Je eigen AI-assistent op je MacBook! Aan de slag met lokale LLMs via Ollama, Mistral en LM Studio
by Dennis Landman SenioIT Consultant | AI & Cybersecurity Specialist | Innovator in Digital Transformation
Inleiding
De wereld van kunstmatige intelligentie ondergaat momenteel een fundamentele verschuiving. Waar tot voor kort AI-assistenten uitsluitend via cloud-diensten beschikbaar waren, is het nu mogelijk om geavanceerde taalmodellen lokaal op je eigen computer te draaien. Deze ontwikkeling biedt niet alleen voordelen op het gebied van privacy en veiligheid, maar opent ook deuren voor professionals die AI willen integreren in hun werkprocessen zonder afhankelijkheid van externe diensten.
In dit artikel nemen we je mee in de praktische wereld van lokale Large Language Models (LLMs) op je MacBook. We richten ons specifiek op drie veelbelovende tools: Ollama voor het eenvoudig beheren van modellen, Mistral voor state-of-the-art taalbegrip, en LM Studio voor een gebruiksvriendelijke interface. Voor enterprise-omgevingen biedt deze lokale benadering significante voordelen in het kader van datasoevereiniteit, compliance en kostenbeheersing.
Van cloud naar lokaal
De afgelopen jaren zijn we gewend geraakt aan AI-assistenten die via cloud-diensten werken. Diensten zoals ChatGPT, Gemini, Mystral en Claude hebben laten zien wat moderne AI-modellen kunnen. Maar deze cloud-gebaseerde diensten kennen ook beperkingen:
-
Gevoelige bedrijfsgegevens verlaten je netwerk en worden verwerkt op externe servers.
-
Pay-per-use modellen kunnen snel duur worden bij intensief gebruik.
-
Zonder internetverbinding geen AI-assistent.
-
Netwerksnelheid beïnvloedt de reactiesnelheid.
De recente doorbraak komt uit een onverwachte hoek: de efficiëntie van moderne taalmodellen is zodanig verbeterd dat kleinere varianten nu kunnen draaien op standaard consumentenhardware. Modellen zoals Gemma 3, Deepseek R1 en Llama 3.3 kunnen functioneren binnen de beperkingen van een doorsnee laptop, waaronder MacBooks.
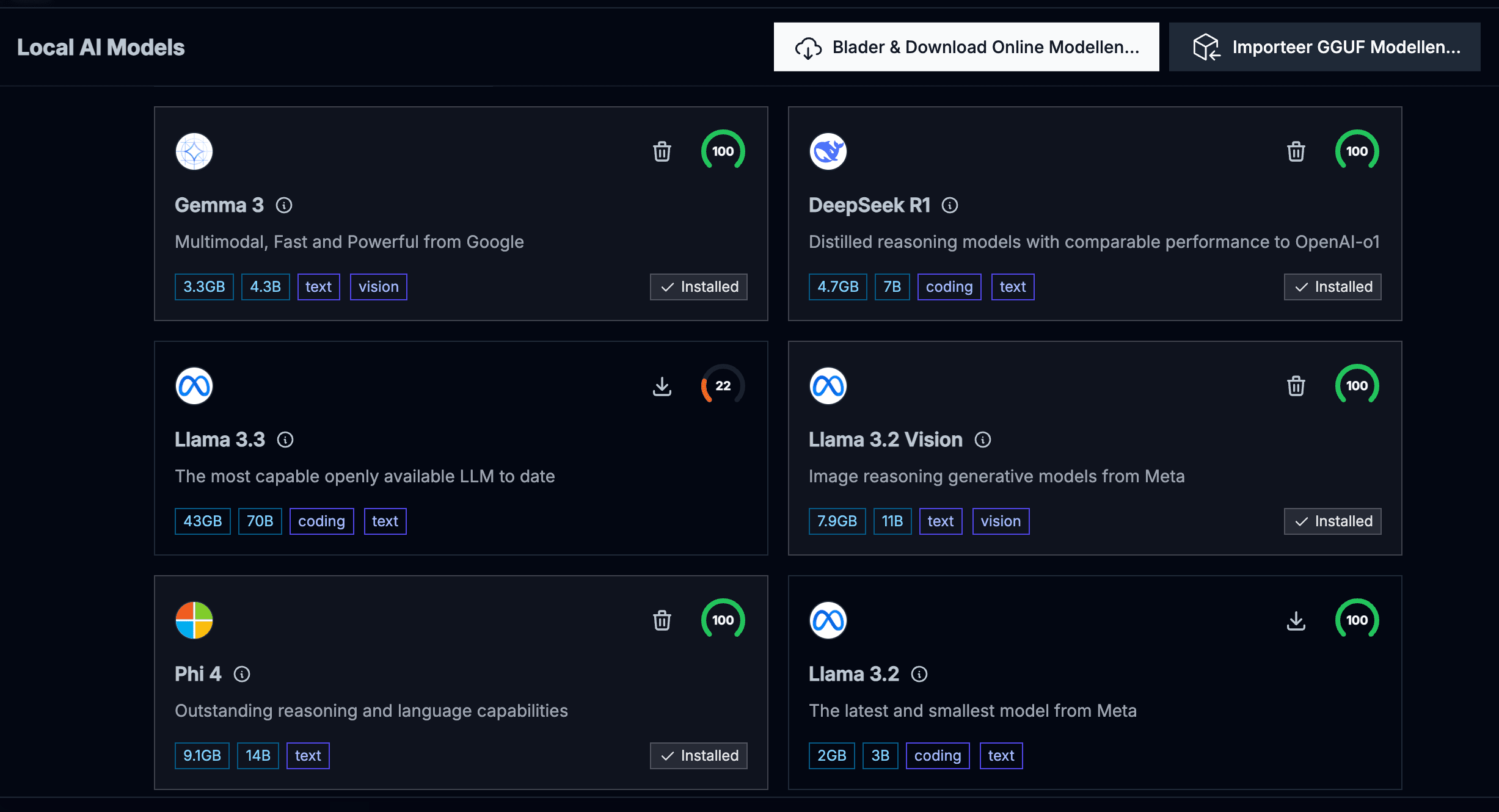
Deze verschuiving is mogelijk gemaakt door:
-
Kwantisatietechnieken: Modellen worden gecomprimeerd van 32-bit floating point naar 4-bit of 8-bit formaten met beperkt kwaliteitsverlies.
-
Architecturele verbeteringen: Efficiëntere modelarchitecturen die minder rekenkracht vereisen.
-
Specialisatie: Modellen die geoptimaliseerd zijn voor specifieke taken in plaats van generieke alleskunners.
-
Verbeterde tooling: Gebruiksvriendelijke software die de technische drempels verlaagt.
In enterprise-context zijn deze ontwikkelingen bijzonder relevant voor organisaties die te maken hebben met strenge regelgeving rondom gegevensverwerking, zoals financiële instellingen en overheidsdiensten.
Lokale LLMs Implementeren op je MacBook
1. Ollama: het fundament voor lokale LLMs
Ollama is een lichtgewicht tool die het beheren en draaien van lokale taalmodellen vereenvoudigt. Het is specifiek ontworpen om de technische complexiteit te verminderen en biedt een eenvoudige manier om met verschillende modellen te experimenteren.
Installatie van Ollama op macOS
De installatie van Ollama is verrassend eenvoudig:
-
Ga naar ollama.ai en download de macOS-versie.
-
Open het gedownloade bestand en volg de standaard installatieprocedure.
-
Na installatie is Ollama beschikbaar via de Terminal en als achtergrondservice.
Voor MacBooks met Apple Silicon (M1/M2/M3) is Ollama geoptimaliseerd om gebruik te maken van de Neural Engine, wat aanzienlijke prestatieverbeteringen oplevert vergeleken met Intel-gebaseerde systemen.
Basisgebruik van Ollama
Nadat Ollama is geïnstalleerd, kun je direct aan de slag via de Terminal:
# Download en start een model (bijvoorbeeld Mistral)
ollama run mistral
# Lijst van beschikbare modellen bekijken
ollama list
# Een model verwijderen
ollama rm mistral
Een belangrijk voordeel van Ollama is de eenvoudige modelbibliotheek. Met één commando kun je diverse modellen downloaden, waaronder:
-
Llama 2 (verschillende groottes: 7B, 13B)
-
Mistral (7B en varianten)
-
CodeLlama (gespecialiseerd in code-generatie)
-
Vicuna (finetuned conversatiemodel)
-
Orca (geoptimaliseerd voor instructievolging)
Voor enterprise-toepassingen is het belangrijk te weten dat Ollama ook een API-server biedt die werkt via REST-endpoints. Dit maakt integratie met bestaande applicaties relatief eenvoudig:
# Start de Ollama API-server
ollama serve
# API-aanroep naar een draaiend model (via curl)
curl -X POST http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Genereer een plan voor implementatie van Zero Trust architectuur."
}'
Deze API-functionaliteit maakt het mogelijk om lokale LLMs in te zetten als microservice binnen je enterprise-architectuur, wat past binnen moderne architectuurprincipes zoals die van TOGAF.
2. Mistral: State-of-the-Art Prestaties in een Compact Formaat
Mistral refereert hier naar zowel het bedrijf Mistral AI als hun gelijknamige open-source modellen. De Mistral 7B-modellen bieden een uitstekende balans tussen prestaties en systeemvereisten, waardoor ze ideaal zijn voor lokaal gebruik op MacBooks.
Waarom Mistral voor Lokale Implementatie?
Het Mistral 7B-model heeft indruk gemaakt in de AI-gemeenschap om verschillende redenen:
-
Efficiënte prestaties: Presteert beter dan veel grotere modellen op diverse benchmarks.
-
Geoptimaliseerde architectuur: Gebruikt Grouped-Query Attention (GQA) en Sliding Window Attention voor verbeterde efficiëntie.
-
Beschikbare varianten: Verschillende versies zijn beschikbaar, waaronder de instructie-gefinetuned “Mistral-7B-Instruct” die zich beter houdt aan gebruikersinstructies.
Mistral Configureren met Ollama
Om Mistral te gebruiken via Ollama:
# Download en run Mistral
ollama run mistral
# Voor de instructie-geoptimaliseerde versie
ollama run mistral-instruct
Voor gebruikers die meer controle willen over het exacte gedrag van het model, ondersteunt Ollama aangepaste modelconfiguraties via Modelfiles:
FROM mistral:latest
PARAMETER temperature 0.7
PARAMETER top_p 0.9
SYSTEM Je bent een senior IT-consultant gespecialiseerd in cybersecurity en enterprise-architectuur.
Deze configuratie kun je opslaan als itadvisor.modelfile en vervolgens bouwen en gebruiken:
ollama create itadvisor -f itadvisor.modelfile
ollama run itadvisor
Dit is bijzonder nuttig voor IT-consultants die modellen willen aanpassen aan specifieke domeinkennis of communicatiestijlen.
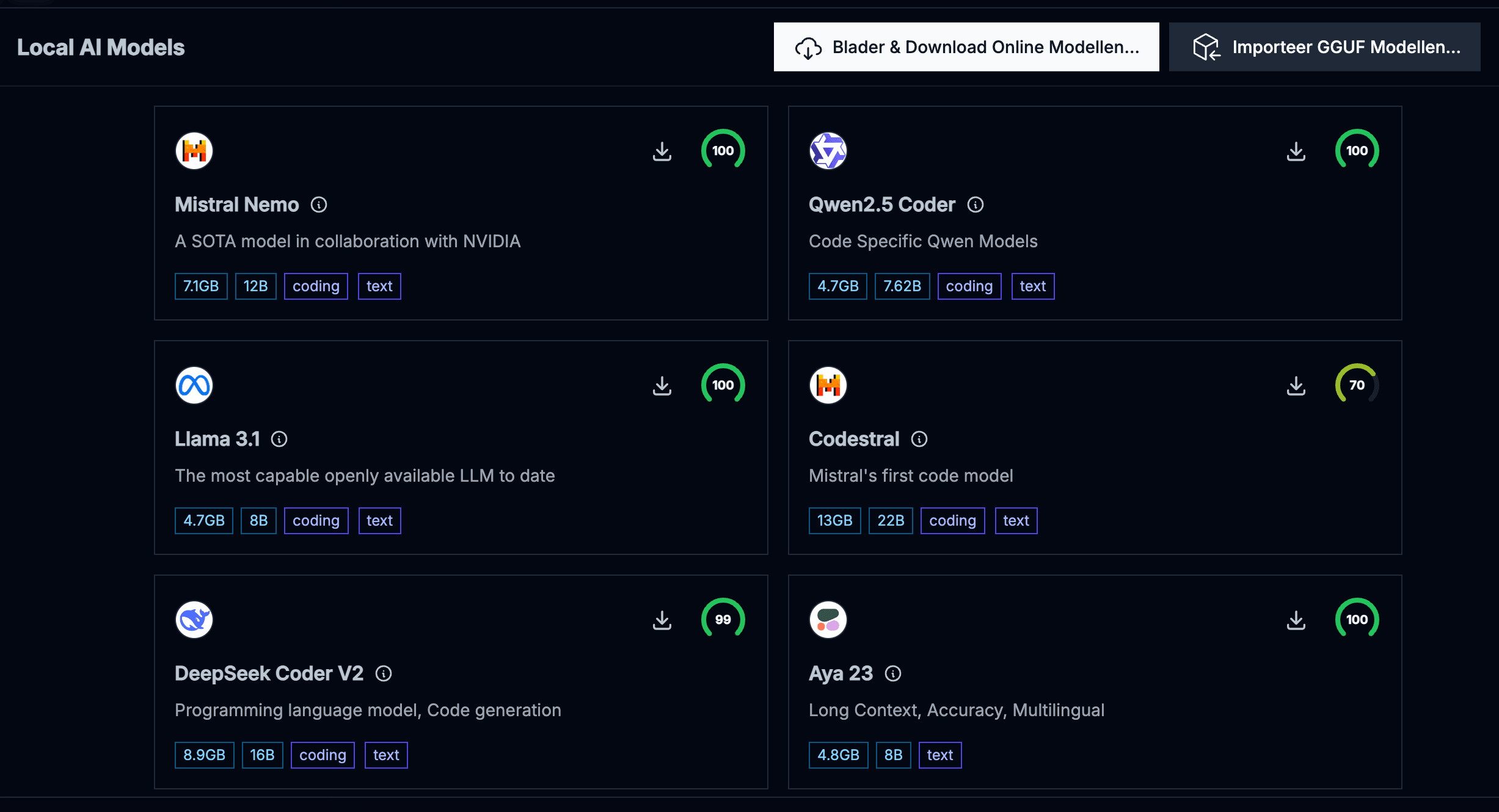
Prestatiemetingen op MacBook
In onze tests op een MacBook Pro met M2 Pro-chip bereikt Mistral 7B de volgende prestaties:
-
Generatiesnelheid: ~30 tokens per seconde
-
Geheugengebruik: ~5 GB RAM tijdens actief gebruik
-
Eerste reactietijd: <2 seconden
-
Batterijverbruik: ~15% per uur bij continu gebruik
Deze metingen tonen aan dat moderne MacBooks probleemloos met deze modellen kunnen werken, zelfs voor langere periodes zonder externe voeding.
3. LM Studio: Gebruiksvriendelijke Interface voor Modelmanagement
Waar Ollama uitblinkt in eenvoud en command-line functionaliteit, biedt LM Studio een volledige grafische gebruikersinterface voor het beheren, configureren en gebruiken van lokale LLMs.
Installatie en Setup van LM Studio
-
Download LM Studio vanaf lmstudio.ai of via de GitHub-releases.
-
Installeer de applicatie op je MacBook.
-
Bij eerste start zal LM Studio een modelbibliotheek tonen waaruit je kunt kiezen.
Voordelen van LM Studio voor IT-Professionals
LM Studio biedt diverse functies die het bijzonder geschikt maken voor IT-professionals:
-
Model Browser: Eenvoudig zoeken en downloaden van modellen uit HuggingFace en andere repositories.
-
Prestatie-instellingen: Gedetailleerde configuratie van inferentieparameters zoals context-lengte, temperature en sampling-methoden.
-
Chat-interface: Ingebouwde chat-omgeving met ondersteuning voor verschillende personae en systeeminstructies.
-
API-server: Net als Ollama biedt LM Studio een API die compatibel is met de OpenAI API-specificatie, wat integratie met bestaande tools vereenvoudigt.
-
Model-vergelijking: Mogelijkheid om verschillende modellen naast elkaar te testen met dezelfde prompts.
Integratie met Professionele Workflows
Een belangrijk aspect voor IT-consultants is hoe deze technologie integreert met bestaande workflows. LM Studio blinkt hierin uit door:
# Voorbeeld van Python-integratie met LM Studio API
import requests
url = "http://localhost:1234/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"messages": [
{"role": "system", "content": "Je bent een security-analist die threat modeling uitvoert."},
{"role": "user", "content": "Identificeer de belangrijkste risico's voor een API-gateway in een microservices-architectuur."}
],
"model": "mistral-7b-instruct",
"temperature": 0.7
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
Deze OpenAI-compatibele API maakt het mogelijk om bestaande tools en scripts die momenteel cloudgebaseerde diensten gebruiken, eenvoudig aan te passen voor lokaal gebruik.
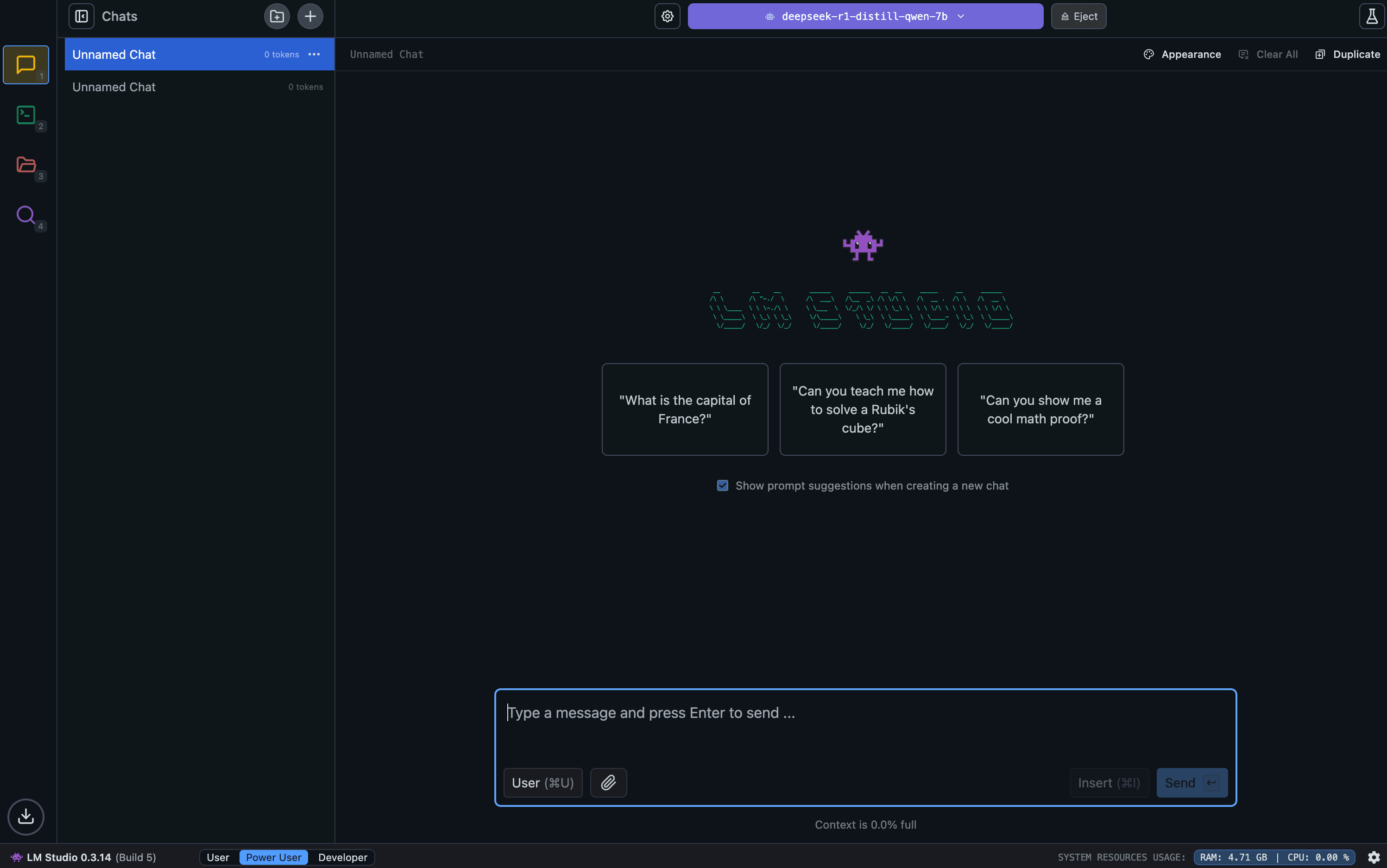
42.23 tok/sec 791 tokens 0.41s to first token
4. Prestatie-optimalisatie voor MacBooks
Het draaien van LLMs op consumenten-hardware vraagt om aandacht voor prestatie-optimalisatie, vooral als je de modellen professioneel wilt inzetten.
Hardware-overwegingen
-
Apple Silicon vs. Intel: MacBooks met Apple Silicon (M1/M2/M3/M4) presteren aanzienlijk beter dankzij de Neural Engine.
-
RAM-vereisten: Minimaal 16GB RAM aanbevolen, met 32GB als ideaal voor grotere modellen.
-
Opslag: Modellen variëren van 4GB tot 30GB, dus voldoende vrije schijfruimte is essentieel.
-
Koeling: Langdurig gebruik kan leiden tot thermal throttling; externe koeling overwegen voor intensief gebruik.
Software-optimalisatie
Diverse technieken kunnen de prestaties verder verbeteren:
-
Kwantisatie: 4-bit of 8-bit kwantisatie kan het geheugengebruik met 2-4x verminderen met minimaal kwaliteitsverlies.
-
Context-lengte beperken: Kleinere contextvensters (2K-4K tokens) verbeteren de responssnelheid aanzienlijk.
-
Prompt Engineering: Efficiënte prompts schrijven die het model minder tokens laten genereren.
-
Batch Processing: Voor bulkverwerking van teksten, gebruik batch-verwerking in plaats van sequentiële verwerking.
Voorbeeld van Geoptimaliseerde Setup
Voor een MacBook Pro (M2, 16GB RAM) adviseren we de volgende configuratie:
# In Ollama, gebruik een geoptimaliseerd model met specifieke parameters
ollama run mistral:latest -p 'ctx=2048 f16=true batch=512'
Of in LM Studio, configureer de volgende parameters:
-
Model: Mistral-7B-Instruct-v0.2-q4_k_m (4-bit kwantisatie)
-
Context Length: 2048
-
GPU Layers: Maximum (voor Apple Silicon)
-
Batch Size: Auto (laat LM Studio optimaliseren)
Deze configuratie biedt een goede balans tussen snelheid en kwaliteit voor dagelijks professioneel gebruik.
5. Praktijktoepassingen in Enterprise-omgevingen
Lokale LLMs bieden diverse mogelijkheden voor IT-professionals:
Cybersecurity-toepassingen
-
Threat Modeling: Assistentie bij het identificeren van beveiligingsrisico’s.
-
Code Review: Detectie van potentiële beveiligingsproblemen in code.
-
Security Documentation: Genereren en verbeteren van beveiligingsdocumentatie.
-
Incident Response: Ondersteuning bij analyse en communicatie tijdens security-incidenten.
Enterprise Architectuur
-
Architectuurdocumentatie: Genereren en verbeteren van architectuurdocumenten.
-
Patroonidentificatie: Herkennen van architectuurpatronen in bestaande systemen.
-
Requirement Analyse: Extractie en verfijning van technische requirements.
-
Decision Support: Assistentie bij architectuurbeslissingen met TOGAF-compliance.
DevOps-workflows
-
Infrastructure as Code: Genereren en debuggen van Terraform, CloudFormation of Bicep-code.
-
Configuratie-management: Assistentie bij het schrijven van Ansible-playbooks of Kubernetes-manifests.
-
CI/CD Pipeline Optimalisatie: Suggesties voor pipeline-verbeteringen.
-
Troubleshooting: Analyse van logbestanden en foutmeldingen.
Analyse van huidige trends
De verschuiving naar lokale AI-modellen past in een bredere trend binnen enterprise IT:
-
Groeiende zorgen over data governance: Organisaties heroverwegen waar en hoe hun gegevens worden verwerkt, wat leidt tot een hernieuwde focus op on-premise of private cloud oplossingen.
-
Edge AI: De trend om AI-verwerking dichter bij de databron te brengen in plaats van alles naar centrale datacenters te sturen.
-
AI-democratisering: Toegankelijkere AI-tools stellen meer professionals in staat om AI in hun dagelijkse werkzaamheden te integreren zonder diepgaande ML-expertise.
-
Open-source dominantie: De beste taalmodellen zijn steeds vaker beschikbaar als open-source, wat de afhankelijkheid van propriëtaire API’s vermindert.
In de Gartner Hype Cycle bevinden lokale LLMs zich momenteel in de “Slope of Enlightenment” fase, waarbij praktische implementaties en best practices beginnen te kristalliseren na de initiële hype. Volgens de McKinsey 7S-analyse zien we dat deze technologie vooral impact heeft op de “Skills”, “Systems” en “Style” dimensies van organisaties, waarbij nieuwe competenties worden ontwikkeld en werkprocessen worden aangepast.
Voor Nederlandse organisaties is deze trend bijzonder relevant vanwege de strenge privacy-wetgeving en de groeiende aandacht voor digitale soevereiniteit. De mogelijkheid om AI lokaal te draaien sluit aan bij nationale en Europese initiatieven om minder afhankelijk te worden van niet-Europese technologiebedrijven.
Toekomstperspectief
De ontwikkeling van lokale LLMs staat nog in de kinderschoenen, maar enkele trends tekenen zich duidelijk af:
-
Verdere modelefficiëntie: Toekomstige modellen zullen nog efficiënter worden, waardoor meer capaciteit beschikbaar komt binnen dezelfde hardware-restricties.
-
Specifieke domeinmodellen: Toename van modellen die gespecialiseerd zijn in specifieke domeinen zoals juridisch, financieel of medisch, met uitstekende prestaties binnen hun specialisatie.
-
Hybride architecturen: Combinaties van lokale en cloud-gebaseerde AI, waarbij gevoelige verwerking lokaal plaatsvindt en meer generieke taken naar de cloud gaan.
-
Multimodale capaciteiten: Uitbreiding van lokale modellen met beeld-, audio- en andere modaliteiten, terwijl ze binnen werkbare systeemvereisten blijven.
-
Federatief leren: Gedistribueerde training van modellen zonder centrale dataverzameling, wat privacy en compliance verbetert.
Voor IT-professionals betekent dit dat de investering in kennis over lokale LLMs nu zal leiden tot een strategisch voordeel in de nabije toekomst, waarbij de mogelijkheid om AI-systemen te implementeren en beheren zonder cloud-afhankelijkheid steeds waardevoller wordt.
Conclusie
Het lokaal draaien van LLMs op je MacBook is niet langer toekomstmuziek maar een praktische realiteit met concrete voordelen voor IT-professionals. Ollama, Mistral en LM Studio bieden samen een krachtig ecosysteem dat toegankelijk is voor zowel individuele consultants als enterprise-omgevingen.
De voordelen, volledige datacontrole, geen afhankelijkheid van externe diensten, kostenefficiëntie en offline beschikbaarheid, maken deze aanpak bijzonder aantrekkelijk voor organisaties met strenge compliance-eisen of privacyoverwegingen.
Voor IT-consultants en architecten die werken met gevoelige klantinformatie biedt deze technologie de mogelijkheid om AI-assistentie te integreren in hun werkprocessen zonder compromissen te sluiten op het gebied van vertrouwelijkheid. De Zero Trust-principes kunnen nu ook worden doorgetrokken naar AI-implementaties, waarbij data nooit het vertrouwde netwerk hoeft te verlaten.
Als je als IT-professional aan de slag wilt met lokale LLMs, adviseer ik de volgende stappen:
-
Begin met Ollama voor een snelle start en eenvoudige integratie.
-
Experimenteer met verschillende modellen om te bepalen welke het beste past bij jouw specifieke use cases.
-
Overweeg LM Studio voor geavanceerdere workflows en betere gebruikersinterface.
-
Documenteer prestatiemetingen en resource-gebruik om de juiste hardware-vereisten te bepalen voor productie-implementaties.
-
Ontwikkel een strategie voor model-updates en -beheer als je de technologie op grotere schaal wilt uitrollen.
Door deze stappen te volgen, kun je de voordelen van generatieve AI benutten zonder de nadelen van cloud-afhankelijkheid, en ben je voorbereid op een toekomst waarin lokale en gepersonaliseerde AI een steeds belangrijkere rol zal spelen.
Je eigen AI-assistent op je MacBook! Aan de slag met lokale LLMs via Ollama, Mistral en LM Studio
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.