From symbolic AI to reasoning LLMs (1950-2025).
The Definitive NLP and LLM Reading Stack. A Strategic Research Report on Engineering, Hardware, and Governance in the Age of Artificial Intelligence.
The phase transition to agentic reasoning
The trajectory of Artificial Intelligence is not a linear accumulation of capabilities but a series of distinct phase transitions, each precipitated by the collision of algorithmic theory with hardware reality. We currently stand at the precipice of the most significant shift since the Deep Learning reboot of 2012. The industry is moving from the era of Generative AI (2017-2023), characterized by probabilistic token prediction and content creation, to the era of Reasoning and Agentic AI (2024-2030), defined by systems capable of multi-step logic, self-correction, and autonomous tool usage. This report argues that this transition is not merely an evolution of software but a fundamental restructuring of the computational and economic paradigms that underpin the digital economy.
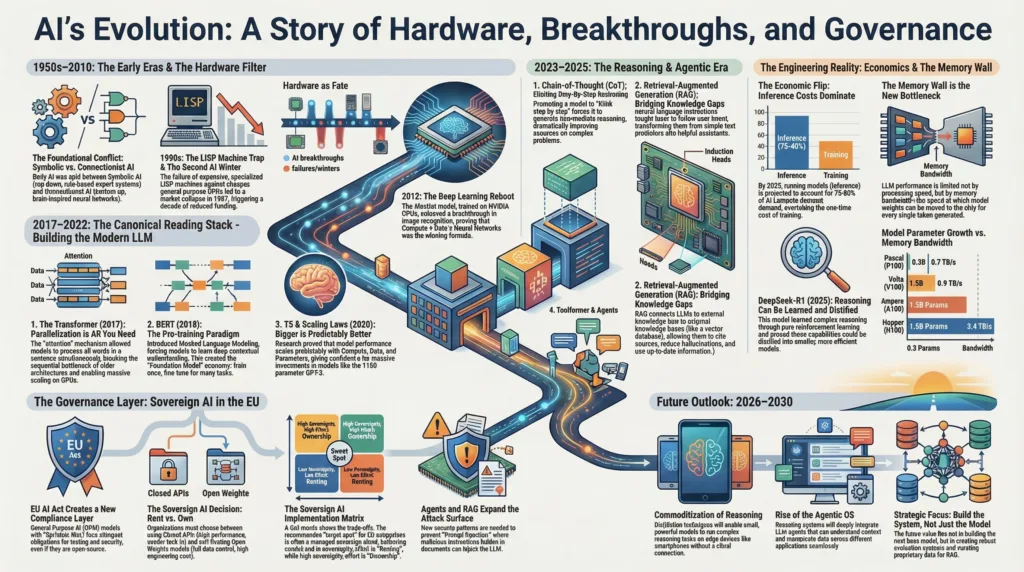
This comprehensive analysis reconstructs the history of AI through a rigorous engineering lens, demonstrating that the dominance of modern Large Language Models (LLMs) is the inevitable result of the Transformer architecture’s unique parallelizability meeting the memory bandwidth of modern GPUs. It centers on a canonical “Reading Stack”, a curated sequence of research breakthroughs from 2017 to 2025, that serves as the intellectual bedrock for modern AI. From the foundational Attention Is All You Need to the emerging reasoning paradigms of DeepSeek-R1 and Toolformer, we deconstruct the mechanisms that drive today’s frontier models.
Crucially, this report overlays a geopolitical and governance lens, specifically examining the implications for the European Union and the Netherlands. As the EU AI Act enters full force and “Sovereign AI” becomes a national security imperative, we analyze how builders must architect systems that are not only capable but compliant and resilient against supply chain shocks. The following analysis guides technical leadership through the “why” and “how” of modern AI, offering a path forward in a landscape defined by reasoning density, inference economics, and digital sovereignty.
Part I: The historical spine (1950-2017)
Engineering the Mind: From Symbols to Statistics
To understand the trajectory of modern Large Language Models, one must first understand the failures that preceded them. The history of Artificial Intelligence is often recounted as a philosophical debate, but it is more accurately understood as an engineering battle between two opposing architectures: Symbolism (logic-driven manipulation of representations) and Connectionism (data-driven statistical learning). The victor in each era was determined not by which theory was intellectually superior, but by which approach fit the available hardware constraints of the time.
1.1 The Symbolic Era and the LISP Machine Trap (1950s-1980s)
The foundational premise of AI, established at the Dartmouth workshop in 1956 1, was that intelligence could be reduced to formal symbol manipulation. The belief was that if we could encode enough rules about the world, explicit logical statements such as “IF patient has fever AND rash THEN check for infection”, a machine could mimic the decision-making process of a human expert. This era was defined by a top-down approach to intelligence, where knowledge was explicitly programmed rather than learned.
This culminated in the Expert Systems boom of the 1980s. Systems like MYCIN, developed at Stanford University, demonstrated that rule-based AI could technically outperform junior doctors in narrow diagnostics, such as identifying bacterial infections and recommending antibiotics.2 These systems functioned as vast inference engines, traversing decision trees based on thousands of hand-coded rules. However, they suffered from the “Knowledge Acquisition Bottleneck.” Every rule had to be interviewed out of a human expert and coded by a “knowledge engineer,” a process that was expensive, slow, and brittle. The systems could not handle uncertainty or ambiguity effectively; if a situation fell slightly outside the defined rules, the system failed catastrophically rather than gracefully.
The failure of Symbolic AI was largely a hardware tragedy. The industry bet heavily on LISP Machines, specialized workstations designed to run LISP (List Processing) code natively.3 LISP was the lingua franca of AI, favoring recursion and linked lists, operations that were inefficient on standard architectures of the time. Companies like Symbolics and Lisp Machines Inc. built expensive, custom hardware to support this software paradigm. However, they were fighting against the relentless economics of Moore’s Law in the commodity sector. The rise of general-purpose microprocessors (the x86 architecture) was driving down the cost of computing exponentially. While a LISP machine might cost $100,000, a standard workstation was rapidly approaching a fraction of that cost while doubling in speed every 18 months. LISP machines could not compete with the price-performance ratio of mass-produced chips. When the market for these specialized machines collapsed in 1987, it triggered the second AI Winter, a period of reduced funding and disillusionment that lasted nearly a decade.4
The lesson for the modern builder is stark: specialized hardware often loses to general-purpose hardware that benefits from massive economies of scale. Today, as we analyze the market for specialized AI inference chips (LPUs/TPUs) versus general-purpose GPUs (NVIDIA), we must remember that “commodity scale” is a gravitational force that is difficult to escape.
1.2 The Connectionist Winter and the Backpropagation Underground
While Symbolists controlled the narrative and funding during the 1960s and 70s, a separate tribe of researchers known as Connectionists labored in relative obscurity. They believed intelligence would emerge not from top-down rules but from the bottom-up interaction of simple units, modeled loosely on biological neurons. This approach, which we now call Artificial Neural Networks (ANNs), faced significant headwinds. The Perceptron, invented in 1957 by Frank Rosenblatt, was a single-layer network capable of learning simple patterns. However, in 1969, Marvin Minsky and Seymour Papert published Perceptrons, a mathematical critique that proved single-layer networks could not solve non-linear problems, such as the XOR function (exclusive OR).6 This proof effectively froze funding for neural network research for over a decade.
It wasn’t until the mid-1980s that the field saw a resurgence with the popularization of Backpropagation by Geoffrey Hinton, David Rumelhart, and Ronald Williams. Backpropagation provided a mathematical method to train multi-layer networks (which could solve XOR) by propagating error signals backward through the system to adjust weights. This solved the theoretical blockage, but practically, the networks were still almost useless. They were excruciatingly slow to train on the CPUs of the era, and there was insufficient digital data to feed them. The algorithms were ready, but the world was not.
1.3 The Statistical Turn (1990s-2010)
During the 1990s and 2000s, the field largely abandoned the lofty goal of “General Intelligence” and embraced Statistical Machine Learning.7 This was a pragmatic pivot. Instead of trying to simulate a mind, researchers focused on solvable mathematical problems using techniques like Support Vector Machines (SVMs), Random Forests, and Hidden Markov Models. These methods were mathematically elegant, theoretically bounded, and worked well on the limited datasets and hardware of the time.
This era was driven by the CPU. The sequential processing nature of CPUs suited the logical branches of decision trees and the convex optimization required by SVMs. Neural networks, which required massive parallel matrix multiplication, remained computationally intractable and were largely viewed as a curiosity. The dominant paradigm was “Feature Engineering”, humans still had to tell the model what to look at. In computer vision, for example, engineers would write code to detect edges or histograms of gradients, and the machine learning model would simply learn how to combine these human-crafted features.
1.4 The Deep Learning Reboot: The GPU Catalyst (2012)
The modern era of AI began not with a new algorithm, but with a hardware unlock. In 2012, a team from the University of Toronto, Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, entered a model named AlexNet into the ImageNet Large Scale Visual Recognition Challenge.8
AlexNet was a Convolutional Neural Network (CNN), an architecture that had been known since the 1980s (championed by Yann LeCun). The difference in 2012 was NVIDIA GPUs. The team realized that the graphical processing unit, designed to render millions of pixels in parallel for video games, was mathematically identical to the engine needed for neural networks. Both tasks require performing massive numbers of matrix multiplications simultaneously. By porting the neural network operations to two NVIDIA GTX 580 GPUs, they were able to train a deep network on 1.2 million images, a feat that would have been impossible on CPUs.
AlexNet crushed the competition, reducing error rates from 26% to 15.3%. This moment proved that Compute + Data + Backprop > Feature Engineering. It triggered the “Deep Learning Big Bang,” shifting the entire field’s focus back to neural networks. This success led directly to the massive corporate investments from Google, Facebook, and Microsoft that would eventually produce the Transformer architecture. The era of “Hardware Lottery”, where the winning algorithm is the one that fits the winning hardware, had begun in earnest.
Part II: The Canonical Reading Stack (2017-2022)
The Engineering Blueprint of Modern LLMs
The following section deconstructs the essential “Reading Stack”, the sequence of papers that moved the field from simple classification to the complex generative capabilities we see today. We analyze these not just as academic outputs, but as engineering blueprints that solved specific bottlenecks in scalability and representation.
2.1 The Transformer: Parallelization is All You Need
Anchor Paper: Attention Is All You Need (Vaswani et al., Google Brain, 2017) 10
Before 2017, Natural Language Processing (NLP) was dominated by Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs). These architectures processed text sequentially, word by word. To understand the 10th word in a sentence, the network had to have already processed the previous 9. This sequential dependency created a massive bottleneck: it made parallelization across GPUs impossible.12 You could not throw more hardware at the problem to make it go faster because the computation was inherently serial.
The Breakthrough:
The Transformer architecture discarded recurrence entirely. It introduced Self-Attention, a mechanism that allows the model to look at every word in the sentence simultaneously and calculate how much “attention” each word should pay to every other word. The paper modeled attention as a retrieval system. Every token generates three vectors:
-
Query (Q): What information am I looking for?
-
Key (K): What information do I contain?
-
Value (V): What is the content I will pass along?
The attention score is calculated by the dot product of the Query and Key vectors. This score determines how much of the Value vector is passed to the next layer. Crucially, the paper introduced Multi-Head Attention, running this process multiple times in parallel (“heads”) to capture different types of relationships (e.g., one head might track grammatical structure, another semantic similarity).10
Engineering Impact: Because attention is fundamentally just matrix multiplication, it is “embarrassingly parallel.” This meant that for the first time, training speed could scale linearly with the number of GPUs. This removed the compute ceiling that had held back NLP, enabling the era of Massive Language Models. The Transformer effectively turned language processing into a hardware problem, one that could be solved with brute force and silicon.
2.2 BERT and the Pre-training Paradigm
Anchor Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., Google, 2018) 13
While the Transformer provided the architecture, BERT (Bidirectional Encoder Representations from Transformers) defined how to train it effectively. Before BERT, models were typically trained to predict the next word in a sequence (left-to-right). This is suboptimal for understanding context because the model can’t “see” the future words in the sentence while processing the current one.
BERT introduced the concept of Masked Language Modeling (MLM). Instead of predicting the next word, BERT randomly “masked” (hid) 15% of the words in a sentence and asked the model to guess them using context from both directions (bidirectional). This forced the model to develop a deep understanding of syntax and semantics.
Compute Reality: Training BERT was a significant engineering undertaking. The base model required 4 days on 16 Cloud TPUs, with an estimated cost of around $500 at the time, though reproduction costs varied wildly and commercial training runs were much more expensive.13
Significance: BERT proved that a model pre-trained on a massive unlabeled corpus (like Wikipedia) could be “fine-tuned” on small, task-specific datasets to achieve state-of-the-art results. This created the “Foundation Model” economy: build a massive model once, and deploy it everywhere for varied tasks, from sentiment analysis to question answering.
2.3 T5 and the Limits of Transfer Learning
Anchor Paper: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., Google, 2020) 16
Following BERT, the field fractured into different architectures for different tasks (classification, translation, summarization). The T5 (Text-to-Text Transfer Transformer) paper unified these by framing every NLP task as a text-to-text problem. Whether the task was translation, classification, or regression, the input was text and the output was text.
T5 was also a study in scale. The researchers trained models up to 11 billion parameters, using the majestic C4 dataset (Colossal Clean Crawled Corpus). The paper systematically explored the “limits” of transfer learning, finding that larger models trained on more data consistently outperformed smaller ones, with no sign of saturation. This work solidified the intuition that “scale is all you need” and set the stage for the massive scaling efforts that would follow at OpenAI. The engineering overhead was immense; the largest model required slices of Google’s TPU Pods to train, pushing the boundaries of distributed computing.17
2.4 Scaling Laws: The Physics of AI
Anchor Papers:
-
Scaling Laws for Neural Language Models (Kaplan et al., OpenAI, 2020) 18
-
Language Models are Few-Shot Learners (Brown et al., OpenAI, 2020) 20
The Kaplan paper is arguably as important as the models themselves. It empirically demonstrated that model performance (measured by test loss) follows a precise Power Law with respect to three variables:
-
Compute (N): The number of floating-point operations used in training.
-
Dataset Size (D): The number of tokens the model sees.
-
Parameters (P): The number of weights in the network.
Key Finding: You can predict the performance of a massive model before you train it by training smaller versions and extrapolating the curve. This “Predictable Scaling” gave organizations like OpenAI the confidence to invest millions of dollars in a single training run. It turned AI training from a scientific experiment into an engineering capital project.
GPT-3, detailed in the Few-Shot Learners paper, was the practical application of these laws. With 175 billion parameters, it was an order of magnitude larger than anything before it. It demonstrated Zero-Shot and Few-Shot learning capabilities: the ability to perform a task it was never explicitly trained for, simply by being shown a few examples in the prompt.21 This marked the shift from “fine-tuning” (updating weights) to “prompt engineering” (designing context).
2.5 Instruction Tuning: Making Models Usable
Anchor Paper: Finetuned Language Models Are Zero-Shot Learners (Wei et al., Google, 2021) 22
GPT-3 was powerful but unruly. It functioned as a text completion engine. If you asked “What is the capital of France?”, it might reply “and what is the capital of Germany?” because it statistically predicted that the text was a list of questions.
Instruction Tuning (FLAN) solved this alignment problem. Researchers took a pre-trained model and fine-tuned it on a dataset of NLP tasks phrased as natural language instructions (e.g., “Translate this sentence to French:”, “Summarize the following text:”).
Result: The model learned to follow the intent of the user rather than just completing the pattern. This bridged the gap between a “stochastic parrot” and a helpful assistant. It is the direct precursor to the RLHF (Reinforcement Learning from Human Feedback) techniques used to create ChatGPT.
2.6 Mechanistic Interpretability: How It Actually Works
Anchor Paper: In-context Learning and Induction Heads (Olsson et al., Anthropic, 2022) 24
For years, how LLMs learned from context (In-Context Learning) was a mystery. This paper identified a specific circuit in the Transformer called the Induction Head.
-
Mechanism: An induction head looks for a previous occurrence of the current token (A) and copies the token that followed it (B) in the past.
-
Algorithm: “I see ‘Harry’, and last time I saw ‘Harry’, it was followed by ‘Potter’. So I will predict ‘Potter’.”
-
Insight: This proved that LLMs are not just memorizing statistics; they are learning algorithms for pattern matching. These heads emerge abruptly during training, marking a phase transition in the model’s capability.26
Part III: The Reasoning & Agentic Era (2023-2025)
Reasoning, Retrieval, and Efficiency
By 2023, the focus shifted from “bigger is better” to “smarter and more efficient.” The monolithic LLM began to fragment into a modular stack, incorporating reasoning loops, external tools, and retrieval mechanisms.
3.1 Chain-of-Thought: Eliciting System 2 Thinking
Anchor Paper: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., Google, 2022) 27
Standard prompting asks a model for an answer immediately. Chain-of-Thought (CoT) asks the model to “Think step by step.”
-
Effect: This forces the model to generate intermediate tokens. Since the Transformer attends to previous tokens, these intermediate steps serve as a “scratchpad,” reducing the logical leap required for the final answer. It allows the model to decompose a complex problem into manageable steps.
-
Self-Consistency: The follow-up paper Self-Consistency Improves Chain of Thought Reasoning 29 showed that sampling multiple reasoning paths and taking a majority vote significantly improves accuracy (e.g., +17.9% on the GSM8K math benchmark). This introduces the concept of “Inference-Time Compute”, spending more compute at runtime to verify and refine an answer, rather than just relying on the pre-trained weights.
3.2 RAG: The Knowledge Bridge
Anchor Paper: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al., Meta, 2020) 30
Modern Optimization: ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction (Khattab et al., 2021) 32
LLMs hallucinate and contain outdated knowledge. Retrieval-Augmented Generation (RAG) separates “memory” (parametric weights) from “knowledge” (non-parametric external database).
-
The Architecture: User Query -> Retriever (Vector Database) -> Top K Documents -> Generator (LLM) -> Answer. This allows the model to cite sources and stay current without retraining.
-
ColBERTv2: Standard RAG compresses a document into a single vector, often losing nuance (the “Lost in the Middle” phenomenon). ColBERT (Contextualized Late Interaction) keeps vectors for every token and performs a “late interaction” (MaxSim) step. This improves retrieval accuracy dramatically for complex queries, albeit with higher storage costs, making it a critical component for high-fidelity enterprise search.
3.3 Toolformer: The Agentic Interface
Anchor Paper: Toolformer: Language Models Can Teach Themselves to Use Tools (Schick et al., Meta, 2023) 34
LLMs are notoriously bad at arithmetic and lack real-time data. Toolformer taught models to use external APIs (calculators, calendars, Wikipedia) autonomously.
-
Method: It used self-supervised learning to insert API calls into text. If the API result reduced the perplexity (surprise) of the subsequent tokens, the model “learned” that the tool was useful.
-
Implication: This is the foundation of Agentic AI. The model is no longer just a text generator; it is a router and orchestrator of executable code. It marks the transition from “Chatbot” to “Agent.”
3.4 DeepSeek-R1 and the Reasoning Revolution (2025)
Anchor Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (DeepSeek-AI, 2025) 36
In early 2025, the Chinese lab DeepSeek released R1, a model that rivaled OpenAI’s o1 series. This paper is critical because it open-sourced the recipe for “System 2” reasoning.
The Mechanism: Pure RL & Cold Start
-
DeepSeek-R1-Zero: The researchers applied Reinforcement Learning (RL) directly to a base model without Supervised Fine-Tuning (SFT). The reward function was starkly simple: “Did you get the right answer?” and “Did you format it correctly?”.
-
Emergent Behavior: The model spontaneously learned to allocate “thinking time”, generating long internal monologues to verify its work before answering. It learned to self-correct errors in its chain of thought.
-
Distillation: Crucially, the paper demonstrated that the reasoning patterns of the massive R1 model could be distilled into smaller models (7B, 32B parameters).36 This democratizes reasoning, proving you don’t need a massive GPU cluster to run a reasoning model, only to train the teacher. This finding has profound implications for the economics of deployment, suggesting that high-intelligence agents can run on edge devices or smaller servers.
The training pipeline of DeepSeek-R1 reveals a novel architecture for incentives. The process begins with a Cold Start phase, where a small amount of high-quality chain-of-thought data is used to prime the model. This is followed by an intense Reasoning RL stage, where the model optimizes purely for the correct answer, developing complex internal thought processes. To make the model usable, a Supervised Fine-Tuning (SFT) stage is applied to smooth out the style, followed by a final Alignment RL stage to ensure safety and human preference compliance. This multi-stage approach contrasts with the traditional RLHF pipeline, emphasizing the generation of the reasoning process itself as the primary optimization target.
3.5 Evaluation: LLM-as-a-Judge
Anchor Paper: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena (Zheng et al., 2023) 39
As models became more capable, traditional metrics like BLEU and ROUGE became useless. They measured n-gram overlap, not meaning.
-
The Solution: Use a stronger LLM (like GPT-4) to judge the output of a weaker LLM.
-
Validation: The paper showed that GPT-4’s judgments align with human preferences over 80% of the time, matching the agreement rate between human annotators. This enables scalable, automated evaluation pipelines, a cornerstone of modern LLMOps.
Part IV: Engineering Reality, Hardware & Economics
The Tectonic Shift: From Training to Inference
The prevailing narrative of “Training Costs” ($100M+ runs) is becoming outdated. The reality of 2025 is that Inference, the cost of running these models, is dominating the economic landscape.
4.1 The Training vs. Inference Flip
By 2025, analysts project that inference will account for 75-80% of AI compute demand.40
-
Why? Once a “frontier” model (like GPT-4 or DeepSeek-V3) is trained, it is distilled into smaller, efficient models (Llama 3 8B, DeepSeek-Distill) that run on edge devices or commodity servers.
-
The Cost of Reasoning: However, “System 2” models like o1 and R1 reverse this efficiency. They trade time for accuracy. A single query might generate 10,000 “hidden” tokens of thought before producing an answer. This explodes inference costs, shifting the bottleneck from VRAM capacity to Memory Bandwidth.
4.2 The Memory Wall: Why Bandwidth is King
The limiting factor for modern LLMs is not the speed of the chip (FLOPs), but how fast data can be moved from memory to the chip (Memory Bandwidth).
-
Reference: A100 (2 TB/s) vs. H100 (3.3 TB/s).41
-
Mechanism: In the Transformer decoding step (generating text), the model must load all its weights for every single token generated. If you have a 70B parameter model (140GB), you must move 140GB of data across the wires 50 times to generate a 50-word sentence.
-
Impact: This makes “Sovereign AI” expensive. You cannot simply buy one GPU; you need an interconnect fabric (NVLink) to chain them together, which creates dependency on NVIDIA’s proprietary stack.
Part V: Governance, Geopolitics & The EU Context
Navigating the Regulatory Minefield
For European and Dutch entities, the technical stack cannot be decoupled from the legal stack. The EU AI Act creates a unique operating environment that privileges transparency and risk management over raw speed.
5.1 The EU AI Act: Systemic Risk and GPAI
The Act introduces a tiered compliance model based on risk.42
-
General Purpose AI (GPAI): Models like GPT-4 or DeepSeek-R1 are classified as GPAI. If they possess “Systemic Risk” (high impact capabilities), they face stringent obligations: adversarial testing, model evaluation, and cybersecurity protections.
-
The Open Source Exemption (and its Limits): While “open” models have exemptions, models with systemic risk do not, regardless of license. This affects how Dutch enterprises adopt open-weights models like Llama 3 or DeepSeek. You cannot simply “download and run” without assessing if your deployment triggers high-risk obligations (e.g., in critical infrastructure).
5.2 Sovereign AI: The Architecture of Autonomy
“Sovereign AI” is the strategic imperative for nations and critical industries to own their compute and data intelligence, rather than renting it from US or Chinese hyperscalers.43
The Decision Matrix: Open Weights vs. Closed API
-
Closed API (OpenAI/Anthropic):
-
Pros: Best performance, zero maintenance.
-
Cons: Data creates a “dependency loop.” You do not own the reasoning. Compliance with GDPR is harder (data leaves EU). Risk of vendor lock-in and pricing shocks.
-
Open Weights (Llama/Mistral/DeepSeek):
-
Pros: Full data sovereignty. Can run on-prem (e.g., in a TNO-secured air-gapped facility). Fine-tunable (LoRA) on proprietary data without leaks.
-
Cons: High engineering burden. Requires expensive H100 clusters.
Recommendation: For regulated sectors (Finance, Health, Gov), the Hybrid Sovereign Architecture is emerging as the standard. Use Closed APIs for generic reasoning on non-sensitive data; use specialized, fine-tuned Open Weights models (hosted in EU sovereign clouds) for sensitive core business logic.
5.3 Security: The New Attack Surface
With RAG and Agents, the attack surface expands.
-
Prompt Injection: An attacker can hide instructions in a document (e.g., a PDF resume) that, when retrieved by RAG, hijack the LLM to exfiltrate data.
-
Secure RAG Patterns: We must implement “Least Privilege” at the vector database level.45 The LLM should not have access to all documents; the Retriever must filter documents based on the user’s Access Control List (ACL) before the LLM sees them.
YearAnchor Paper or ModelLead Authors/OrganizationKey Innovation or MechanismPrimary Bottleneck Solved****Practical Impact on AI Engineering1980sExpert Systems (e.g., MYCIN)Stanford UniversitySymbolism (rule-based logic)Early medical diagnostics and narrow decision-making.Highlighted the ‘Knowledge Acquisition Bottleneck’; led to the LISP machine failure and second AI Winter.1986BackpropagationGeoffrey Hinton, David Rumelhart, Ronald WilliamsError propagation through multi-layer networksTheoretical inability of single-layer perceptrons to solve non-linear problems (XOR).Resurrected Connectionism, though performance remained limited by CPU speed and lack of data.2012AlexNetAlex Krizhevsky, Ilya Sutskever, Geoffrey Hinton (Univ. of Toronto)Convolutional Neural Network (CNN) on GPUsComputational intractability of training deep networks on CPUs.Triggered the ‘Deep Learning Big Bang’; proved that compute + data + backprop outperforms human feature engineering.2017Attention Is All You NeedVaswani et al. (Google Brain)Self-Attention / Transformer architectureSequential dependency of RNNs/LSTMs that prevented GPU parallelization.Enabled linear scaling of training speed with hardware; shifted NLP from a software problem to a brute-force hardware problem.2018BERTDevlin et al. (Google)Masked Language Modeling (MLM)Lack of deep context in unidirectional (left-to-right) training.Established the ‘Foundation Model’ economy where models are pre-trained once and fine-tuned for many tasks.2020T5Raffel et al. (Google)Unified Text-to-Text Transfer TransformerArchitectural fragmentation for different NLP tasks.Solidified the ‘scale is all you need’ intuition and pushed the boundaries of distributed computing via TPU pods.2020GPT-3 (Scaling Laws)Kaplan et al. / Brown et al. (OpenAI)Power Law scaling and Few-Shot LearningUnpredictability of model performance versus training investment.Turned AI into an engineering capital project; shifted focus from weight updates (fine-tuning) to prompt engineering.2021FLAN (Instruction Tuning)Wei et al. (Google)Finetuning on natural language instructionsAlignment; models predicting next tokens rather than following user intent.Direct precursor to RLHF and helpful AI assistants like ChatGPT.2022Chain-of-ThoughtWei et al. (Google)System 2 thinking (intermediate reasoning steps)Logical leaps in complex multi-step problems.Introduced ‘Inference-Time Compute’ where accuracy is improved by spending more compute at runtime.2023ToolformerSchick et al. (Meta)Self-supervised API usageLLM inability to perform accurate arithmetic or access real-time data.Foundation of Agentic AI; models began acting as routers and orchestrators of external code.2025DeepSeek-R1DeepSeek-AIPure RL reasoning and Knowledge DistillationHigh cost and complexity of training high-level reasoning models.Democratized reasoning; proved ‘System 2’ capabilities can be distilled into smaller, edge-compatible models.
Part VI: Future Outlook (2026-2030)
The Road to Agentic Ubiquity
As we look toward 2030, the “Reading Stack” suggests a clear trajectory.
-
Commoditization of Reasoning: DeepSeek-R1 proved that high-level reasoning can be distilled into small models. By 2026, we will see “Reasoning-on-Edge”, smartphones running quantized 3B parameter models that can solve complex logic puzzles without cloud connection.
-
The Agentic OS: Operating systems will integrate LLMs deeply (e.g., “Microsoft Fara” or Apple Intelligence). The “file” and the “application” will blur as Agents manipulate data directly across silos.
-
Governance as Code: Compliance will move from PDF checklists to “Policy as Code”.47 Guardrails will be enforceable at the router level, preventing agents from taking actions that violate EU norms.
Strategic Recommendation:
Do not over-rotate on building “your own GPT-5.” The base model is a commodity. The value lies in the Evaluation Stack (building “LLM-as-a-Judge” to measure quality 39) and the Proprietary Data RAG (curating the unique knowledge your organization owns). Build the system around the model, not just the model itself.
Conclusion
The journey from 1950s Symbolic AI to 2025’s Reasoning LLMs is a story of hardware enabling theory. We have moved from the brittle logic of the LISP machine to the fluid, self-correcting reasoning of the GPU cluster. For the builder and the board member alike, success now depends on mastering this stack, understanding the papers, respecting the compute physics, and navigating the sovereign landscape with precision.
Geciteerd werk
-
History of artificial intelligence, Wikipedia, geopend op december 20, 2025, https://en.wikipedia.org/wiki/History_of_artificial_intelligence
-
The History of Artificial Intelligence, IBM, geopend op december 20, 2025, https://www.ibm.com/think/topics/history-of-artificial-intelligence
-
Remember Lisp Machines? A Friendly Throwback to AI’s Forgotten Supercomputers!, geopend op december 20, 2025, https://www.aiinnovationsunleashed.com/remember-lisp-machines-a-friendly-throwback-to-ais-forgotten-supercomputers/
-
AI Winter: Understanding the Cycles of AI Development, DataCamp, geopend op december 20, 2025, https://www.datacamp.com/blog/ai-winter
-
AI winter, Wikipedia, geopend op december 20, 2025, https://en.wikipedia.org/wiki/AI_winter
-
Logical or Connectionist AI?, LessWrong, geopend op december 20, 2025, https://www.lesswrong.com/posts/juomoqiNzeAuq4JMm/logical-or-connectionist-ai
-
2018: The year that artificial intelligence came of age, Math Scholar, geopend op december 20, 2025, https://mathscholar.org/2018/12/2018-the-year-that-artificial-intelligence-came-of-age/
-
Chapter: 2 Definitions and Perspectives, geopend op december 20, 2025, https://www.nationalacademies.org/read/27092/chapter/4
-
Current Status and Future Directions of Deep Learning Applications for Safety Management in Construction, MDPI, geopend op december 20, 2025, https://www.mdpi.com/2071-1050/13/24/13579
-
Attention Is All You Need, Wikipedia, geopend op december 20, 2025, https://en.wikipedia.org/wiki/Attention_Is_All_You_Need
-
Attention is All you Need, NIPS papers, geopend op december 20, 2025, https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdf
-
I Finally Understood “Attention is All You Need” After So Long. Here’s How I Did It., geopend op december 20, 2025, https://ai.plainenglish.io/i-finally-understood-attention-is-all-you-need-after-so-long-heres-how-i-did-it-263b46273f9f
-
BERT (language model), Wikipedia, geopend op december 20, 2025, https://en.wikipedia.org/wiki/BERT_(language_model)
-
How to Train BERT with an Academic Budget, ACL Anthology, geopend op december 20, 2025, https://aclanthology.org/2021.emnlp-main.831.pdf
-
[D] Cheapest way to pre-train BERT from scratch? : r/MachineLearning, Reddit, geopend op december 20, 2025, https://www.reddit.com/r/MachineLearning/comments/hp691q/d_cheapest_way_to_pretrain_bert_from_scratch/
-
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Journal of Machine Learning Research, geopend op december 20, 2025, https://jmlr.org/papers/volume21/20-074/20-074.pdf
-
Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer, geopend op december 20, 2025, https://research.google/blog/exploring-transfer-learning-with-t5-the-text-to-text-transfer-transformer/
-
Explaining neural scaling laws, PNAS, geopend op december 20, 2025, https://www.pnas.org/doi/10.1073/pnas.2311878121
-
Scaling Laws for Neural Language Models, arXiv, geopend op december 20, 2025, https://arxiv.org/pdf/2001.08361
-
OpenAI’s GPT-3 Language Model: A Technical Overview, Lambda, geopend op december 20, 2025, https://lambda.ai/blog/demystifying-gpt-3
-
GPT-3, Wikipedia, geopend op december 20, 2025, https://en.wikipedia.org/wiki/GPT-3
-
Finetuned Language Models are Zero-Shot Learners, OpenReview, geopend op december 20, 2025, https://openreview.net/forum?id=gEZrGCozdqR
-
[2109.01652] Finetuned Language Models Are Zero-Shot Learners, arXiv, geopend op december 20, 2025, https://arxiv.org/abs/2109.01652
-
In-context Learning and Induction Heads | alphaXiv, geopend op december 20, 2025, https://www.alphaxiv.org/overview/2209.11895v1
-
In-context Learning and Induction Heads, Transformer Circuits Thread, geopend op december 20, 2025, https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
-
Understanding LLMs: Insights from Mechanistic Interpretability, LessWrong, geopend op december 20, 2025, https://www.lesswrong.com/posts/XGHf7EY3CK4KorBpw/understanding-llms-insights-from-mechanistic
-
Chain-of-Thought Reasoning Example with Granite, IBM, geopend op december 20, 2025, https://www.ibm.com/think/tutorials/llm-chain-of-thought-reasoning-granite
-
Unpacking chain-of-thought prompting: a new paradigm in AI reasoning, Toloka AI, geopend op december 20, 2025, https://toloka.ai/blog/unpacking-chain-of-thought-prompting-a-new-paradigm-in-ai-reasoning/
-
Self-Consistency Improves Chain of Thought Reasoning in Language Models, arXiv, geopend op december 20, 2025, https://arxiv.org/pdf/2203.11171
-
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, geopend op december 20, 2025, https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
-
“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” Summary, Medium, geopend op december 20, 2025, https://medium.com/@dminhk/retrieval-augmented-generation-for-knowledge-intensive-nlp-tasks-summary-fc6dc7c4900e
-
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction, Hugging Face, geopend op december 20, 2025, https://huggingface.co/papers/2112.01488
-
[Quick Review] ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction, geopend op december 20, 2025, https://liner.com/review/colbertv2-effective-and-efficient-retrieval-via-lightweight-late-interaction?entry-type=quick_review_inventory
-
Toolformer: Language Models Can Teach Themselves to Use Tools, ResearchGate, geopend op december 20, 2025, https://www.researchgate.net/publication/368392996_Toolformer_Language_Models_Can_Teach_Themselves_to_Use_Tools
-
[Quick Review] Toolformer: Language Models Can Teach Themselves to Use Tools, Liner, geopend op december 20, 2025, https://liner.com/review/toolformer-language-models-can-teach-themselves-to-use-tools
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv, geopend op december 20, 2025, https://arxiv.org/pdf/2501.12948
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, geopend op december 20, 2025, https://arxiv.org/abs/2501.12948
-
How DeepSeek R1 Works: Explaining All Its Key Components and Their Consequences, geopend op december 20, 2025, https://www.pedromebo.com/blog/en-how-deepseek-r1-works
-
[2306.05685] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, arXiv, geopend op december 20, 2025, https://arxiv.org/abs/2306.05685
-
building the backbone of AI., Brookfield, geopend op december 20, 2025, https://www.brookfield.com/sites/default/files/documents/Brookfield_Building_the_Backbone_of_AI.pdf
-
NVIDIA Hopper Architecture In-Depth | NVIDIA Technical Blog, geopend op december 20, 2025, https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
-
High-level summary of the AI Act | EU Artificial Intelligence Act, geopend op december 20, 2025, https://artificialintelligenceact.eu/high-level-summary/
-
Acknowledgement, VentureNet, geopend op december 20, 2025, https://venturenet.no//uploads/sites/38/2025/08/INN-the-Loop-Article-v3.2.pdf
-
AI Sovereignty, A strategic Imperative for European Industry 2025, Italia nel futuro, geopend op december 20, 2025, https://italianelfuturo.com//uploads/2025/09/Roland_Berger_AI-sovereignty.pdf
-
Secure RAG: Enterprise Architecture Patterns for Accurate, Leak-Free AI, geopend op december 20, 2025, https://petronellatech.com/blog/secure-rag-enterprise-architecture-patterns-for-accurate-leak-free-ai/
-
Guidance for Securing Sensitive Data in RAG Applications using Amazon Bedrock, geopend op december 20, 2025, https://aws-solutions-library-samples.github.io/ai-ml/securing-sensitive-data-in-rag-applications-using-amazon-bedrock.html
-
Top 12 Policy as Code (PaC) Tools in 2025, Spacelift, geopend op december 20, 2025, https://spacelift.io/blog/policy-as-code-tools
Presentatie: From symbolic AI to reasoning LLMs
From symbolic AI to reasoning LLMs
Presentatie: From symbolic AI to reasoning LLMs (companion)
From symbolic AI to reasoning LLMs (companion)
From symbolic AI to reasoning LLMs (1950-2025).
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.