Why data architecture is key to scalable AI solutions.
By Dennis Landman
Introduction
The chasm between AI ambitions and operational reality continues to widen at most enterprises. While executive teams rush to stake claims in the AI gold rush, 87% of AI initiatives never reach production (Gartner, 2024). The culprit is rarely the AI models themselves, but rather the brittle, fragmented data foundations they’re built upon. When organizations invest millions in AI talent and technology while treating data architecture as an afterthought, they effectively build computational skyscrapers on quicksand.
Organizations with mature data architectures deploy AI models 6.3 times faster and achieve 4.8 times the ROI compared to those with ad-hoc data environments (McKinsey Global Institute, 2024). Yet, according to a recent MIT Sloan survey, only 32% of organizations report having a coherent data architecture strategy aligned with their AI objectives.
The reality is stark: without strategic data architecture designed for AI workloads, organizations face an insurmountable scaling barrier. As we transition from proof-of-concept AI to enterprise-wide deployment, data architecture isn’t merely a technical consideration, it’s the dividing line between organizations that can operationalize AI at scale and those left with expensive experiments that never deliver business value.
Background and context
Enterprise data architecture has evolved dramatically over the past two decades. The journey began with centralized data warehouses that consolidated structured data from operational systems for analytics. These monolithic structures, while organized, were rigid and struggled with the volume and variety of data needed for modern AI applications.
The big data era introduced data lakes, providing the flexibility to store vast amounts of raw, unprocessed data. However, many organizations created “data swamps”, repositories where data was dumped without proper governance or cataloging, ultimately becoming unusable for reliable AI development.
Today’s enterprise data landscapes are increasingly complex:
-
94% of enterprises operate in hybrid or multi-cloud environments (Flexera, 2024)
-
The average enterprise maintains 1,200+ distinct applications, each generating potential training data (Deloitte, 2024)
-
76% of organizations still depend on legacy systems that weren’t designed for AI workloads (IDC, 2023)
Unlike traditional analytics, AI systems place unique demands on data infrastructure. They require not just historical data access but continuous data flows for both training and inference. While a quarterly sales dashboard might tolerate week-old data, an AI-powered fraud detection system becomes worthless if it can’t access real-time transaction data.
Technical debt in data infrastructure compounds these challenges. The Harvard Business Review (Davenport & Bean, 2023) found that 68% of data scientists spend more time finding, cleaning, and organizing data than actual model development. This inefficiency directly impacts the economics of AI initiatives, as expensive talent wastes time on data plumbing rather than value creation.
The modern approach recognizes that data architecture for AI isn’t merely about storage and processing technology, it’s about creating a living infrastructure that can supply high-quality, governed data to AI systems at scale while adapting to rapidly changing business requirements.
Core data architecture principles for AI readiness
Data discovery and accessibility frameworks
AI development and deployment fundamentally depend on frictionless data access. Organizations with effective data architecture implement unified data catalogs with semantic layer capabilities that allow AI teams to discover and access relevant datasets without depending on database administrators or data engineers.
Global pharmaceutical companyA leading pharmaceutical firm struggled with a 14-week average time to access clinical trial data for AI applications. After implementing a metadata-driven data catalog with automated access provisioning, this was reduced to 3 days, accelerating AI model development cycles by 60%.
The most effective discovery frameworks leverage automated data classification and business glossaries to create a shared language between domain experts (who understand the data’s meaning) and AI engineers (who need to utilize it). This bridges the critical semantic gap that derails many AI initiatives.
Governance and security by design
Contrary to the common misconception that governance impedes innovation, mature data architecture embeds governance and security as enablers for AI scaling. With regulations like GDPR, CCPA, and industry-specific mandates like HIPAA, governance cannot be an afterthought.
Effective architectures implement:
-
Attribute-based access control that maintains security while enabling appropriate data use
-
Automated privacy controls including dynamic masking and anonymization
-
Comprehensive lineage tracking to ensure regulatory compliance
-
Privacy-preserving computation techniques where appropriate
According to Forrester Research (2024), organizations with mature data governance are 2.6 times more likely to successfully scale AI beyond pilot projects, primarily because they avoid the regulatory roadblocks that halt ungoverned initiatives.
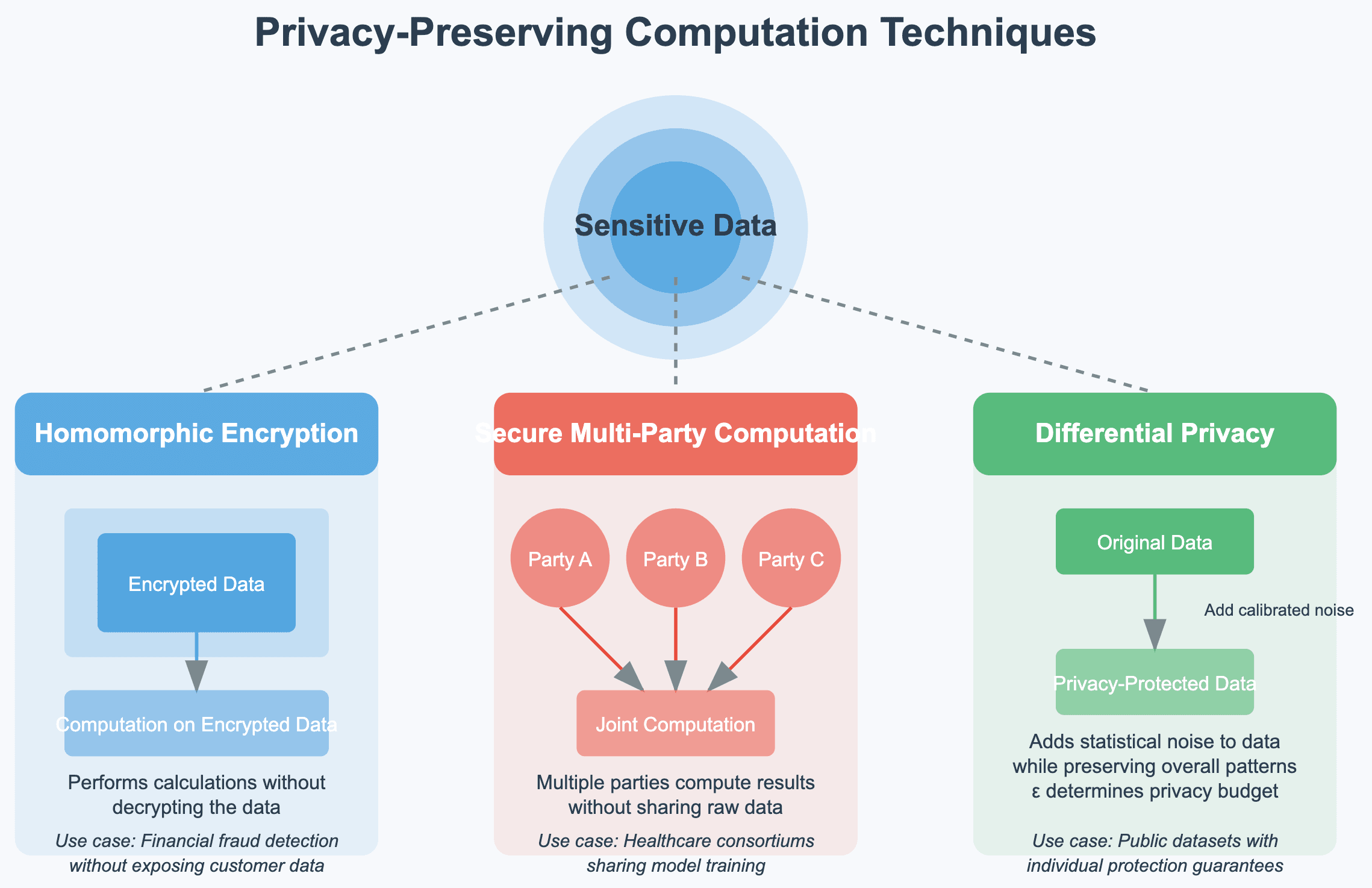
Privacy-preserving computation techniques
As AI applications increasingly process sensitive data, privacy-preserving computation has become a critical architectural component. Leading organizations implement:
Homomorphic encryption approachesThis technique allows computation on encrypted data without decryption, enabling AI models to generate insights from sensitive data while maintaining privacy. Financial services companies have implemented partial homomorphic encryption for fraud detection models that can analyze transaction patterns without exposing raw customer data.
**Secure multi-party computation (SMPC)**SMPC enables multiple organizations to collaboratively train AI models without sharing their underlying data. Healthcare consortiums have used SMPC frameworks to develop diagnostic models trained across multiple hospital systems while maintaining patient privacy and regulatory compliance.
Differential privacy frameworksThese architectures add carefully calibrated noise to data, preventing identification of individuals while preserving statistical validity. Technology companies have implemented differential privacy in their data architectures to enable AI model training while providing mathematical guarantees against re-identification attacks.
According to the Ponemon Institute (2024), organizations implementing privacy-preserving computation in their data architecture reduce regulatory approval times for AI initiatives by 64% while enhancing customer trust.
Scalability considerations for training and inference
AI workloads are notoriously spiky, training may require massive computational resources for short periods, while inference needs low-latency, high-availability systems. Data architecture must accommodate both:
-
Elastic data processing capabilities that scale without intervention
-
Separation of storage and compute to optimize economics
-
Tiered data management that balances performance and cost
-
Resource isolation to prevent AI workloads from impacting operational systems
Manufacturing AI failureA global manufacturer attempted to deploy a predictive maintenance AI without adapting its data architecture. When the model was deployed to 100+ facilities, the underlying data warehouse collapsed under the query load. Six months and $4.2M later, they reimplemented with a decoupled architecture that could scale independently for training and inference workloads.
Metadata management capabilities
Metadata, data about data, is the secret weapon of AI-ready architectures. Comprehensive metadata management enables:
-
Automated data quality assessment based on fitness-for-purpose
-
Version control for datasets used in model training
-
Impact analysis when source systems change
-
Runtime validation of data drift that affects model performance
The Aberdeen Group found organizations with robust metadata management deploy AI models 58% faster with 71% fewer production incidents related to data quality issues.
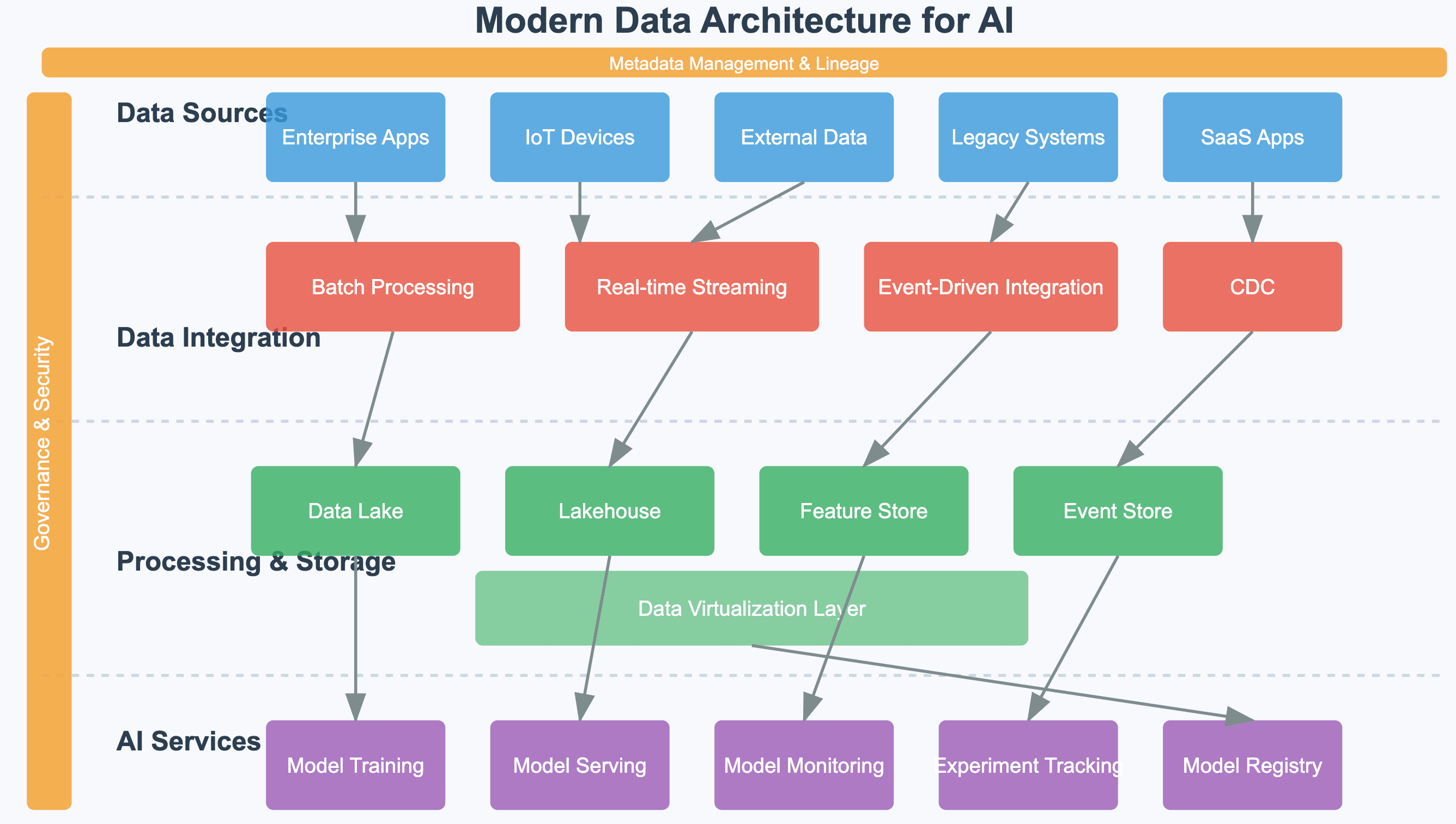
Common enterprise data architecture patterns for AI
Data lake/lakehouse architectures
The lakehouse paradigm has emerged as a dominant pattern for AI-ready data architecture, combining the flexibility of data lakes with the reliability and performance of data warehouses. This architecture provides:
-
Schema enforcement when needed, while maintaining raw data flexibility
-
Transaction support for reliable data updates
-
Performance optimization for both batch and streaming workloads
-
Unified governance across structured and unstructured data
The Lakehouse ParadigmAs defined by Databricks in their seminal paper (Armbrust et al., 2023), the lakehouse combines “the best elements of data lakes and data warehouses, delivering data management and performance typically found in data warehouses with the low-cost, flexible object stores offered by data lakes.”
Organizations implementing lakehouse architectures report 40-60% lower total cost of ownership compared to maintaining separate analytical and AI data environments (Ventana Research, 2024). The TCO advantage is particularly pronounced in cloud implementations, where storage costs for duplicate data can be significant:
| Architecture Type | 3-Year TCO (500TB) | Training Data Preparation Overhead | Production Deployment Time |
|---|---|---|---|
| Traditional Data Warehouse | $4.2M | 72 hours | 4-6 weeks |
| Data Lake Only | $2.1M | 48 hours | 2-4 weeks |
| Lakehouse | $1.8M | 12 hours | 3-5 days |
Architecture Type3-Year TCO (500TB)Training Data Preparation OverheadProduction Deployment TimeTraditional Data Warehouse$4.2M72 hours4-6 weeksData Lake Only$2.1M48 hours2-4 weeksLakehouse$1.8M12 hours3-5 days
Source: Ventana Research TCO Analysis, 2024
Event-driven architectures for real-time AI
As AI moves from batch analytics to real-time decision making, event-driven architectures become critical. These designs utilize:
-
Stream processing frameworks (Apache Kafka, Azure Event Hubs, AWS Kinesis)
-
Complex event processing for temporal pattern detection
-
Event schemas and contracts for reliable data exchange
-
Command Query Responsibility Segregation (CQRS) to separate operational and analytical workloads
Financial services real-time fraud detectionA tier-1 bank transitioned from batch-based to real-time fraud detection by implementing an event-driven architecture. The results were compelling: 62% reduction in fraud losses and 88% fewer false positives. The key architectural component wasn’t the AI model but the event backbone that could process 50,000+ transactions per second with sub-10ms latency.
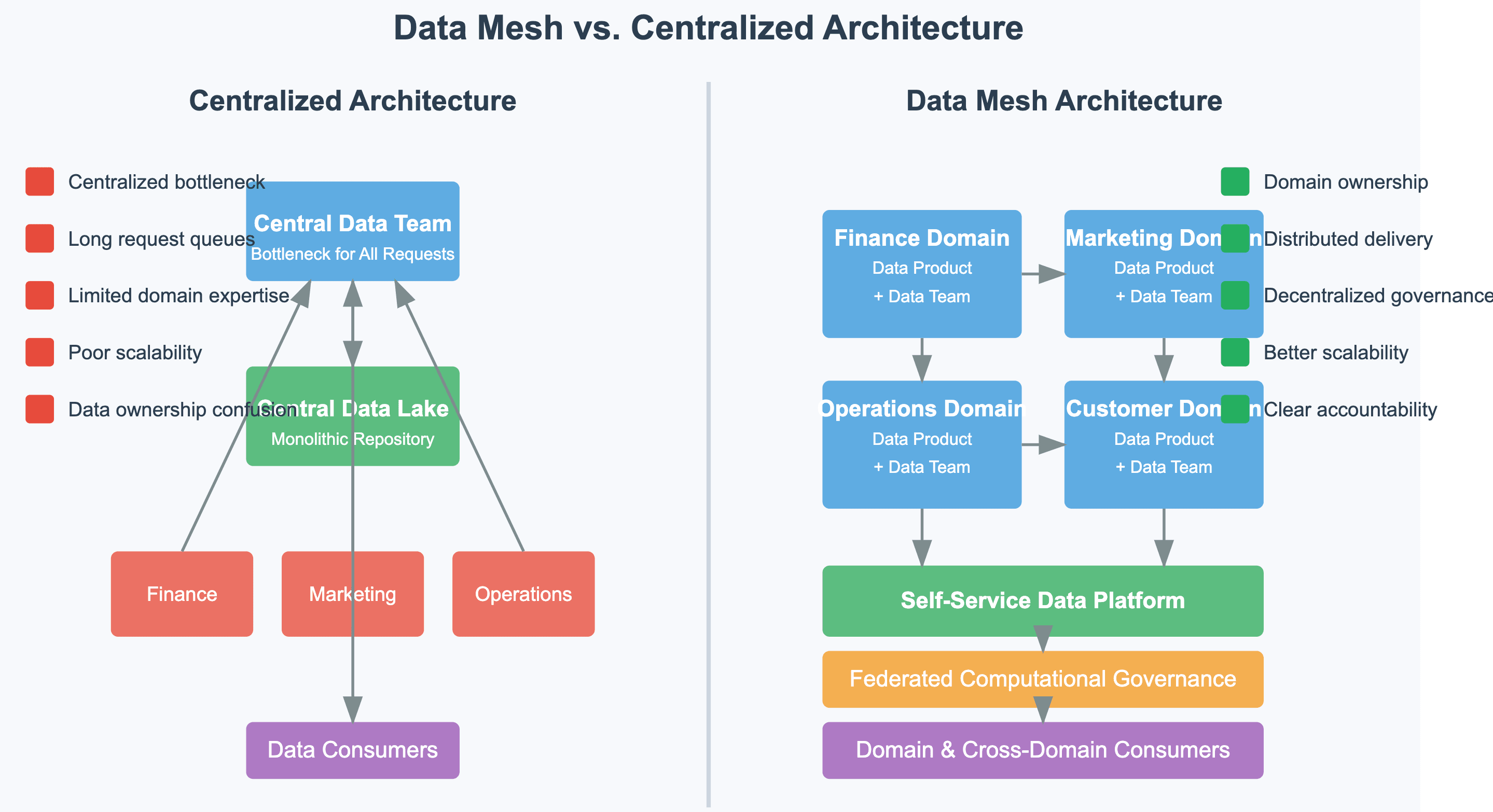
Data mesh for domain-oriented scalability
As organizations scale AI capabilities across business domains, centralized data teams become bottlenecks. The data mesh paradigm addresses this through:
-
Domain-oriented data ownership and architecture
-
Data products with well-defined interfaces and SLAs
-
Self-service infrastructure platforms for domain teams
-
Federated computational governance
According to Zhamak Dehghani, who introduced the data mesh concept, “Data mesh addresses the failures of the centralized, monolithic data lake or data platform architecture and the outdated assumptions that led to its inception” (Dehghani, 2023).
Organizations that have implemented data mesh principles report 3.2x higher success rates in cross-functional AI initiatives compared to those with traditional centralized data platforms (ThoughtWorks, 2024).
Hybrid architectures for regulated industries
For regulated industries like healthcare, financial services, and public sector, pure cloud migrations are often infeasible. Hybrid architectures blend:
-
On-premises data processing for sensitive workloads
-
Cloud-based computation for training and non-sensitive data
-
Consistent governance across environments
-
Data virtualization to provide unified access without data movement
A hybrid approach allows organizations to balance regulatory requirements with the need for modern AI capabilities. According to IDC, 74% of enterprises in regulated industries maintain hybrid architectures, with 68% citing compliance as the primary driver.
Financial services compliance requirements
Financial institutions face unique regulatory challenges that shape their data architecture decisions. Basel III and the Digital Operational Resilience Act (DORA) in Europe impose specific requirements:
-
Data locality constraints necessitating geo-specific storage
-
Explicit audit requirements for model training data
-
Mandatory separation between development and production environments
-
Stress testing capabilities for data pipelines
Morgan Stanley’s Chief Data Architect noted: “Our data architecture isn’t just about enabling AI, it’s about ensuring every model can withstand regulatory scrutiny from the moment it’s conceived” (Financial AI Summit, 2024).
Healthcare data integration challenges
Healthcare organizations face particular challenges integrating structured and unstructured data for AI applications:
-
FHIR (Fast Healthcare Interoperability Resources) integration requiring specialized mapping layers
-
Longitudinal patient data management across disparate systems
-
Image data integration (DICOM) with clinical records
-
Compliance with 21 CFR Part 11 for electronic records in clinical applications
Integrated healthcare data architectureA leading academic medical center implemented a comprehensive architecture that united clinical, imaging, genomic, and claims data. The architecture featured a FHIR-based integration layer with automated privacy controls that reduced compliance review cycles from months to days, enabling rapid deployment of clinical decision support AI.
Manufacturing edge-to-cloud architectures
Industrial environments present unique constraints for AI data architectures:
-
Intermittent connectivity requiring robust edge processing
-
Time-series data volumes exceeding network capacity
-
OT/IT integration challenges for holistic analysis
-
Latency requirements incompatible with cloud round-trips
Automotive manufacturingA global auto manufacturer implemented a tiered architecture with preprocessing at the edge, aggregation at the plant level, and cross-facility analysis in the cloud. This approach reduced data transport by 94% while enabling AI models to detect quality issues in real-time at the edge and perform cross-plant optimization in the cloud.
Critical components of AI-ready data infrastructure
Stream processing capabilities
Real-time data processing has moved from competitive advantage to baseline requirement for AI systems. According to Gartner, by 2025, over 70% of new AI deployments will depend on streaming data infrastructure. Essential capabilities include:
-
Low-latency message brokers with strong ordering guarantees
-
Stream processing frameworks that support complex windowing operations
-
Change data capture from operational systems
-
Stateful processing for temporal analytics
These components create a nervous system for enterprise AI, allowing models to respond to business events as they occur rather than in batch cycles.
Data quality monitoring and remediation
AI models are uniquely vulnerable to data quality issues, problems that might be tolerable for human interpretation can cause catastrophic model failures. AI-ready architectures implement:
-
Automated quality checks at data ingestion points
-
Statistical monitoring for distribution shifts
-
Validation rules derived from business constraints
-
Circuit breakers to prevent corrupted data from reaching production models
Retail pricing AI failureA major retailer deployed an AI-driven pricing system without adequate data quality controls. When a upstream system changed the format of cost data, the model began setting prices below cost, resulting in $1.8M in losses before the issue was detected and fixed. Subsequent implementation of automated data quality monitoring prevented similar incidents.
Industry-specific validation approaches
Different industries require specialized validation approaches:
Manufacturing physics-based validationIndustrial data requires validation against known physical constraints. A steel manufacturer implemented validation rules based on metallurgical principles that identified sensor drift before it could impact predictive maintenance models.
Healthcare clinical validationMedical data requires domain-specific validation. A healthcare system implemented rules to flag physiologically impossible values and contextual inconsistencies, reducing model retraining frequency by 65%.
Financial services regulatory validationFinancial data must meet both business and regulatory standards. A global bank implemented multi-layer validation, including pattern detection for potential money laundering signals, that improved model accuracy while ensuring regulatory compliance.
Feature stores and feature versioning
Feature stores have emerged as critical infrastructure for scalable AI, providing:
-
Consistent feature computation across training and inference
-
Feature sharing and reuse across models
-
Point-in-time correct feature retrieval
-
Versioning and lineage for reproducibility
According to a 2024 survey by KDnuggets, organizations with feature store implementations reduce model development time by 40% and cut operational incidents by 55% compared to those without formalized feature management.
Model training data management
As regulatory scrutiny of AI increases, organizations need robust systems to manage training data:
-
Immutable snapshots of training datasets
-
Labeling workflows with quality control
-
Annotation versioning and lineage
-
Bias detection and mitigation tools
The European Union’s AI Act and similar regulations explicitly require documentation of training data sources and characteristics, making systematic training data management a compliance necessity.
Lineage tracking
Data lineage provides the audit trails essential for both regulatory compliance and operational troubleshooting:
-
End-to-end tracking from source systems to model outputs
-
Code versions used for transformations
-
Parameter configurations for processing steps
-
Impact analysis capabilities for upstream changes
Theoretical Framework: The FAIR PrinciplesThe FAIR principles (Findable, Accessible, Interoperable, Reusable) provide a theoretical foundation for effective data lineage in AI systems. Originally developed for scientific data management, they’ve been adapted for enterprise AI by organizations like the Linux Foundation’s AI & Data Foundation.
Organizational implications and operating models
Roles and responsibilities in modern data teams
Effective data architecture requires clear organizational alignment. Forward-thinking enterprises are adopting new structures:
-
Data product managers who own data assets from source to consumption
-
Data engineers specialized in scalable, resilient pipeline development
-
Data governance stewards embedded in domain teams
-
Machine learning engineers who bridge data and model operations
According to the Data Management Association (DAMA), organizations with formalized data management roles are 2.4x more likely to successfully scale AI initiatives.
DataOps and MLOps integration points
The convergence of DataOps and MLOps creates a continuous delivery pipeline for AI solutions:
-
Shared CI/CD infrastructure for data pipelines and models
-
Unified monitoring for data and model health
-
Integrated incident response across the data-to-model chain
-
Automated testing of data transformations and model behavior
A recent study by the IDC found that organizations with integrated DataOps and MLOps practices achieve 3.7x higher success rates in production AI deployments.
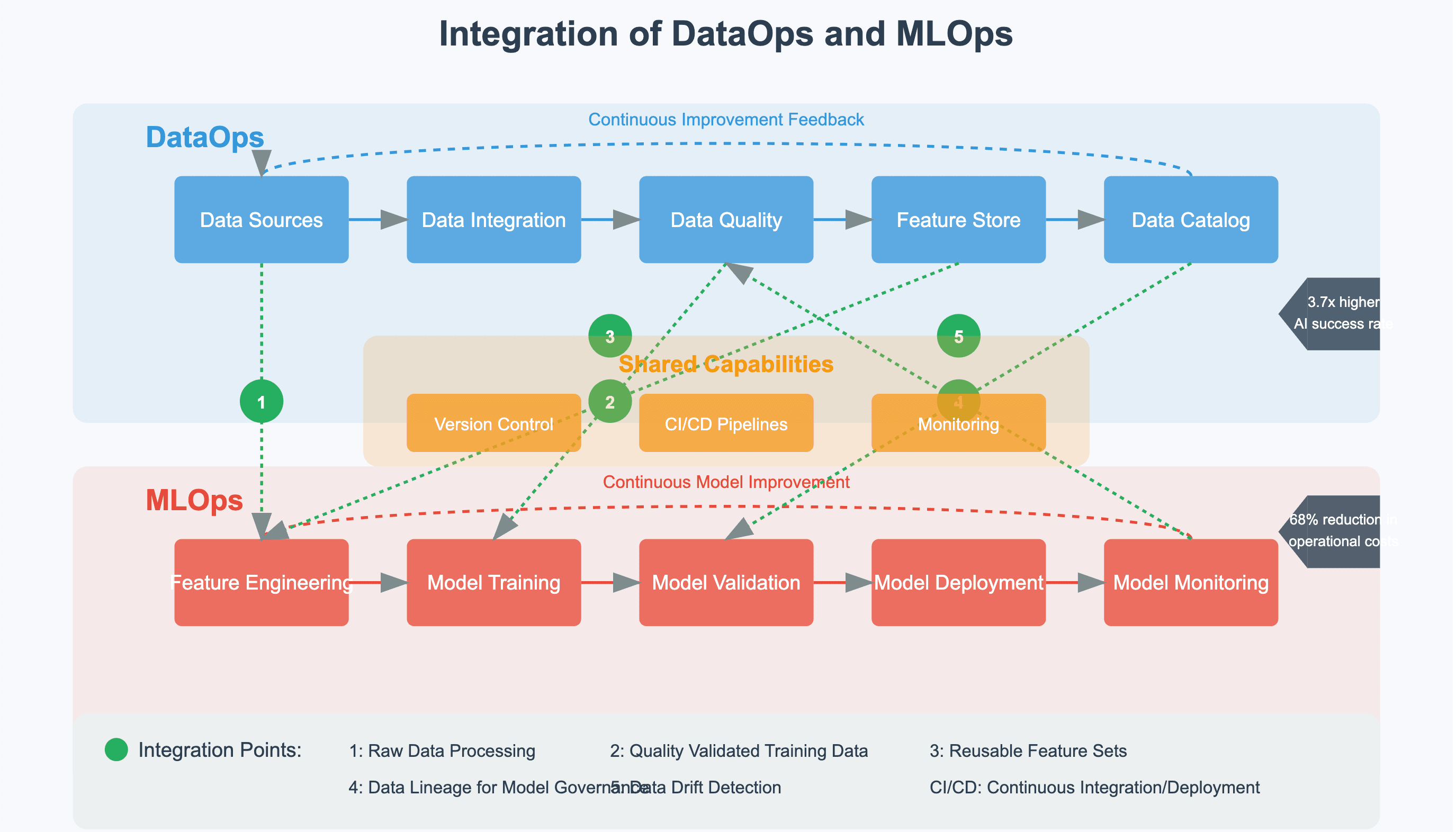
Collaboration models
Breaking down silos between data teams and data consumers is essential:
-
Embedded data engineers within domain teams
-
Communities of practice across organizational boundaries
-
Shared metrics between data producers and consumers
-
Collaborative discovery processes for new data needs
According to a Harvard Business Review analysis, cross-functional data teams reduce time-to-value for AI initiatives by 60% compared to centralized models.
Skills transition for traditional data teams
As data architecture evolves, organizations must invest in workforce transformation:
-
Upskilling database administrators in distributed systems
-
Training data modelers in schema-on-read paradigms
-
Developing data engineers’ expertise in scalable, event-driven architectures
-
Building data governance capabilities focused on enablement rather than control
Deloitte’s 2024 Tech Trends report indicates that organizations investing in data team transformation achieve 2.8x higher ROI on their AI investments compared to those maintaining traditional skill divisions.
Cultural transformation in traditional environments
Beyond technical skills, successful architecture transformation requires cultural change:
Manufacturing culture shiftsTraditional manufacturing environments often operate with siloed data ownership. A global manufacturer implemented a change management program alongside their data mesh implementation, focusing on redefining data as a shared asset rather than departmental property. This reduced cross-functional friction and accelerated AI adoption.
Healthcare collaborative modelsClinical and operational teams in healthcare traditionally operate independently. A regional health system created cross-functional data product teams with clinical, IT, and data science representation, reducing AI implementation time by 70% while improving clinical adoption rates.
Implementation roadmap
Assessment frameworks
Before implementing new architecture, organizations should conduct a thorough assessment:
-
Data Architecture Maturity Model evaluation (DAMM)
-
Technical debt quantification in existing data systems
-
Data flow analysis to identify bottlenecks
-
Governance gap assessment against regulatory requirements
Gartner recommends using their Data Management Infrastructure Model as a framework to identify architectural gaps most likely to impact AI initiatives.
Phased implementation approach
Successful implementations follow a pragmatic, value-driven approach:
-
Foundation Phase: Establish core governance, catalogs, and quality frameworks
-
Acceleration Phase: Implement domain-specific data products for high-value use cases
-
Scaling Phase: Deploy enterprise-wide architectural patterns and self-service capabilities
-
Optimization Phase: Continuously refine based on operational metrics and emerging requirements
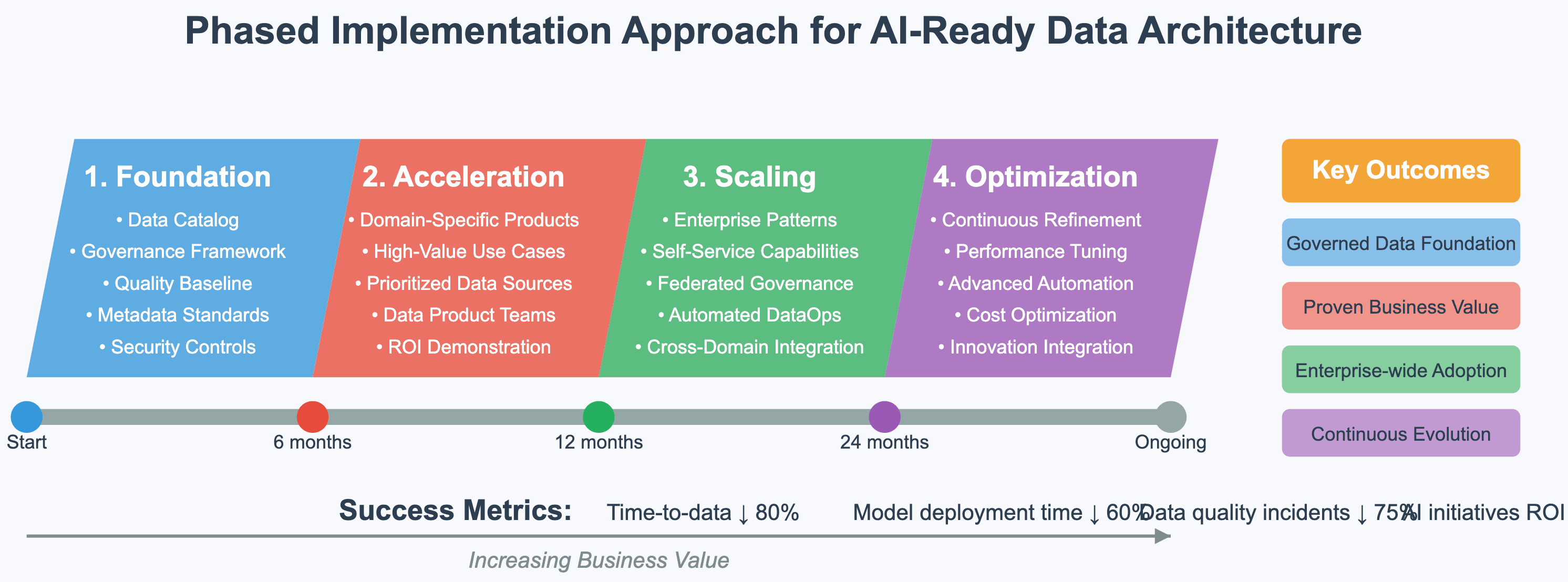
Healthcare provider’s data architecture transformationA large healthcare system implemented this phased approach, focusing initially on patient outcome prediction use cases. By delivering value incrementally, they maintained executive support through a three-year transformation that ultimately reduced clinical decision support deployment time from months to days.
Common pitfalls and mitigation strategies
Organizations should proactively address these frequent failure points:
-
Technology-First Approaches: Prioritize use cases and requirements before technology selection
-
Big Bang Implementations: Use domain-specific pilots to demonstrate value before scaling
-
Overlooking Organizational Change: Invest in skills development parallel to technology changes
-
Excessive Customization: Leverage industry reference architectures and patterns where possible
According to Forrester, 76% of failed data architecture initiatives cite at least two of these factors as primary contributors.
ROI calculation methodology
Measuring the financial impact of data architecture investments requires a comprehensive framework:
-
Direct cost reduction from consolidated infrastructure
-
Operational efficiency gains from reduced data preparation time
-
Revenue impact from faster time-to-market for AI initiatives
-
Risk mitigation value from improved governance and compliance
McKinsey’s Total Impact of Data (TID) methodology provides a structured approach to calculating these benefits, with most enterprises reporting 3-8x ROI on data architecture investments supporting AI initiatives.
Industry-specific ROI metrics
Different industries require tailored ROI approaches:
Healthcare value metricsTraditional ROI calculations often miss healthcare-specific benefits. Leading healthcare systems measure:
-
Patient outcome improvements
-
Length-of-stay reductions
-
Preventable readmission decreases
-
Staff time redirection to patient care
The Cleveland Clinic documented a 3.2x financial return on data architecture investments while achieving a 16% reduction in average length of stay through AI-enabled care optimization.
Manufacturing performance indicatorsIndustrial organizations track:
-
Overall equipment effectiveness improvements
-
Reduction in unplanned downtime
-
Energy efficiency gains
-
Quality improvement metrics
A global chemical manufacturer achieved 11% unplanned downtime reduction through AI-enabled predictive maintenance, enabled by their modernized data architecture.
Total cost of ownership comparison
Comprehensive TCO analysis must consider all relevant factors:
| Architecture Component | Traditional Architecture | Modern AI-Ready Architecture | Difference |
|---|---|---|---|
| Infrastructure Costs | High (redundant systems) | Medium (efficient resource usage) | -40% |
| Operational Management | High (manual processes) | Medium (automation) | -35% |
| Data Integration Effort | Very High (point-to-point) | Medium (standardized patterns) | -60% |
| Governance Overhead | Medium (manual) | Low (automated) | -50% |
| Time-to-Value for AI | Months to Years | Days to Weeks | -85% |
| Maintenance and Updates | High (complex dependencies) | Medium (modular architecture) | -45% |
| Regulatory Compliance | High (manual documentation) | Medium (automated lineage) | -55% |
Architecture ComponentTraditional ArchitectureModern AI-Ready ArchitectureDifferenceInfrastructure CostsHigh (redundant systems)Medium (efficient resource usage)-40%Operational ManagementHigh (manual processes)Medium (automation)-35%Data Integration EffortVery High (point-to-point)Medium (standardized patterns)-60%Governance OverheadMedium (manual)Low (automated)-50%Time-to-Value for AIMonths to YearsDays to Weeks-85%Maintenance and UpdatesHigh (complex dependencies)Medium (modular architecture)-45%Regulatory ComplianceHigh (manual documentation)Medium (automated lineage)-55%
Source: Enterprise Data Architects Council, 2024
Cross-jurisdictional compliance framework
Organizations operating globally need a structured approach to map data architecture capabilities to regulatory requirements:
| Architectural Capability | EU (GDPR, AI Act) | US (CCPA, NIST AI) | China (PIPL, Algorithm Regulations) |
|---|---|---|---|
| Data Minimization | Mandatory | Recommended | Mandatory |
| Purpose Limitation | Mandatory | Varies by State | Mandatory |
| Data Lineage | Mandatory | Recommended | Mandatory |
| Access Controls | Mandatory | Mandatory | Mandatory |
| Impact Assessments | Mandatory for High-Risk AI | Recommended | Mandatory |
| Retention Policies | Mandatory | Varies by State | Mandatory |
| Privacy by Design | Mandatory | Recommended | Mandatory |
| Processing Documentation | Mandatory | Varies by Sector | Mandatory |
| Data Subject Rights | Extensive | Limited | Limited |
| Cross-Border Controls | Restrictive | Minimal | Very Restrictive |
Architectural CapabilityEU (GDPR, AI Act)US (CCPA, NIST AI)China (PIPL, Algorithm Regulations)Data MinimizationMandatoryRecommendedMandatoryPurpose LimitationMandatoryVaries by StateMandatoryData LineageMandatoryRecommendedMandatoryAccess ControlsMandatoryMandatoryMandatoryImpact AssessmentsMandatory for High-Risk AIRecommendedMandatoryRetention PoliciesMandatoryVaries by StateMandatoryPrivacy by DesignMandatoryRecommendedMandatoryProcessing DocumentationMandatoryVaries by SectorMandatoryData Subject RightsExtensiveLimitedLimitedCross-Border ControlsRestrictiveMinimalVery Restrictive
Source: Data Architecture Compliance Consortium, 2024
Analysis of current trends
Unified data and AI platforms
The market is rapidly converging toward unified platforms that combine data processing, feature engineering, model training, and deployment. Vendors like Databricks, Snowflake, and cloud hyperscalers are aggressively expanding their offerings to create end-to-end environments.
This convergence simplifies architecture but raises concerns about vendor lock-in. Organizations should maintain architectural abstraction layers that allow component substitution as the market evolves.
Data mesh as an organizational and architectural pattern
Data mesh adoption continues to accelerate, with 42% of Fortune 500 companies now implementing some form of domain-oriented data architecture (Gartner, 2024). The transition from theoretical concept to operational reality is being driven by:
-
Recognition that centralized data teams cannot scale to enterprise-wide AI needs
-
Improved tooling for federated governance and quality control
-
Domain teams’ demand for greater data autonomy
-
The need to align data ownership with business outcomes
However, organizations must avoid treating data mesh as a silver bullet. Successfully implementation requires significant organizational maturity and clear domain boundaries.
Real-time data processing
According to IDC, the percentage of AI systems requiring real-time data processing will increase from 45% to 72% between 2023 and 2025. This shift is driving:
-
Greater investment in event streaming platforms
-
Migration from batch-oriented ETL to continuous CDC
-
Adoption of materialized views and incremental computation
-
Deployment of edge processing capabilities to reduce latency
Organizations with legacy batch architectures face significant competitive disadvantage as real-time AI capabilities become table stakes in industries like financial services, retail, and manufacturing.
Data governance automation
Manual governance processes cannot scale to meet the demands of enterprise AI. The trend toward automated governance includes:
-
ML-powered sensitive data detection and classification
-
Automated policy enforcement through code rather than committees
-
Data contracts that formalize producer-consumer relationships
-
Continuous compliance monitoring rather than point-in-time audits
Gartner predicts that by 2026, organizations with automated governance will spend 70% less on compliance while achieving higher levels of risk management.
Self-service data preparation
The expansion of AI capabilities across the enterprise requires democratization of data preparation:
-
Low/no-code data transformation tools for domain experts
-
Guided data quality remediation workflows
-
AI-assisted feature engineering
-
Reusable transformation templates with governance guardrails
According to Forrester, organizations with mature self-service capabilities deploy 3.4x more AI use cases annually compared to those relying exclusively on centralized data engineering teams.
Future outlook
Prediction 1: convergence of data and AI infrastructure
The artificial separation between data management and AI systems is rapidly dissolving. Within three years, we expect to see:
-
Unified metadata models spanning data assets and AI models
-
Integrated lineage from source systems to model outputs
-
Converged governance frameworks for data and algorithms
-
Combined DataOps and MLOps practices as the standard operating model
This convergence will reduce complexity and increase agility, but requires significant reskilling of existing teams.
Prediction 2: increased regulation demanding more robust data architectures
Regulatory frameworks like the EU’s AI Act, China’s algorithmic regulations, and emerging US standards are placing unprecedented demands on data infrastructure:
-
Explicit training data documentation requirements
-
Mandatory bias testing and mitigation capabilities
-
Continuous model surveillance obligations
-
Requirements for human oversight and intervention
Organizations without appropriate data architecture will find themselves unable to deploy AI in regulated contexts, creating an expanding competitive gap between leaders and laggards.
Prediction 3: industry-specific reference architectures
The “one size fits all” approach to data architecture is giving way to industry-specific patterns:
-
Financial services architectures optimized for regulatory reporting and real-time risk assessment
-
Healthcare designs focused on interoperability and privacy-preserving computation
-
Manufacturing patterns built around sensor networks and edge processing
-
Retail architectures optimized for omnichannel customer data integration
These reference architectures will accelerate implementation while ensuring alignment with industry-specific requirements.
Prediction 4: automated data architecture optimization
AI itself will increasingly optimize data architecture:
-
Automated workload analysis and resource allocation
-
Intelligent data tiering based on usage patterns
-
Self-optimizing query execution and caching
-
Automated identification and remediation of performance bottlenecks
This shift toward self-tuning infrastructure will reduce operational overhead while improving performance, particularly for organizations with limited specialized talent.
Prediction 5: knowledge graphs for contextual AI reasoning
Traditional relational and even NoSQL data models struggle to represent complex relationships needed for advanced AI reasoning. Knowledge graphs will emerge as a foundational architectural component:
-
Entity-relationship mapping across domains
-
Ontological frameworks for common understanding
-
Semantic reasoning capabilities beyond statistical approaches
-
Context preservation across diverse data sources
Early adopters are already seeing 40-60% improvements in recommendation accuracy and 30% reduction in data integration costs.
Prediction 6: neuromorphic computing implications
Emerging neuromorphic computing architectures will place new demands on data infrastructure:
-
Event-based data representation for spiking neural networks
-
Asynchronous processing models unlike traditional batch or stream
-
Continuous learning paradigms requiring new data management approaches
-
Energy-optimized data representations for edge deployment
Leading research institutions and technology companies are developing specialized data architectures to support these novel computation models.
Prediction 7: quantum-resistant data security
As quantum computing advances, data architectures must evolve to maintain security:
-
Post-quantum cryptography for data at rest and in transit
-
New key management infrastructure for quantum-resistant algorithms
-
Identity frameworks resistant to quantum factorization attacks
-
Long-term archival strategies for data that must remain secure beyond the quantum threshold
Organizations with critical long-lived data assets are already implementing quantum-resistant architecture components as part of their strategic roadmaps.
Conclusion
As AI transitions from experimental curiosity to business-critical infrastructure, data architecture has emerged as the fundamental determinant of success. Organizations that treat data architecture as a strategic capability rather than a technical implementation detail consistently outperform their peers in AI adoption, achieving:
-
5.3x faster time-to-value for new AI initiatives
-
68% lower operational costs for AI systems
-
74% higher user adoption of AI capabilities
-
84% fewer compliance-related implementation delays
The distinction between “AI companies” and traditional enterprises is increasingly determined not by their AI algorithms, which are often commoditized through vendors and open source, but by their ability to mobilize high-quality, governed data at scale.
For executive teams, the implications are clear: data architecture is not an IT cost center but critical business infrastructure that directly impacts competitive positioning. Organizations that invest strategically in data architecture create an expanding advantage that competitors with ad-hoc approaches cannot overcome.
The time has passed for incremental improvements and proof-of-concepts. To succeed in the AI-driven future, organizations must fundamentally reimagine their data architecture with the discipline, investment, and executive focus that this foundational capability deserves.
References
Armbrust, M., Das, T., Sun, L., et al. (2023). Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. CIDR 2021.
Davenport, T., & Bean, R. (2023). The Hidden Costs of Poor Data Architecture. Harvard Business Review, 101(4), 68-74.
Dehghani, Z. (2023). Data Mesh: Delivering Data-Driven Value at Scale. O’Reilly Media.
Gartner. (2024). Market Guide for Data Architecture. Gartner Research.
McKinsey Global Institute. (2024). The Age of Analytics: Competing in a Data-Driven World. McKinsey & Company.
MIT Technology Review. (2024). AI Infrastructure: The Business Capability That Determines AI Success. MIT Technology Review Insights.
Forrester Research. (2024). The Forrester Wave™: Enterprise Data Fabric, Q1 2024. Forrester Research Inc.
IDC. (2023). Worldwide Global DataSphere Forecast, 2023-2027. International Data Corporation.
ThoughtWorks. (2024). Data Mesh Implementation Survey Results. ThoughtWorks Inc.
Ponemon Institute. (2024). The State of Privacy-Preserving Technologies in Enterprise AI. Ponemon Research Report.
Enterprise Data Architects Council. (2024). TCO Benchmarking for AI-Ready Data Architectures. EDAC Annual Industry Report.
Data Architecture Compliance Consortium. (2024). Global Regulatory Requirements for AI Data Infrastructure. DACC Compliance Framework v2.0.
Why data architecture is key to scalable AI solutions.
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.