The kinetic convergence a unified theory of AI-native product engineering and operating model evolution
Summary
The contemporary enterprise stands at the precipice of a structural transformation that renders traditional maturity models and linear engineering paradigms obsolete. We are witnessing the simultaneous collision of two tectonic shifts: the ascent of AI-Native Product Engineering where the fundamental unit of value creation migrates from manual implementation to agentic orchestration and the emergence of the Kinetic Enterprise, a non-linear operating model characterized by dynamic, recursive loops rather than static hierarchies. This convergence represents a fundamental “Great Flattening” of the decision-making stack, compressing the distance between strategic intent and technical execution.1
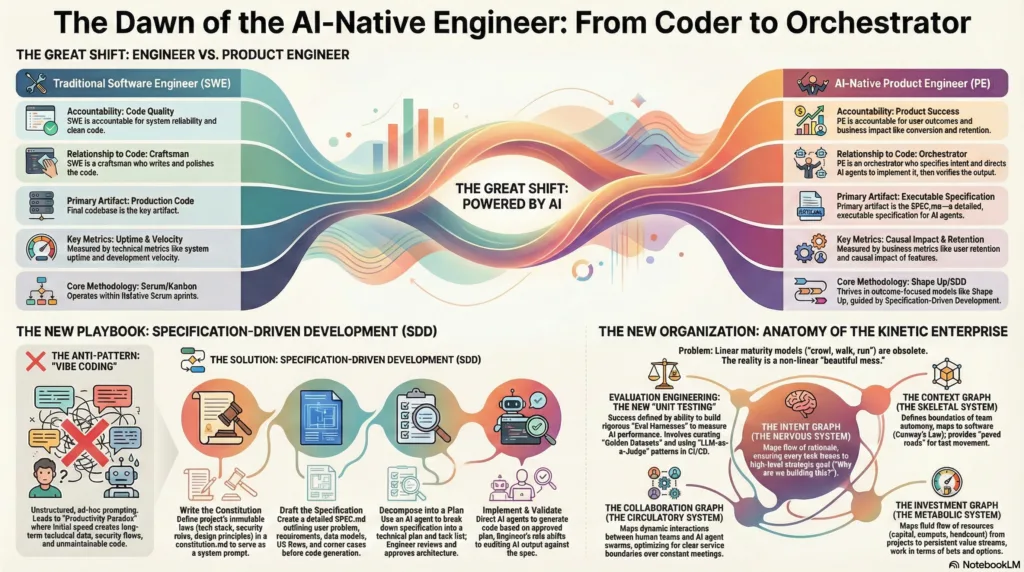
This report synthesizes extensive research into a unified thesis: that the adoption of autonomous reasoning agents (System 2 AI) forces organizations to abandon “feature factory” dynamics in favor of Specification-Driven Development (SDD) and Outcome-Based Architectures. The “Product Engineer” (PE) has emerged as the dominant archetype in this new regime, tasked not with writing syntax, but with architecting the “Intent Graph” of the organization.1
Drawing from a corpus of 141 discrete research artifacts spanning deep technical analysis of reasoning engines, search transformation studies, and operating model frameworks this document provides a comprehensive blueprint for this transition. It argues that the “Productivity Paradox” of AI (where more code leads to more technical debt) can only be resolved by mastering the tension between the probabilistic nature of AI (requiring Trust Engineering and Evaluation Harnesses) and the deterministic requirements of enterprise governance (requiring the “Four Graphs” of the Kinetic Enterprise).1
The following analysis details the “physics” of the new intelligence stack, the specific competencies of the AI-Native workforce, the operational rituals of the Kinetic Enterprise, and the economic imperatives of the agentic era.
Chapter 1: The Epistemic Shift and the Great Flattening
The discipline of software engineering is currently navigating its most significant structural transformation since the codification of the Agile Manifesto in 2001. However, unlike previous shifts which were primarily methodological (Waterfall to Agile) or infrastructural (On-premise to Cloud), this shift is epistemic. It fundamentally alters the nature of knowledge work and the economic logic of software production.1
1.1 The Collapse of the Implementation Layer
Historically, the primary bottleneck in software value delivery was implementation the manual translation of business logic into executable syntax. This constraint dictated the structure of the engineering organization, necessitating large teams of individual contributors managed through rigid ticketing systems (e.g., JIRA) to optimize “velocity” and “throughput”.1 The value of an engineer was largely proxied by their fluency in syntax and their ability to recall standard library functions.
The rapid maturation of Large Language Models (LLMs) and, more specifically, Large Reasoning Models (LRMs), has commoditized this implementation layer. Tools capable of generating boilerplate, refactoring legacy code, and executing standard algorithms have reduced the marginal cost of syntax generation to near zero.1 Consequently, value has migrated upstream to specification (the rigorous definition of system intent) and downstream to verification (the automated evaluation of outcomes).1
This phenomenon drives “The Great Flattening,” a theoretical component of the Operating Model Evolution Research Framework.2 As the decision-making stack compresses, the traditional hierarchical enterprise architecture fractures. The distinction between “Product Manager” (who defines the what) and “Software Engineer” (who defines the how) is collapsing into the singular role of the Product Engineer, who owns the entire vertical slice of value creation.1 In this flattened structure, the “middle management” layer, traditionally responsible for translation between business intent and technical execution, faces obsolescence unless it evolves into a layer of “Context Engineering” and “System Architecture”.4
1.2 The Productivity Paradox
A critical finding in the research is the emergence of a “Productivity Paradox.” While AI tools like GitHub Copilot allow developers to complete tasks up to 55% faster, this raw speed often correlates with a decline in code quality and system coherence.1 This is attributed to “Vibe Coding” an anti-pattern where engineers use ad-hoc, unstructured prompting to generate code based on loose intent and iterative guessing.1
“Vibe Coding” leads to the accumulation of “technical debt” in the form of unverified, hallucinated, or inconsistent logic. Because the engineer did not write the code line-by-line, they may lack the deep understanding required to debug or maintain it. This paradox reveals that in an AI-native world, speed without specification is debt.1 The resolution to this paradox lies not in faster models, but in rigorous methodologies like Specification-Driven Development (SDD) and Evaluation Engineering, which reintroduce friction and discipline into the creation process to ensure reliability.1
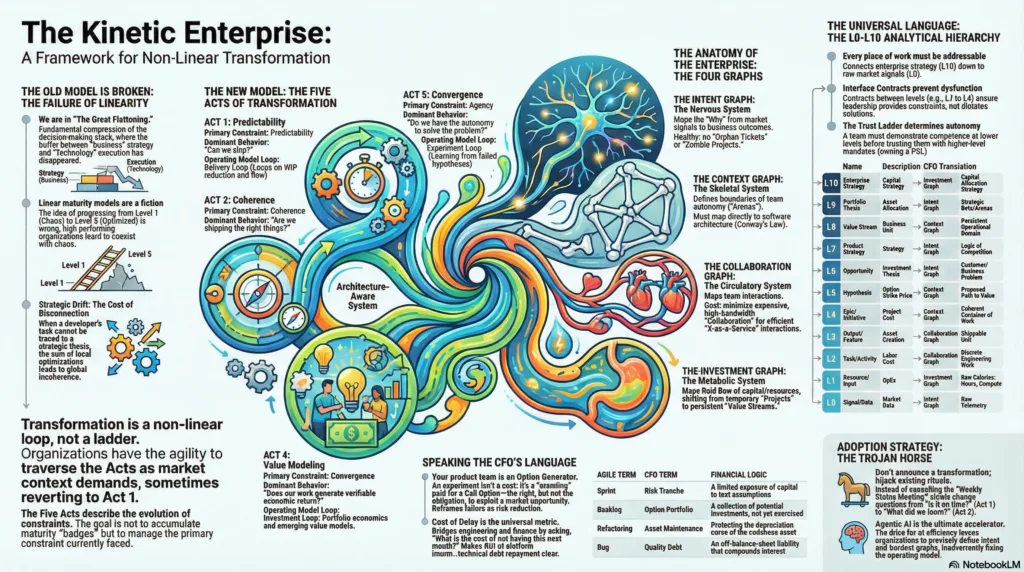
1.3 The Theory of the Kinetic Enterprise
Traditional management theory posits that organizations evolve through linear stages of maturity, often visualized as a “crawl, walk, run” progression. The Kinetic Enterprise framework refutes this, proposing instead that high-performing organizations exist in a state of “Beautiful Mess,” where different operational “Acts” coexist simultaneously.2
The framework replaces static maturity models with The Five Acts of Constraints, which describe the evolution of organizational behavior:
-
Act 1: Predictability: Focuses on the Delivery Loop and WIP reduction.
-
Act 2: Coherence: Focuses on the Goal Loop, ensuring alignment between output and strategy.
-
Act 3: Agency: Focuses on the Strategy Loop, shifting to context-aware problem solving.
-
Act 4: Value Modeling: Focuses on the Investment Loop and verifiable economic returns.
-
Act 5: Convergence: Focuses on the Adaptive Loop, where capital and teams fluidly reconfigure.2
In the AI-Native era, these acts are not sequential steps but recursive loops. An organization may be in “Act 3” regarding its high-frequency trading algorithms (using autonomous agents) while simultaneously struggling with “Act 1” in its legacy operational reporting. The integration of AI agents acts as a “Trojan Horse Mechanism,” subliminally injecting new rituals and workflows that force the organization to evolve without grand programmatic mandates.2
Chapter 2: The Physics of Intelligence, From Generative to Reasoning Engines
To operationalize the AI-Native enterprise, one must first understand the technical evolution of the underlying engines. We are transitioning from Generative AI (probabilistic token prediction) to Agentic AI (deliberative reasoning and planning). This distinction is the “physics” that governs what is possible in software architecture.4
2.1 The Inference Revolution: System 1 vs. System 2
The defining characteristic of this new era is the rise of Inference-Time Scaling. Standard LLMs operate as “System 1” thinkers fast, intuitive, and prone to rapid errors. Reasoning Models (LRMs), such as OpenAI’s o-series or DeepSeek-R1, introduce “System 2” capabilities: the ability to “think” before speaking.3
This is achieved through Test-Time Computation, where the model dedicates additional computational resources during inference to explore a reasoning chain. The research highlights distinct scaling laws for this phase: while training performance scales with parameter count and dataset size, reasoning performance scales with “thinking time” (inference compute).3
Table 1: Comparative Analysis of Generative vs. Reasoning Architectures
Feature****Generative LLMs (System 1)****Reasoning LRMs (System 2)****Primary MechanismNext-token prediction based on training patterns.Multi-step planning, search, and verification.Scaling LawTraining Compute (Model Size).Inference Compute (Thinking Time).3Cognitive ArchitectureDirect Input-Output mapping.Chain-of-Thought (CoT), Tree of Thoughts (ToT).5Prompting StrategyZero-shot or Few-shot.ReAct (Reason+Act), Self-Consistency.5Failure ModeHallucination (confident errors).“Overthinking,” Logic Loops, Cost Spikes.3Use CaseContent generation, summarization.Complex coding, scientific discovery, math.3
2.2 Deep Dive: The Transformer Evolution
The capability of these agents is grounded in specific evolutions of the Transformer architecture. Understanding these “under-the-hood” changes is critical for the Product Engineer effectively optimizing system performance.3
-
Attention Mechanisms: The move from standard Multi-Head Attention to Grouped-Query Attention (GQA) and Multi-Head Latent Attention (MLA) has significantly improved the efficiency of the Key-Value (KV) cache. MLA, for instance, compresses Key-Value pairs to reduce the memory footprint during inference, enabling the massive context windows required for agents to ingest entire codebases or documentation sets without hitting memory walls.3
-
Positional Embeddings: The adoption of Rotary Positional Embeddings (RoPE) allows models to generalize better to sequence lengths unseen during training. This is a prerequisite for long-horizon agentic planning where the context window may span hundreds of thousands of tokens.3
-
Mixture-of-Experts (MoE): To balance scale with latency, architectures have shifted to Sparse MoE, where a router dynamically activates only a small subset of parameters (experts) for each token. DeepSeekMoE introduces a nuanced routing logic that separates “Shared Experts” (for common knowledge) from “Routed Experts” (for specialized tasks), optimizing the trade-off between knowledge breadth and inference cost. This allows for models with trillions of parameters to be inferred at a fraction of the cost of dense models, making agentic workflows economically viable.3
2.3 Training the Reasoner: RLHF vs. RLAIF vs. Pure RL
The alignment of these models is also evolving. While Reinforcement Learning from Human Feedback (RLHF) remains the standard for general-purpose chatbots, it is slow and expensive. The research identifies Reinforcement Learning from AI Feedback (RLAIF) as the scalable alternative. In RLAIF, a “Constitutional AI” acts as the labeler, generating preference data for the model being trained.3
Furthermore, Pure Reinforcement Learning (Pure RL) is emerging as a method where reasoning ability emerges as a learned behavior. Models like DeepSeek-R1-Zero are trained without supervised fine-tuning (SFT), learning to reason purely by maximizing a reward signal (e.g., passing a unit test). This approach has shown that models can spontaneously develop behaviors like “self-correction” and “backtracking” when incentivized correctly.3
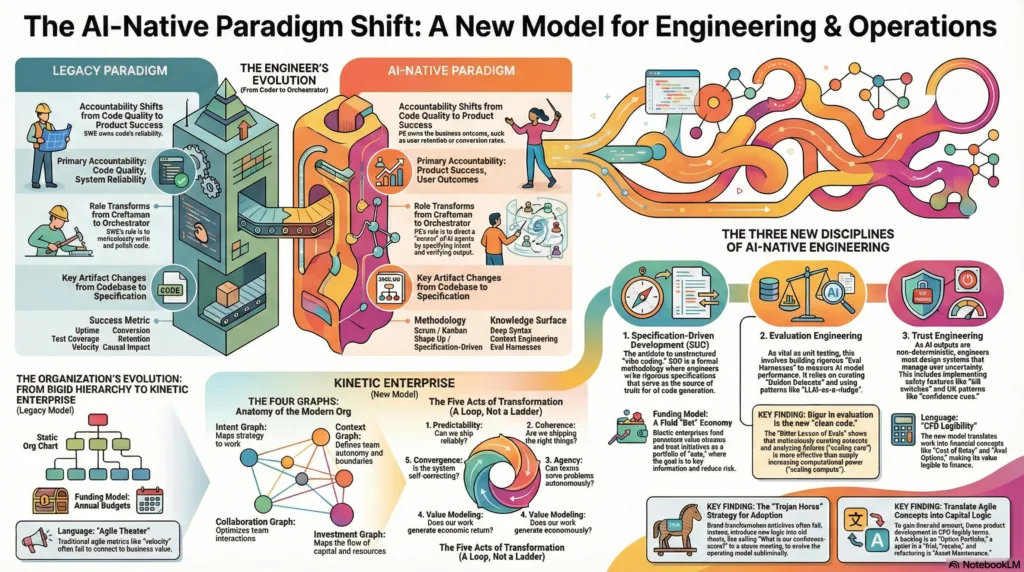
Chapter 3: The AI-Native Product Engineer, Anatomy of a New Role
The convergence of reasoning engines and kinetic operating models crystallizes in the role of the AI-Native Product Engineer (PE). This is not a rebranding of the “Full Stack Developer” but a distinct epistemic stance toward software creation. The PE is an orchestrator of agentic systems rather than solely a writer of imperative code.1
3.1 The Accountability Schism
The traditional Software Engineer (SWE) optimizes for correctness and reliability, measuring success via uptime and test coverage. They “own the code.” In contrast, the Product Engineer optimizes for outcomes and product success, measuring impact via conversion, retention, and revenue. They “own the problem”.1
In the AI-Native world, the implementation capabilities of the SWE are largely automated. The “heavy lifting” of syntax generation is handled by agents, liberating the PE to consume the entire vertical slice of product development from user research to deployment effectively compressing the “Product Trio” (PM, Designer, Engineer) into a single high-agency unit.1
3.2 The Competency Matrix: From T-Shaped to Pi-Shaped
The competency model for a PE has shifted from a “T-shaped” profile (deep in code, broad in product) to a “Pi-shaped” or “Comb-shaped” profile, requiring depth in multiple domains simultaneously.1
Table 2: The Competency Shift Matrix
Domain****Legacy Competency (Traditional SWE)****AI-Native Competency (Product Engineer)****Core Technical SkillSyntax mastery, Algorithms (LeetCode), Framework internals.System Architecture, Context Engineering, RAG Optimization.1Primary ArtifactProduction Codebase (files).Executable Specifications (SPEC.md), Evaluation Harnesses.Product SenseJIRA ticket execution, Feasibility analysis.User Research, Outcome Ownership, Causal Impact Analysis.1Quality AssuranceUnit/Integration Testing, Code Review.Evaluation Engineering, Golden Datasets, LLM-as-a-Judge.1OperationsCI/CD Pipelines, Uptime monitoring.Agent Orchestration, SecAutoOps, Trust Engineering.6SecurityOWASP Top 10 (Web).OWASP Top 10 (LLM), Policy-as-Code, Prompt Injection Defense.6
3.3 Hiring and Career Ladders in the Agentic Era
Hiring for this role requires dismantling the “LeetCode” industrial complex. The ability to invert a binary tree on a whiteboard is irrelevant to whether a candidate can architect a reliable RAG pipeline or debug a non-deterministic agent.1
The Anti-LeetCode Interview:
-
Step 1: The AI-Native Take-Home: Candidates are asked to build a feature using AI tools (Cursor, Copilot). The assessment focuses on the rigor of their Specification (SPEC.md) and their Evaluation Harness (“Did they measure accuracy?”), rather than their typing speed.1
-
Step 2: System Design of Agents: Candidates must design an agentic system (e.g., “Design a Customer Support Chatbot”). Criteria include: How do they handle “I don’t know” scenarios? Do they implement PII redaction? Do they have a “Human-in-the-loop” escalation path?.1
-
Step 3: Product Sense: Candidates are tested on their ability to question the premise (“Should we build this?”) and focus on business value metrics (churn reduction, user trust) rather than just implementation details.1
Chapter 4: Methodology, The Discipline of Specification
If the Product Engineer is the pilot, Specification-Driven Development (SDD) is the flight manual. It is the formalized counter-response to “Vibe Coding” and the defining methodology of the professional AI-native engineer.1
4.1 The SDD Protocol
In SDD, the primary artifact is not the code, but the Specification Context. This shifts the engineer’s focus from “how to implement” to “how to describe.” The protocol follows a rigorous lifecycle:
-
Constitution Phase: The PE defines the immutable laws of the project in a constitution.md file. This includes the tech stack (“Must use TypeScript”), security constraints (“No PII in logs”), and design principles (“Mobile-first”). This serves as the “system prompt” for the entire engineering lifecycle, ensuring consistency across multiple AI agents.1
-
Specification Phase: The PE writes a “living contract” (SPEC.md) before a single line of code is generated. This document includes:
-
Context: User problem and business goal.
-
Requirements: Functional and non-functional (latency, security).
-
Data Model: Schema definitions.
-
UX Flows: Step-by-step interaction descriptions.
-
Corner Cases: Explicit error states and edge cases.1
-
Clarification Loop (Socratic Design): Before implementation, the AI agent “quizzes” the spec writer. The agent asks questions to find gaps in the logic (“What happens if the API returns a 429 error?”). This phase is crucial for identifying ambiguity and forcing the PE to articulate intent clearly.1
-
Technical Plan & Task Breakdown: The agent decomposes the spec into a technical roadmap. The PE reviews and approves architectural decisions (e.g., “Use Redis for caching”) before coding begins.1
-
Implementation & Verification: The agent executes the build. The PE shifts to auditing the output against the spec and the constitution, checking for “hallucinated libraries” or security flaws.1
4.2 From Agile to “Shape Up” for AI
The research indicates that traditional Agile methodologies (Scrum, Kanban) struggle with the unpredictability of AI development. The “Shape Up” methodology (typically 6-week cycles with 2-week cool-downs) is uniquely suited for this environment.1
-
Shaping (Weeks -2 to 0): The Product Trio (led by the PE) defines the problem and the “Appetite” (time budget). Crucially, this phase now includes Prototyping Feasibility. The PE builds a quick Eval Harness to test if the LLM can actually perform the core reasoning task. If the model fails the eval, the project is killed before engineering begins.1
-
Building (Weeks 1-6): The team works uninterrupted. Because AI is unpredictable, the PE engages in “Discovery in Delivery.” They might realize the model fails at a specific task and must redesign the UX to accommodate that failure (e.g., adding a “Human Review” step).1
-
The Cool-down (Weeks 7-8): This time is used to update the Evaluation Harness with edge cases and failures discovered during the cycle, effectively “compiling” the lessons learned into the system’s test suite.1
4.3 The Spec Execution Lifecycle (SEL)
To automate SDD, organizations implement the Spec Execution Lifecycle (SEL). This infrastructure layer treats the specification as executable code.
-
Ingest: The system reads the SPEC.md.
-
Plan: An “Architect Agent” creates a dependency graph of tasks.
-
Execute: “Worker Agents” generate code and tests in parallel.
-
Critique: A “Judge Model” evaluates the output against the spec and the “Golden Dataset” (ground truth examples).
-
Refine: If the critique fails, the system enters a refinement loop. If it passes, it is presented to the human for final review.6
This lifecycle moves the organization into “Act 3: Agency,” where the system itself possesses the agency to drive development forward, constrained only by the human-defined Intent Graph.2
Chapter 5: The Kinetic Operating Model, The Five Acts and Four Graphs
The transition to AI-Native Engineering cannot occur in a vacuum; it requires an operating model capable of supporting high-velocity, non-deterministic workflows. The Kinetic Enterprise framework provides the necessary “System Anatomy” through the Four Graphs, which map operational reality rather than reporting lines.2
5.1 The Four Graphs of the AI-Native Organization
-
The Intent Graph (The Nervous System): This maps the flow of rationale from high-level strategy to specific agent tasks. In an AI-native firm, the SPEC.md and constitution.md files form the nodes of this graph, ensuring that every line of agent-generated code traces back to a strategic thesis (L10).2 This aligns with “Act 2: Coherence” and ensures that the autonomous system remains aligned with business goals.
-
The Context Graph (The Skeletal System): Defines the boundaries of autonomy. This embodies Conway’s Law. In an agentic system, this graph defines the Context Windows and Retrieval Corpora available to different agent swarms.2 It ensures agents have the minimum necessary context to function, mitigating security risks and optimizing compute costs.7
-
The Collaboration Graph (The Circulatory System): Maps the dynamic interactions between human teams and agent swarms. It replaces static org charts with fluid “Team Topologies” that evolve based on the problem space. For example, a temporary “Tiger Team” of humans and agents might form to tackle a specific architectural debt issue.2
-
The Investment Graph: Focuses on capital allocation. In the AI era, this shifts from “Headcount Budget” to “Compute/Token Budget” and “Context Maintenance Costs”. This graph tracks the ROI of agentic workflows, ensuring that the “Cost-to-Serve” does not exceed the value generated.2
5.2 Deep Dive: The Five Acts in an Agentic Context
The “Five Acts” describe the evolution of constraints. AI agents accelerate the transition through these acts:
-
Act 1: Predictability: Agents automate the “Delivery Loop” by handling routine tasks (e.g., PR reviews, test generation), reducing WIP and increasing throughput.
-
Act 2: Coherence: The Intent Graph ensures that agents are working on the right things. “Goal Loop” agents can monitor KPIs and alert humans when outcomes diverge from strategy.
-
Act 3: Agency: The organization shifts from “Feature Factory” to context-aware problem solving. Agents are given high-level objectives (“Optimize the checkout flow”) rather than specific tasks (“Move this button”). This requires the ReAct (Reason+Act) pattern.2
-
Act 4: Value Modeling: The “Investment Loop” becomes verifiable. Because agent costs (tokens) are directly measurable, the organization can calculate the exact cost of a feature or a bug fix, enabling precise “Value Modeling”.2
-
Act 5: Convergence: The system operates in an “Adaptive Loop.” The Collaboration Graph and Investment Graph reconfigure fluidly. If an agent swarm identifies a new market opportunity (via data analysis), the system can provision resources to explore it, achieving true organizational agility.2
Chapter 6: Architecture of the Agentic Enterprise, Search, Vectors, and Context
A reasoning engine is only as good as the context it retrieves. This has led to the “Context Wall,” the primary bottleneck in agentic systems.4 Overcoming this requires a Zero Trust Search Architecture and a sophisticated Vector Pipeline.7
6.1 The Vector Pipeline and Embedding Engine
The core asset of the new search is the Vector Index. Storing and searching billions of high-dimensional vectors requires a specialized pipeline leveraging Approximate Nearest Neighbor (ANN) algorithms.7
-
Indexing Structures:
-
HNSW (Hierarchical Navigable Small World): A graph-based algorithm enabling logarithmic-time search. It offers high recall and low latency but has a massive memory footprint that scales linearly with dataset size.7
-
IVF (Inverted File Index): Uses k-means clustering to partition the vector space. It is more memory-efficient but can suffer from lower recall.
-
Quantization: Techniques like Product Quantization (PQ) compress vectors into subspaces, balancing memory efficiency with accuracy. This is essential for managing the cost of the index.7
6.2 The Tension: Model Drift vs. Context Drift
The research identifies a critical operational conflict: the tension between Model Drift and Context Drift.7
-
Model Drift: The LLM’s behavior changes as it is updated or fine-tuned. A query planning logic optimized for GPT-4 might fail with GPT-5.
-
Context Drift: The “ground truth” (the index) changes as the world changes (e.g., updated pricing).
-
The Conflict: Updating the index (to fix Context Drift) can break the agent’s reasoning patterns (causing Model Drift). The DataOps team managing the index and the MLOps team managing the model are locked in a “continuous, unstable operational balance”.7
6.3 The Fragmented Index and A2A Negotiation
The vision of a single, omniscient “Enterprise Search” is fading. The future is a Fragmented Index Ecosystem comprising:
-
Public Indexes: Specialized vendors (e.g., Exa, Parallel) indexing the web for agents.7
-
Enterprise Indexes: Proprietary data within corporate firewalls (e.g., Salesforce Agentforce, Microsoft Fabric).7
-
Sovereign Indexes: State-controlled indexes built for national security and data sovereignty.7
To navigate this, agents must employ Agent-to-Agent (A2A) Negotiation. An “Orchestrator Agent” decomposes a user’s task and negotiates with specialized agents to retrieve data, governed by open standards like the Model Context Protocol (MCP). This “multi-agent orchestration layer” functions as the new, invisible information fabric of the enterprise.7
Chapter 7: Trust, Governance, and SecAutoOps
As agents gain agency, the attack surface expands. Security in an agentic world requires SecAutoOps (Secure Autonomous Software Operations). This extends DevSecOps to handle the unique threat vectors of autonomous agents.6
7.1 Threat Modeling for Agents
The research highlights the OWASP Top 10 for LLMs as the baseline for threat modeling. Key risks include:
-
Prompt Injection: Attackers manipulating the agent’s instructions to bypass controls.
-
Excessive Agency: Agents performing unapproved actions (e.g., deleting data) due to vague specifications or logic loops.6
-
Recursive API Loops: An agent getting stuck in a loop of API calls, causing massive financial loss (Denial of Wallet attack).7
7.2 The SecAutoOps Framework
To mitigate these risks, organizations must implement a Zero Trust Architecture for agents:
-
Context Segmentation: Agents should operate in sandboxed environments (using Firecracker or WebAssembly) with strict egress filters. They should not share memory or context globally unless explicitly authorized via the Context Graph.6
-
Policy-as-Code: Agent permissions must be defined in code and enforced at the infrastructure level. An agent designed to “summarize logs” should be cryptographically incapable of “deleting logs”.6
-
Context Snapshotting: To handle failure, the system captures the full state of an agent before critical actions. If a failure occurs (e.g., a tool misuse), the system can “rollback” to the last known-good snapshot, preserving the accumulated reasoning and context.7
7.3 Evaluation Engineering: The Trust Moat
Trust is not built on hope; it is built on evidence. Evaluation Engineering is the discipline of creating rigorous harnesses to measure agent performance.1
-
Golden Datasets: A curated set of high-quality input/output pairs that represent “correct” behavior, including adversarial examples and edge cases.1
-
LLM-as-a-Judge: Using a stronger model (e.g., GPT-4o) to grade the outputs of a faster production model. Criteria include correctness, tone, and safety.1
-
The “Red Line” Rule: If the “Pass Rate” on the Golden Dataset drops by a defined threshold (e.g., >2%), the build fails. This prevents regression in model quality.1
Chapter 8: The Economic and Strategic Landscape
The shift to AI-Native Engineering fundamentally reshapes the economics of the firm, moving from Labor-driven CapEx to Compute-driven OpEx.
8.1 The Economic Inversion
The Investment Graph of the Kinetic Enterprise reveals a shift in cost structures.
-
GPU Burn Rate: AI-powered search and reasoning can be up to 10x more costly than traditional keyword search.7
-
Negative Gross Margins: Companies pricing AI features like traditional SaaS risks “negative gross margins” on power users. The operating model must account for “Cost-to-Serve” at a granular level, dynamically adjusting “Thinking Budgets” based on user tier and query complexity.7
-
TCO Models: Total Cost of Ownership now includes not just developer salaries, but token consumption, vector storage costs, and the “Context Maintenance” burden of keeping indexes fresh.4
8.2 Vendor Landscape and Lock-in
A new class of vendors is emerging to support this stack:
-
AI-Native Challengers: Vendors like Parallel and Exa building proprietary search indexes for agents.7
-
Incumbents: Microsoft (Copilot), Salesforce (Agentforce) pivoting to “Agent-Native” platforms.7
Lock-in Mitigation: The research warns of “Framework Lock-in” (building on rapidly evolving agent frameworks) and “Data Lock-in” (storing vectors in vendor silos). The mitigation strategy is Architectural Abstraction: enterprises must build layers that insulate core logic from specific vendor APIs and rely on open standards like MCP.7
8.3 Societal and Ethical Implications
Finally, the transition must be navigated with an awareness of the broader societal context. The pursuit of “AGI” as a North Star can lead to the exclusion of communities and disciplines, resulting in products that harm minoritized groups.8
-
Model Collapse: The reliance on synthetic data can lead to model collapse, where models lose variance and quality. Provenance-Aware Indexing is required to prioritize human-generated “tail data”.7
-
Environmental Impact: The massive compute requirements of reasoning engines have a significant carbon footprint. “Green AI” practices and efficient architectures (like MoE) are strategic imperatives.3
Conclusion: The Adaptive Loop
The convergence of AI-Native Product Engineering and the Kinetic Operating Model represents a singular opportunity to reinvent the software firm. By flattening the decision stack, embracing the discipline of Specification-Driven Development, and architecting for the “Four Graphs,” organizations can achieve the “Adaptive Loop” of Act 5 a state where the enterprise is as fluid, intelligent, and responsive as the agents it employs.
The risks are significant Model Collapse, Hallucination, and Governance Failure but the opportunity is a 32x improvement in business performance for those who successfully navigate the transformation.4 The path forward requires a rigorous commitment to Specification, Evaluation, and Architecture, moving beyond the hype of “AI Magic” to the discipline of AI Engineering.
DimensionTraditional ArchetypeAI-Native/Kinetic ArchetypePrimary AccountabilityKey ArtifactsSuccess MetricsMethodology/Operating LoopPrimary AccountabilityCode Quality, System Reliability, and manual translation of logic into syntax.Product Success, User Outcomes, and the resolution of user problems.Owning the code and technical depth (SWE) vs. Owning the outcome and user value (PE).Production Codebase; Jira tickets; Technical roadmaps.Uptime, Test Coverage, and Velocity.Scrum or Kanban; Linear maturity models (Crawl, Walk, Run).Core ArtifactsManual implementation files (e.g., .ts files) and imperative code.Executable Specifications (SPEC.md) and Intent Graphs.Moving from ‘how to implement’ to ‘how to describe’.SPEC.md, .cursorrules, constitution.md, and Evaluation Harnesses.Pass Rates on Golden Datasets; Causal Impact.Specification-Driven Development (SDD); The Spec Execution Lifecycle (SEL).Success MetricsVelocity (throughput capacity) and Uptime.Causal Impact, Conversion, Retention, and Trust Decay Curves.Shift from measuring production speed to measuring verifiable economic return.Outcome Reviews; P&L; Option Strike Price.Causal Impact Analysis; ROIC; Revenue Impact.The Investment Loop; Act 4 (Value Modeling).Operating Model/MethodologyScrum/Kanban (Linear maturity/Agile Theater).Shape Up (Non-linear recursive loops).Transitioning from rigid ticketing to ‘Shaping’ and ‘Betting’ sessions.Pitch documents; Betting table; The Four Graphs (Intent, Context, Collab, Invest).Cycle Time reduction; Goal Achievement Rate.Shape Up (6-week cycles); The Five Acts of Organizational Evolution.Engineering DisciplineSyntax mastery, algorithms (LeetCode), and manual testing.Orchestration, Trust Engineering, and Evaluation Engineering.Architecting systems that manage non-deterministic AI outputs.Golden Datasets, LLM-as-a-Judge, Kill Switches, and Circuit Breakers.Prompt Injection Defense rate; Confidence Cues; Pass Rates.The Trust Engineering & Safety Harness; SecAutoOps.Organizational StructureHierarchical silos with separate PM, Designer, and Engineer roles.The Product Trio (The Great Flattening).Compression of the decision-making stack into high-agency units.Collaboration Graph; Context Windows; Interface Contracts.Signal Velocity; Resource Reallocation Speed.Act 5 (Convergence); The Adaptive Loop.
Appendix A: Key Definitions
-
Product Engineer (PE): An engineer accountable for product outcomes, utilizing AI to handle implementation.
-
Specification-Driven Development (SDD): A methodology where executable specs are the primary artifact.
-
Kinetic Enterprise: An operating model based on non-linear evolution and recursive loops.
-
SecAutoOps: Security operations for autonomous agent systems.
-
Model Context Protocol (MCP): An open standard for connecting AI models to data sources.
-
Reasoning Engine (LRM): An AI model capable of multi-step planning and “System 2” thinking.
-
Context Wall: The bottleneck where an agent lacks the necessary information to proceed.
Appendix B: The “Five Acts” Checklist for Leaders
-
Act 1: Are we shipping predictably? (Metric: Cycle Time).
-
Act 2: Are we aligned? (Metric: Goal Achievement Rate).
-
Act 3: Are we leveraging agency? (Metric: Agent Contribution Index).
-
Act 4: Are we measuring value? (Metric: Causal Impact / ROI).
-
Act 5: Are we adapting? (Metric: Resource Reallocation Speed).
Geciteerd werk
-
AI-Native Product Engineering Research
-
Operating Model Evolution Research Framework
-
Reasoning Engines
-
Agentic Engineering Transformation Strategy Research
-
Agents
-
AI-Native Development Strategic Blueprint
-
AI-Native Search Transformation Study
-
Blili-Hamelin et al. Stop Treating ‘AGI’ as the north-star goal of AI Research
Presentatie: The Kinetic Convergence
The Kinetic Convergence
Presentatie: The Kinetic Convergence (part 2)
The Kinetic Convergence (part 2)
Presentatie: The Kinetic Convergence (part 3)
The Kinetic Convergence (part 3)
The kinetic convergence a unified theory of AI-native product engineering and operating model evolution
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.