1
-
Zero-Click Dominance: The proportion of “zero-click searches”, those that do not result in a click on an external destination, is now the majority.1
Because the ad-sponsored search model (which generated ~$175B for Google in 2024) 1 is entirely dependent on clicks as its monetizable inventory, this trend renders the model economically non-viable.
The New Economics: GPU Burn Rate and Total Cost of Ownership (TCO)
The ad model is being replaced by a “cost-to-serve” model.2 Unlike traditional software, which has a near-zero marginal cost for replication, “each AI interaction consumes significant computational resources”.2
The key economic driver is the cost of GPU inference. According to Google’s own analysis, an AI-powered search query can be up to 10x more costly than a standard keyword search.2
This 10x cost-per-query creates “negative gross margin” dynamics.2 Companies that price their AI products like traditional SaaS (e.g., flat subscriptions) are reportedly “losing money” on their power users, as the compute costs of those users exceed their subscription revenue.3 This economic model is unsustainable at scale.
This brutal, GPU-driven cost curve creates a powerful incentive to outsource. The sheer cost and complexity of building and maintaining an in-house index, embedding pipeline, and inference stack 84 makes it impractical for most companies. This creates the market for the API-first vendors described in Section 06.
Vendor Lock-in and Mitigation Strategies
The incentive to outsource, combined with the immaturity of the AI stack, creates a new and severe risk of vendor lock-in.
-
Framework Lock-in: Enterprises that build their logic directly on a vendor’s rapidly evolving, “immature” agent framework (e.g., LangChain, OpenAI’s SDKs) 85 risk catastrophic failure. A single “API change in a leading agent framework” can cause an entire enterprise system to collapse in production overnight.85
-
Data Lock-in: A more subtle risk is data lock-in. Developers who, for convenience, store their chat histories, memory vectors, and critical embeddings inside the AI vendor’s systems may find they “can’t export them cleanly” or are charged extra to retrieve their own data.86
The high switching costs and platform-specific dependencies (e.g., Azure AI Agents 87) create a strategic liability. Mitigation requires an architectural and philosophical commitment to interoperability.
-
Architectural Abstraction: Enterprises must build abstraction layers that insulate their core business logic from the specific vendor’s framework, treating the AI model or search API as a swappable component.87
-
Data Sovereignty: The enterprise must always store its critical AI data (vectors, embeddings, logs) in its own databases and infrastructure, not the model provider’s.86
-
Open Standards: The only long-term defense is a robust, open ecosystem. Enterprises must demand and build on open standards like the Model Context Protocol (MCP) and Agent2Agent (A2A).39 These protocols create a “lingua franca” that enables interoperability, “freedom to choose best-of-breed solutions” 41, and the ability to swap components, which is the ultimate defense against lock-in.
Section 08: Security, Provenance & Zero Trust Search Architecture
The AI-native search stack does not just change the attack surface; it inverts it. The primary threat is no longer at the network perimeter but in the data supply chain and the model’s reasoning process. Defending this new stack requires a paradigm shift from perimeter security to a Zero Trust Architecture (ZTA).
The New Attack Surface: Hacking the RAG Pipeline
The RAG pipeline, which connects the LLM to the external index, is the new attack vector. An attacker no longer needs to penetrate the application; they only need to get their malicious payload into the index, knowing an agent will retrieve it. The OWASP Top 10 for Large Language Model Applications provides a clear taxonomy for these new threats.16
Table 3: AI-Native Attack Surface Risk Register (OWASP Mapping)
| Threat Vector | Mechanism | OWASP AI Top 10 | Source(s) |
|---|---|---|---|
| Indirect Prompt Injection | The primary threat. An attacker plants a malicious prompt (e.g., “Ignore all previous instructions and…”) on a public webpage. The agent’s RAG pipeline retrieves this “trusted” content, and the LLM executes the malicious instructions, leading to data exfiltration or content manipulation. | LLM01: Prompt Injection ^16 | ^17 |
| Index / Data Poisoning | An attacker floods the web with AI-generated spam or subtly poisoned documents. These are ingested by the crawler and contaminate the training data or retrieval index, skewing the model’s answers or creating backdoors. | LLM03: Training Data Poisoning ^16 | ^90 |
| Embedding Poisoning (SEP) | A sophisticated deployment-phase supply chain attack. An attacker injects “imperceptible perturbations” directly into the embedding layer of a model (e.g., on Hugging Face). This bypasses safety alignment and induces harmful behavior with a >96% success rate. | LLM05: Supply Chain Vulnerabilities ^16 | ^19 |
| Agent Tool Misuse | An agent is tricked (typically via LLM01) into calling a tool or API with malicious parameters. This exploits the agent’s ability to act, enabling the attacker to execute arbitrary commands, exfiltrate data, or cause financial/kinetic harm. | LLM08: Excessive Agency ^16 | ^77 |
| Reasoning Poisoning | A stealthy form of data poisoning where the attacker modifies only the reasoning path (Chain-of-Thought) in the training data, leaving the prompt and final answer “clean” to evade simple detection. | LLM03: Training Data Poisoning | ^92 |
Threat VectorMechanismOWASP AI Top 10****Source(s)****Indirect Prompt InjectionThe primary threat. An attacker plants a malicious prompt (e.g., “Ignore all previous instructions and…”) on a public webpage. The agent’s RAG pipeline retrieves this “trusted” content, and the LLM executes the malicious instructions, leading to data exfiltration or content manipulation.LLM01: Prompt Injection 1617Index / Data PoisoningAn attacker floods the web with AI-generated spam or subtly poisoned documents. These are ingested by the crawler and contaminate the training data or retrieval index, skewing the model’s answers or creating backdoors.LLM03: Training Data Poisoning 1690Embedding Poisoning (SEP)A sophisticated deployment-phase supply chain attack. An attacker injects “imperceptible perturbations” directly into the embedding layer of a model (e.g., on Hugging Face). This bypasses safety alignment and induces harmful behavior with a >96% success rate.LLM05: Supply Chain Vulnerabilities 1619Agent Tool MisuseAn agent is tricked (typically via LLM01) into calling a tool or API with malicious parameters. This exploits the agent’s ability to act, enabling the attacker to execute arbitrary commands, exfiltrate data, or cause financial/kinetic harm.LLM08: Excessive Agency 1677Reasoning PoisoningA stealthy form of data poisoning where the attacker modifies only the reasoning path (Chain-of-Thought) in the training data, leaving the prompt and final answer “clean” to evade simple detection.LLM03: Training Data Poisoning92
Defense: A Zero Trust Architecture (ZTA) for AI Search
Traditional “perimeter” security, which trusts everything “inside the firewall” 93, is catastrophically unsuited for this paradigm. The threat (the poisoned data) is already inside.
The only logical defense model is a Zero Trust Architecture (ZTA), as defined by NIST Special Publication 800-207.22 ZTA’s core tenets are to “never trust, always verify” and to “focus on protecting resources… not network segments”.94
Applied to an AI-native search pipeline, a ZTA means:
-
Assume All Retrieved Content is Malicious: The “trust boundary” must be placed between the RAG retriever and the LLM prompter. Every piece of text retrieved from the index, even from “trusted” domains, must be treated as a potential Indirect Prompt Injection (LLM01). It must be aggressively sanitized, and its influence on the agent’s core instructions must be segregated.
-
Continuous Trust Verification: The Policy Enforcement Point (PEP) must validate every single action the agent attempts to take. Before an agent can call an API (LLM08), it must be verified against “behavior-based continuous trust verification” 23, ensuring the action is aligned with user intent and not the result of a hijacked reasoning process.
-
Immutable Data Provenance: A ZTA is impossible without “comprehensive information security”.22 In an AI context, this means immutable data provenance. The system must be able to trace a final synthesized answer back to the specific source documents and agent reasoning steps that produced it.24 As outlined in NIST AI 600-1, documenting “data collection methodologies” and “data provenance” 24 is the only way to perform forensics, identify the source of a poisoning attack, and establish accountability.
Section 09: Governance & Compliance: Mapping Agents to Law
The new agentic architecture is not being deployed in a vacuum. It is emerging in a mature, and increasingly strict, regulatory landscape. The technical design of these systems is on a direct collision course with foundational principles of EU law, creating significant liability for their operators.
EU AI Act: Risk Classification
The EU AI Act classifies systems based on risk.95 The classification of an AI-native search engine is not monolithic; it depends entirely on its domain and application.
-
Minimal/Limited Risk: A general-purpose web search agent will likely fall into the “Minimal Risk” (unregulated) or “Limited Risk” category.95 This would primarily impose transparency obligations, the user must be clearly informed they are interacting with an AI.95
-
High-Risk: The moment that same agent architecture is deployed in a “high-risk” domain (listed in Annex 3 of the Act) 96, its legal status changes. An enterprise agent used for recruitment, credit scoring, or in law enforcement 96 or as a safety component 97 would be classified as “High-Risk.” This triggers the Act’s full, severe compliance burden, including requirements for data governance, technical robustness, and human oversight.98
NIS2: Search as Critical Infrastructure
The most immediate and impactful regulation is the NIS2 Directive. This directive explicitly expands its scope to include “digital providers” such as “online search engines” and “digital infrastructure” (like data center providers).29
This reclassification has profound consequences. Operators of AI-native search (e.g., Parallel, Exa, Microsoft) are now legally designated as “operators of essential services” (i.e., critical infrastructure).29
This imposes new, legally binding cybersecurity obligations 29, including:
-
Supply Chain Security: Mandated risk management for the entire supply chain.31 This directly maps to the threat of Embedding Poisoning (SEP) 19 and Data Poisoning 91, forcing operators to secure their data and model-ingestion pipelines.
-
Incident Reporting: A new, tight timeline for notification. In-scope entities must submit an “early warning” of any “significant incident” to their national authority (CSIRT) within 24 hours of awareness.29 A successful index poisoning or prompt injection attack that manipulates public-facing information would unquestionably meet this threshold.
GDPR: The Inherent Conflict
While the AI Act is new, the 2018 General Data Protection Regulation (GDPR) presents the most fundamental architectural challenge to agentic AI.
-
Conflict 1: Persistent Memory vs. Article 5(e) (Storage Limitation):GDPR Article 5(e) enshrines the principle of storage limitation: personal data must be kept “only as long as necessary for the intended purpose”.26 This underpins the right to erasure.100 The new agentic architecture, however, is defined by its reliance on “persistent memory” 25 and a “computational exocortex” 7 to learn and maintain state. The agent creates “derived artifacts” (its “thoughts” or intermediate reasoning).28
-
The Conflict: How does a data controller execute a “right to erasure” request on an agent’s memory? Can a user demand the agent forget a derived insight? This is a fundamental, unresolved architectural clash.
-
Conflict 2: Agent Autonomy vs. Article 22 (Automated Decision-Making):GDPR Article 22 provides a “right not to be subject to a decision based solely on automated processing” if that decision has “legal or similarly significant effects”.26
-
The Conflict: An advanced AI agent, such as one in e-commerce 39 or finance 39, is, by definition, an automated decision-maker.102 This means that fully autonomous agents operating in high-stakes domains are prima facie non-compliant.
-
The Mandate: This legally requires that such agents cannot be fully autonomous. The architecture must include “redress mechanisms” 26 and “meaningful human oversight” 28, ensuring the user’s right to “obtain human intervention”.26
Table 4: Governance & Compliance Mapping
| AI Component / Function | EU AI Act (Risk) | GDPR (Article) | NIS2 (Obligation) |
|---|---|---|---|
| General Web Search Agent | Limited Risk (Transparency) ^95 | N/A | Critical Infrastructure ^29 |
| Agent (High-Stakes Domain) | High Risk (Full Burden) ^96 | Art. 22 (Human Intervention) ^27 | N/A |
| Persistent Agent Memory | N/A | Art. 5(e) (Storage Limitation) ^26 | N/A |
| RAG Pipeline / Index | N/A | Art. 35 (DPIA Required) ^102 | Supply Chain Security ^31 |
| Security Breach / Poisoning | N/A | Art. 33 (Breach Notification) | 24-Hour Incident Report ^29 |
AI Component / Function****EU AI Act (Risk)GDPR (Article)NIS2 (Obligation)General Web Search AgentLimited Risk (Transparency) 95N/ACritical Infrastructure 29Agent (High-Stakes Domain)High Risk (Full Burden) 96Art. 22 (Human Intervention) 27N/APersistent Agent MemoryN/AArt. 5(e) (Storage Limitation) 26N/ARAG Pipeline / IndexN/AArt. 35 (DPIA Required) 102Supply Chain Security 31Security Breach / PoisoningN/AArt. 33 (Breach Notification)24-Hour Incident Report 29
Section 10: Evaluation Frameworks & Benchmarks
The paradigm shift from a list of URLs to a synthesized answer renders classical IR evaluation metrics obsolete. A new framework is required to measure the quality of reasoning, not just the quality of retrieval.
The Obsolescence of Classical Metrics
Classical IR benchmarks (e.g., TREC) rely on metrics like mAP (mean Average Precision), nDCG@10 (normalized Discounted Cumulative Gain at 10), and R@50 (Recall at 50).32 These metrics are mathematically designed to do one thing: evaluate the quality of a ranked list of documents.103
In the AI-native paradigm, the final output is not a list; it is a generated, synthesized paragraph of text. A low-quality retrieval list could, in theory, be synthesized into a good answer, and a high-quality list could be “hallucinated” into a bad one. These metrics are no longer a proxy for user success.
The New Standard: Hybrid + Reasoning Metrics
Evaluation for an AI-native system must be bifurcated, measuring both the retrieval pipeline and the reasoning agent.
-
Retrieval (RAG) Quality: The first step is to evaluate the RAG pipeline. This requires new metrics that measure the utility of the retrieved context, such as:
-
Relevance: Do the retrieved documents match the query’s information need? 104
-
Faithfulness / Groundedness: Does the final generated answer stick to the facts present in the retrieved documents? 104
-
Reasoning (Agent) Quality: The more complex evaluation is of the agent itself. This moves beyond simple text-matching to task-based metrics:
-
Task Success Rate: Did the agent successfully complete its multi-step objective? 105
-
Memory Hit Rate: When performing a task, did the agent correctly retrieve a fact from its persistent memory versus having to re-compute or re-retrieve it? 105
Benchmark Case Study: BrowseComp
The new benchmark philosophy is epitomized by BrowseComp.33 BrowseComp was created specifically because existing benchmarks for simple, isolated fact retrieval (like SimpleQA) were “saturated” and “solved” by modern browsing agents.34
BrowseComp is not designed to measure simple retrieval. It is designed to measure agentic persistence.33
-
Methodology: It uses 1,266 “hard-to-find” factual questions that require “persistent, multi-step internet browsing”.33
-
What it Measures: It tests an agent’s ability to execute “strategic perseverance,” “flexible search reformulation,” and the “ability to assemble fragmented clues across multiple sources”.34 It is “easier to verify than to find the answer,” making it a robust test of deep research capability.34
This benchmark provides a direct, empirical link between agentic quality and economics. As shown in BrowseComp’s performance (Figure 1 in 106), there is a clear log-scale relationship between accuracy and test-time compute (TTC). Higher-performing agents are higher-performing because they expend more compute (i.e., “browsing effort”).106 This proves, at a benchmark level, that high-quality agentic search is a direct function of compute cost, reinforcing the economic model described in Section 07.
Section 11: Failure Modes & Adversarial Scenarios
While Section 08 detailed the tactical attack vectors on an individual RAG pipeline, this section analyzes the systemic, long-term failure modes and adversarial scenarios that threaten the entire AI-native ecosystem.
Agent-Level Failure: Kinetic and Operational Risk
As a recap of the risks introduced in Section 05, the primary tactical failure mode is that agents can act, not just write. An agent with “excessive agency” (OWASP LLM08) 16 that is compromised (e.g., by an indirect prompt injection) can “schedule meetings,” “book flights” 77, or “push malformed pricing data”.78 This creates immediate, real-world financial and safety risks 77, a failure class that did not exist in classical search. These tactical failures are mitigated by context snapshots 80 and ZTA (Section 08).
Ecosystem-Level Failure: Recursive Web Inflation and Model Collapse
The most profound, existential threat to the AI-native search paradigm is not a tactical hack but a systemic poisoning of the global data commons. This is the scenario of “recursive web inflation.”
The “Model Collapse” Phenomenon:
First detailed in a 2024 Nature paper 11, “model collapse” is a “phenomenon in which recursive iterations of training on synthetic data lead to performance degradation”.13
-
Mechanism: The mechanism is the “disappearance of real tail data” 12, also called “coverage collapse.” Generative models are good at learning the average of a distribution but poor at capturing its tails (the rare, unique, and outlier data). When a model is trained on its own output (or the output of another AI), it overfits to the average. The rare, human-generated “tail data” is progressively lost in each recursive loop.12
-
Result: The model’s diversity and coverage collapse. It “can only handle common cases but fail[s] on rare ones”.12 Ultimately, after enough recursive generations, the models degenerate and begin to produce “gibberish”.13
The Vicious Cycle for AI-Native Search:
This academic phenomenon becomes a catastrophic, real-world failure mode when applied to the AI-native search ecosystem.
-
Phase 1: Recursive Inflation: AI agents and content farms, seeking to capture agent traffic (the new SEO), begin flooding the web with “AI-generated AI-targeted content”.10
-
Phase 2: Index Contamination: The new AI-native search crawlers (Section 04), which are explicitly optimized to find fresh content 67, preferentially discover and index this new synthetic, low-diversity data.
-
Phase 3: Model Collapse: The next generation of all foundational models (from all labs, including OpenAI, Google, Anthropic) are trained on this now-contaminated, “collapsed” web data.11
-
Phase 4: Systemic Failure: The models lose their connection to the “ground truth” of human-generated tail data. The “ground truth” of the web is effectively destroyed, replaced by a low-quality recursive average. All AI-native search models, which depend on a high-quality, diverse index to function, begin to fail, producing homogenous, incorrect, or useless answers.
This is the scenario of “large-scale adversarial saturation.” It is the primary existential risk to the long-term viability of an information fabric built on web-scale RAG.
Section 12: Foresight 2030: Scenarios and Trajectories
The technical, economic, and security pressures analyzed in this report project a 2030 information landscape that is radically different from the human-centric web of today. The trajectories point toward three interconnected scenarios: the agent as the primary user, the fragmentation of the global index, and the rise of a new agent-to-agent negotiation layer.
Scenario 1: The Agent is the Web
By 2030, the primary “user” of the internet will not be a human. Projections estimate that non-human traffic will exceed 80% of all web traffic by that year.35 This fundamentally reshapes the entire purpose of the web.
The web will bifurcate. The human-centric “pixel-perfect landing page” 36 designed for emotional engagement will wane in importance. The dominant web will be an “invisible userspace” 36 designed for machine-to-machine interaction. Marketing, brand discovery, and e-commerce will shift from influencing human attention to influencing AI agent decision-making.35 Success will depend on API-first discovery, stable data schemas, and machine-readable trust signals, not visual design or emotional copy.36
Scenario 2: The Fragmented Index Ecosystem
The “one index to rule them all” (Google) model is over. The enormous GPU costs of indexing (Section 07), the severe security risks of a contaminated public web (Section 11), and the data-governance mandates (Section 09) will force the global index to fragment.
The 2030 landscape will be a “fragmented index ecosystem” composed of:
-
Public Indexes: A handful of high-cost, specialized vendors (like Parallel and Exa) that attempt to index the (collapsing?) public web for general-purpose agent use.
-
Enterprise Indexes: The “future of enterprise software”.39 Companies will adopt “agent-native” platforms from vendors like Microsoft (Fabric data agents) 38, Salesforce (Agentforce) 39, and SAP (Joule).39 The primary “index” these agents search will be the corporation’s own internal, proprietary data.
-
Sovereign Indexes: Nations, driven by data sovereignty and national security concerns, will build their own state-controlled indexes to power public-sector agents and ensure critical functions are not dependent on foreign-controlled, contaminated public indexes.
Scenario 3: The Agent-to-Agent (A2A) Negotiation Layer
A fragmented index ecosystem requires a new, abstract layer for interoperability. This will be the “agent-to-agent (A2A) negotiation layer” 40, built on open standards like MCP and A2A.41
This “multi-agent orchestration layer” 39 will function as the new, invisible information fabric. A user’s complex task will not be solved by one agent. Instead, it will be executed by an orchestra of agents negotiating across the fragmented index:
-
A user’s personal agent (e.g., in Microsoft Copilot Studio) 38 will receive a high-level objective.
-
It will decompose the task and negotiate 40 with an enterprise agent (at SAP) 39 to pull internal financial data.
-
It will simultaneously query a specialized public agent (at Exa) for market context.
-
The information will be exchanged and fused using a common protocol, perhaps a “Knowledge-Graph Translation Layer (KGTL)” 109, to generate the final, synthesized answer.
This emergent, decentralized, and agent-driven fabric, not a single search engine, will be the “web” of 2030.
Section 13: Strategic Recommendations for Builders, Enterprises, and Regulators
The transformation to an agent-native fabric presents distinct, high-stakes challenges and opportunities. The following recommendations are designed to be actionable for the three key stakeholder groups: builders (labs and API developers), enterprises (C-level, architects, and SOCs), and regulators (policymakers).
For Builders (Frontier Labs, API Developers)
-
Prioritize and Champion Open Standards: The greatest threat to a healthy ecosystem is vendor lock-in. Actively build for and champion open protocols like the Model Context Protocol (MCP) and Agent2Agent (A2A).39 This is not just an ethical good; it is a key selling point to enterprise customers who, having been locked-in before, are now demanding “long-term flexibility” 87 and “best-of-breed solutions”.41
-
Declare War on Model Collapse: The systemic failure of the public index (Section 11) is the single greatest technical and business risk to your model. Your R&D must prioritize provenance-aware crawlers and synthetic data detection to build “security-hardened indexes” (Section 04) that can differentiate and preserve human-generated “tail data” 12 while filtering recursive AI spam.11
-
Harden the Model Supply Chain: The Search-based Embedding Poisoning (SEP) attack 19 is a proven, high-success vector.20 Publicly distributing models (e.g., on Hugging Face) is a known vulnerability. You must implement embedding-level integrity checks 20 and digitally sign all model artifacts to secure the AI supply chain, which is now mandated under NIS2.31
For Enterprises (C-Level, Architects, SOCs)
-
Architect for Abstraction, Not Integration: Never wire your core business logic directly to a single, immature agentic framework.85 The risk of vendor-driven failure is too high. You must build an internal abstraction layer that treats the AI vendor (for search, reasoning, or orchestration) as a swappable component. This is your primary defense against vendor lock-in.87
-
Implement a Zero Trust Architecture (ZTA) for RAG: Your number one security priority is to internalize that your RAG pipeline will retrieve malicious content.18 You must implement the ZTA from Section 08: assume all retrieved content is hostile. Sanitize all inputs to the LLM and place a “behavior-based continuous trust verification” 23 on every action (API call) your agent attempts.22
-
Own Your Embeddings and Memory: Do not store your proprietary chat logs, agent memory vectors, or document embeddings in the vendor’s proprietary database.86 Store this critical data in your own infrastructure (e.g., a self-hosted vector database). This retains data sovereignty and ensures you can switch LLM or search vendors without losing your agent’s “memory.”
-
Engineer for GDPR Article 22 Now: Your autonomous agent is an automated decision-maker.102 You will be legally required to provide “redress mechanisms” 26 and “meaningful human oversight”.28 Start designing these “human-in-the-loop” escalation paths and audit trails now. They cannot be bolted on after the fact.
For Regulators and Policymakers
-
Enforce Existing Law (GDPR): You do not need to wait for the AI Act to govern agentic risk. Use the tools you have.
-
GDPR Article 22 27 is your most powerful lever. Use it to force companies to build auditable, contestable, and human-supervised agents, effectively banning “black box” autonomous systems in any high-stakes domain.
-
GDPR Article 5(e) 26 is the check against “persistent memory”.25 Use it to challenge the collection and permanent storage of derived data and agent “thoughts,” forcing companies to implement robust data erasure and limitation controls.
-
Activate NIS2 for AI-Native Search: Use the NIS2 Directive’s classification of “online search engines” as critical infrastructure.29 This gives you the clear legal authority to mandate that AI-native search providers implement robust supply chain security (against SEP) 31 and adhere to the 24-hour incident reporting window (against index poisoning).29
-
Mandate Data Provenance: The long-term threat of “model collapse” 11 is a direct threat to information integrity and, by extension, societal stability. Focus policy on data provenance (as defined by NIST AI 600-1).24 To combat the “disappearance of real tail data” 12, the ecosystem must have a reliable, machine-readable way to distinguish original, human-generated content from synthetic, recursive content. Mandating provenance is the only scalable, long-term solution.
Geciteerd werk
-
Google Search in the Age of Artificial Intelligence An Economic …, geopend op november 14, 2025, https://xpert.digital/en/google-search-in-the-age-of-artificial-intelligence/
-
AI Pricing in 2025: Monetizely’s Strategy for Costing, geopend op november 14, 2025, https://www.getmonetizely.com/blogs/ai-pricing-how-much-does-ai-cost-in-2025
-
Anthropic’s Rate Limits Signal the End of the Free Lunch, Winsome Marketing, geopend op november 14, 2025, https://winsomemarketing.com/ai-in-marketing/anthropics-rate-limits-signal-the-end-of-the-free-lunch
-
Introducing the Parallel Search API | Parallel Web Systems | Build …, geopend op november 14, 2025, https://parallel.ai/blog/introducing-parallel-search
-
Bing Search APIs Retiring on August 11, 2025, Microsoft Lifecycle …, geopend op november 14, 2025, https://learn.microsoft.com/en-us/lifecycle/announcements/bing-search-api-retirement
-
How to Replace the Deprecated Bing API (Complete Guide 2025 | Olostep Blog, geopend op november 14, 2025, https://olostep.com/blog/ultimate-bing-api
-
Why Multi-Agent Systems Need Memory Engineering | MongoDB, geopend op november 14, 2025, https://medium.com/mongodb/why-multi-agent-systems-need-memory-engineering-153a81f8d5be
-
Cognitive-inspired xLSTM for multi-agent information retrieval, PMC, NIH, geopend op november 14, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC12533026/
-
Multi Agent RAG with Interleaved Retrieval and Reasoning for Long Docs | Pathway, geopend op november 14, 2025, https://pathway.com/blog/multi-agent-rag-interleaved-retrieval-reasoning/
-
Recursive Intelligence: An AI Agent That Researches and Writes About AI Autonomously | by Abozar Alizadeh | Bootcamp | Medium, geopend op november 14, 2025, https://medium.com/design-bootcamp/recursive-intelligence-an-ai-agent-that-researches-and-writes-about-ai-autonomously-100bccd81001
-
Large Language Model Agent: A Survey on Methodology, Applications and Challenges, geopend op november 14, 2025, https://arxiv.org/html/2503.21460v1
-
1 Introduction, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2503.03150v1
-
(PDF) A Note on Shumailov et al. (2024): `AI Models Collapse When …, geopend op november 14, 2025, https://www.researchgate.net/publication/385010918_A_Note_on_Shumailov_et_al_2024_AI_Models_Collapse_When_Trained_on_Recursively_Generated_Data’
-
Understanding Model Drift and Data Drift in LLMs (2025 Guide) | Generative AI Collaboration Platform, Orq.ai, geopend op november 14, 2025, https://orq.ai/blog/model-vs-data-drift
-
Data Drift: Why Your LLMs and AI Agents Are Failing | by Nayeem …, geopend op november 14, 2025, https://medium.com/@nomannayeem/data-drift-why-your-llms-and-ai-agents-are-failing-8d978f07948e
-
OWASP Top 10 for Large Language Model Applications, geopend op november 14, 2025, https://owasp.org/www-project-top-10-for-large-language-model-applications/
-
What Is a Prompt Injection Attack?, IBM, geopend op november 14, 2025, https://www.ibm.com/think/topics/prompt-injection
-
LLM01:2025 Prompt Injection, OWASP Gen AI Security Project, geopend op november 14, 2025, https://genai.owasp.org/llmrisk/llm01-prompt-injection/
-
arxiv.org, geopend op november 14, 2025, https://arxiv.org/abs/2509.06338
-
Embedding Poisoning: Bypassing Safety Alignment via Embedding …, geopend op november 14, 2025, https://www.researchgate.net/publication/395355401_Embedding_Poisoning_Bypassing_Safety_Alignment_via_Embedding_Semantic_Shift
-
Abstractive, Nicholas Carlini, geopend op november 14, 2025, https://nicholas.carlini.com/writing/2019/advex_papers_with_abstracts.txt
-
Zero Trust Architecture, NIST Technical Series Publications, geopend op november 14, 2025, https://nvlpubs.nist.gov/nistpubs/specialpublications/NIST.SP.800-207.pdf
-
Implementing a Zero Trust Architecture, NIST NCCoE, geopend op november 14, 2025, https://www.nccoe.nist.gov/sites/default/files/2023-07/zta-nist-sp-1800-35b-preliminary-draft-3.pdf
-
Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile, NIST Technical Series Publications, geopend op november 14, 2025, https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
-
AI Agents and Memory: Privacy and Power in the Model Context Protocol (MCP) Era, geopend op november 14, 2025, https://www.newamerica.org/oti/briefs/ai-agents-and-memory/
-
Library, PLOT4AI, geopend op november 14, 2025, https://plot4.ai/library
-
CSV file, geopend op november 14, 2025, https://plot4.ai/downloads?csv
-
Engineering GDPR compliance in the age of agentic AI | IAPP, geopend op november 14, 2025, https://iapp.org/news/a/engineering-gdpr-compliance-in-the-age-of-agentic-ai
-
Implications of NIS2 on cybersecurity and AI, Darktrace, geopend op november 14, 2025, https://www.darktrace.com/blog/the-implications-of-nis2-on-cyber-security-and-ai
-
Directive on measures for a high common level of cybersecurity across the Union (NIS2 Directive), FAQs, geopend op november 14, 2025, https://digital-strategy.ec.europa.eu/en/faqs/directive-measures-high-common-level-cybersecurity-across-union-nis2-directive-faqs
-
NIS2 Directive: securing network and information systems | Shaping …, geopend op november 14, 2025, https://digital-strategy.ec.europa.eu/en/policies/nis2-directive
-
Searching for Best Practices in Retrieval-Augmented Generation, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2407.01219v1
-
BrowseComp: Agentic AI Web Benchmark, Emergent Mind, geopend op november 14, 2025, https://www.emergentmind.com/topics/browsecomp
-
BrowseComp: a benchmark for browsing agents | OpenAI, geopend op november 14, 2025, https://openai.com/index/browsecomp/
-
Web 4.0: From Human-Centric to Agent-Mediated | The AI Journal, geopend op november 14, 2025, https://aijourn.com/web-4-0-from-human-centric-to-agent-mediated/
-
From Human‑Centric Web to Agent‑Centric Web: One Year On | by TheNewAutonomy, geopend op november 14, 2025, https://thenewautonomy.medium.com/from-human-centric-web-to-agent-centric-web-one-year-on-f5e54b2f6d24
-
Designing for Two Audiences: Human-Centered and Agent-Centered UX in Action, geopend op november 14, 2025, https://www.carboncopies.ai/blog/designing-for-human-agent
-
Fabric Data Agents + Microsoft Copilot Studio: A New Era of Multi-Agent Orchestration (Preview) | Microsoft Fabric Blog | Microsoft Fabric, geopend op november 14, 2025, https://blog.fabric.microsoft.com/en-US/blog/fabric-data-agents-microsoft-copilot-studio-a-new-era-of-multi-agent-orchestration/
-
Seizing the agentic AI advantage, McKinsey, geopend op november 14, 2025, https://www.mckinsey.com/capabilities/quantumblack/our-insights/seizing-the-agentic-ai-advantage
-
Towards Fair and Trustworthy Agent-to-Agent Negotiations in Consumer Settings, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2506.00073v1
-
Agent Factory: Connecting agents, apps, and data with new open standards like MCP and A2A | Microsoft Azure Blog, geopend op november 14, 2025, https://azure.microsoft.com/en-us/blog/agent-factory-connecting-agents-apps-and-data-with-new-open-standards-like-mcp-and-a2a/
-
Search engine, Wikipedia, geopend op november 14, 2025, https://en.wikipedia.org/wiki/Search_engine
-
The Evolution of SEO: From Search Engine Origins to AI-Driven Discovery, Intellibright, geopend op november 14, 2025, https://www.intellibright.com/blog/evolution-of-seo/
-
(PDF) History Of Search Engines, ResearchGate, geopend op november 14, 2025, https://www.researchgate.net/publication/265104813_History_Of_Search_Engines
-
The Evolutionary Journey of Search Engines: A Detailed Exploration | by Adot, Medium, geopend op november 14, 2025, https://adotweb3.medium.com/the-evolutionary-journey-of-search-engines-a-detailed-exploration-1013ac6ac19f
-
Google: The Origin of Search | Acquired Podcast, geopend op november 14, 2025, https://www.acquired.fm/episodes/google
-
The Evolution of SEO: From Keywords to AI-Driven Search Optimization, yellowHEAD, geopend op november 14, 2025, https://www.yellowhead.com/blog/the-evolution-of-seo/
-
A Brief History of Search Engine Optimization | The Evolution of SEO, Darius Technology, geopend op november 14, 2025, https://dariustechnology.com/search-engine-optimization-a-history/
-
The Anatomy of a Large-Scale Hypertextual Web Search Engine, Google Research, geopend op november 14, 2025, https://research.google/pubs/the-anatomy-of-a-large-scale-hypertextual-web-search-engine/
-
PageRank’s ability to track webpage quality: reconciling Google’s wisdom-of-crowds justification with the scale-free structure of the web, NIH, geopend op november 14, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC6275164/
-
PageRank, Wikipedia, geopend op november 14, 2025, https://en.wikipedia.org/wiki/PageRank
-
The PageRank Citation Ranking: Bringing Order to the Web, geopend op november 14, 2025, http://ilpubs.stanford.edu/422/1/1999-66.pdf
-
An Empirical Analysis of Search Engine Advertising: Sponsored Search in Electronic Markets | Request PDF, ResearchGate, geopend op november 14, 2025, https://www.researchgate.net/publication/228234045_An_Empirical_Analysis_of_Search_Engine_Advertising_Sponsored_Search_in_Electronic_Markets
-
Agentic RAG and Context Engineering for Agents, Vinci Rufus, geopend op november 14, 2025, https://www.vincirufus.com/posts/agentic-rag-context-engineering/
-
Test Time Compute (TTC): Enhancing Real-Time AI Inference and Adaptive Reasoning, geopend op november 14, 2025, https://ajithp.com/2024/12/03/ttc/
-
HyST: LLM-Powered Hybrid Retrieval over Semi-Structured Tabular Data, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2508.18048v1
-
Domain-specific Question Answering with Hybrid Search, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2412.03736v2
-
arXiv:2409.13699v1 [cs.IR] 5 Sep 2024, geopend op november 14, 2025, https://arxiv.org/pdf/2409.13699
-
[D] Difference between sparse and dense information retrieval : r/MachineLearning, Reddit, geopend op november 14, 2025, https://www.reddit.com/r/MachineLearning/comments/z76uel/d_difference_between_sparse_and_dense_information/
-
A Survey of Model Architectures in Information Retrieval, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2502.14822v2
-
Quantization-Enhanced HNSW for Scalable …, OpenReview, geopend op november 14, 2025, https://openreview.net/pdf/ed3dadb42c88b62fc86e72b3e0a889de23f3c28c.pdf
-
An Adaptive Vector Index Partitioning Scheme for Low-Latency RAG Pipeline, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2504.08930v1
-
Optimizations and efficient retrieval solutions for large-scale visual Geo-localization problems, Webthesis, Politecnico di Torino, geopend op november 14, 2025, https://webthesis.biblio.polito.it/25610/1/tesi.pdf
-
Accelerating Vector Search: Fine-Tuning GPU Index Algorithms | NVIDIA Technical Blog, geopend op november 14, 2025, https://developer.nvidia.com/blog/accelerating-vector-search-fine-tuning-gpu-index-algorithms/
-
Reasoning RAG via System 1 or System 2: A Survey on Reasoning Agentic Retrieval-Augmented Generation for Industry Challenges, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2506.10408v1
-
Seven Strategies to Maintain LLM Reliability Across Diverse Use Cases in Production, geopend op november 14, 2025, https://galileo.ai/blog/production-llm-monitoring-strategies
-
Content Refresh 101: How to Improve Search and LLM Visibility | thruuu, geopend op november 14, 2025, https://thruuu.com/blog/content-refresh/
-
m05.s06, freshness, geopend op november 14, 2025, https://course.khoury.northeastern.edu/cs6200sp15/slides/m05.s06%20-%20freshness.pdf
-
Beyond GPUs and API Calls: Understanding the True Cost of AI Initiatives, Finout, geopend op november 14, 2025, https://www.finout.io/blog/beyond-gpus-and-api-calls-understanding-the-true-cost-of-ai-initiatives-2
-
Traditional RAG vs. Agentic RAG, Why AI Agents Need Dynamic Knowledge to Get Smarter, geopend op november 14, 2025, https://developer.nvidia.com/blog/traditional-rag-vs-agentic-rag-why-ai-agents-need-dynamic-knowledge-to-get-smarter/
-
[2506.00281] Adversarial Threat Vectors and Risk Mitigation for Retrieval-Augmented Generation Systems, arXiv, geopend op november 14, 2025, https://arxiv.org/abs/2506.00281
-
AgentOrchestra: A Hierarchical Multi-Agent Framework for General-Purpose Task Solving, geopend op november 14, 2025, https://arxiv.org/html/2506.12508v1
-
arxiv.org, geopend op november 14, 2025, https://arxiv.org/html/2506.12508v4
-
Dynamic Multi-Agent Orchestration and Retrieval for Multi-Source Question-Answer Systems using Large Language Models, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2412.17964v1
-
MAPLE: Multi-Agent Adaptive Planning with Long-Term Memory for Table Reasoning, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2506.05813v1
-
“Cache-Augmented Generation in RAG Pipelines: Fast and Memory-Efficient” by Yaju Gopal Shrestha, The Aquila Digital Community, geopend op november 14, 2025, https://aquila.usm.edu/honors_theses/1011/
-
Prioritizing Real-Time Failure Detection in AI …, Partnership on AI, geopend op november 14, 2025, https://partnershiponai.org//uploads/2025/09/agents-real-time-failure-detection.pdf
-
Understanding Risk Management for AI Agents | Galileo, geopend op november 14, 2025, https://galileo.ai/blog/risk-management-ai-agents
-
SHIELDA: Structured Handling of Exceptions in LLM-Driven Agentic Workflows, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2508.07935v1
-
5 Steps to Build Exception Handling for AI Agent Failures | Datagrid, geopend op november 14, 2025, https://www.datagrid.com/blog/exception-handling-frameworks-ai-agents
-
Exa vs. Tavily API, Exa | Web Search API, AI Search Engine, & Website Crawler, geopend op november 14, 2025, https://exa.ai/versus/tavily
-
Exa.ai vs. Tavily, AI Semantic Search API for LLM Comparison, Data4AI, geopend op november 14, 2025, https://data4ai.com/blog/tool-comparisons/exa-ai-vs-tavily/
-
How to use Grounding with Bing Search in Azure AI Foundry Agent Service, Microsoft Learn, geopend op november 14, 2025, https://learn.microsoft.com/en-us/azure/ai-foundry/agents/how-to/tools/bing-grounding
-
Burning Millions on LLM APIs? : r/LLMDevs, Reddit, geopend op november 14, 2025, https://www.reddit.com/r/LLMDevs/comments/1ld60ty/burning_millions_on_llm_apis/
-
The Agentic Framework Battlefield: How to Escape Vendor Lock-In and Survive the Next AI War | by Yi Zhou, Medium, geopend op november 14, 2025, https://medium.com/generative-ai-revolution-ai-native-transformation/the-agentic-framework-battlefield-how-to-escape-vendor-lock-in-and-survive-the-next-ai-war-e70db09d6628
-
AI Lock-In: 7 Ways to Keep Your LLM Stack Portable, SmythOS, geopend op november 14, 2025, https://smythos.com/ai-trends/how-to-avoid-ai-lock-in/
-
Why AI Vendor Lock-In Is a Strategic Risk and How Open, Modular AI Can Help, Kellton, geopend op november 14, 2025, https://www.kellton.com/kellton-tech-blog/why-vendor-lock-in-is-riskier-in-genai-era-and-how-to-avoid-it
-
- AI Security Overview, OWASP AI Exchange, geopend op november 14, 2025, https://owaspai.org/docs/ai_security_overview/
-
Backdoored Retrievers for Prompt Injection Attacks on Retrieval Augmented Generation of Large Language Models, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2410.14479v1
-
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples, arXiv, geopend op november 14, 2025, https://arxiv.org/abs/2510.07192
-
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2510.07192v1
-
Reasoning Introduces New Poisoning Attacks Yet Makes Them More Complicated, arXiv, geopend op november 14, 2025, https://arxiv.org/abs/2509.05739
-
NIST Offers 19 Ways to Build Zero Trust Architectures, geopend op november 14, 2025, https://www.nist.gov/news-events/news/2025/06/nist-offers-19-ways-build-zero-trust-architectures
-
Zero Trust Architecture | NIST, National Institute of Standards and Technology, geopend op november 14, 2025, https://www.nist.gov/publications/zero-trust-architecture
-
High-level summary of the AI Act | EU Artificial Intelligence Act, geopend op november 14, 2025, https://artificialintelligenceact.eu/high-level-summary/
-
Annex III: High-Risk AI Systems Referred to in Article 6(2) | EU Artificial Intelligence Act, geopend op november 14, 2025, https://artificialintelligenceact.eu/annex/3/
-
Article 6: Classification Rules for High-Risk AI Systems | EU Artificial Intelligence Act, geopend op november 14, 2025, https://artificialintelligenceact.eu/article/6/
-
Securing RAG: A Risk Assessment and Mitigation Framework, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2505.08728v2
-
Which companies must comply with NIS 2? Essential vs. important entities, Advisera, geopend op november 14, 2025, https://advisera.com/articles/who-does-nis2-apply-to/
-
The impact of the General Data Protection Regulation (GDPR) on artificial intelligence, European Parliament, geopend op november 14, 2025, https://www.europarl.europa.eu/RegData/etudes/STUD/2020/641530/EPRS_STU(2020)641530_EN.pdf
-
The Impact of the GDPR on Artificial Intelligence, Securiti, geopend op november 14, 2025, https://securiti.ai/impact-of-the-gdpr-on-artificial-intelligence/
-
Agentic AI and EU Legal Considerations | Mason Hayes Curran, geopend op november 14, 2025, https://www.mhc.ie/latest/insights/rise-of-the-helpful-machines
-
A Hybrid RAG System with Comprehensive Enhancement on Complex Reasoning, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2408.05141v3
-
Evaluation of Retrieval-Augmented Generation: A Survey, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2405.07437v2
-
Survey on Evaluation of LLM-based Agents, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2503.16416v1
-
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents, arXiv, geopend op november 14, 2025, https://arxiv.org/html/2504.12516v1
-
A Closer Look at Model Collapse: From a Generalization-to-Memorization Perspective, geopend op november 14, 2025, https://arxiv.org/html/2509.16499v1
-
AI 2030 Scenarios Report HTML (Annex C), GOV.UK, geopend op november 14, 2025, https://www.gov.uk/government/publications/frontier-ai-capabilities-and-risks-discussion-paper/ai-2030-scenarios-report-html-annex-c
-
tmgthb/Autonomous-Agents: Autonomous Agents (LLMs) research papers. Updated Daily., GitHub, geopend op november 14, 2025, https://github.com/tmgthb/Autonomous-Agents
From human centric to agent native web search
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.