You Build it You Burn Out.
The cognitive load crisis and the rise of Platform Engineering
1. Summary
1.1 The Post-DevOps Paradigm Shift
The software engineering industry stands at a critical inflection point. For over a decade, the DevOps philosophy encapsulated by the mantra “you build it, you run it” has dominated the operational landscape. While this shift successfully dismantled the “wall of confusion” between development and operations, it inadvertently erected a new barrier: the “wall of cognitive load.” As cloud-native architectures have evolved from monolithic structures to complex distributed systems involving microservices, Kubernetes, and ephemeral infrastructure, the operational burden placed on individual application developers has become unsustainable.
Platform Engineering has emerged not as a rejection of DevOps, but as its industrialization. It represents the transition from a culture of generalized autonomy to one of structured, supported self-service. By treating the internal infrastructure platform as a product and the developer as a customer, organizations can arrest the decline in developer productivity, mitigate the risks of shadow IT, and enforce governance without sacrificing velocity.
This report synthesized over 100 industry sources including the CNCF, Gartner, and Team Topologies, provides an exhaustive analysis of this discipline. It argues that the future of cloud operations lies not in better pipelines or more complex scripting, but in a fundamental architectural shift toward “Infrastructure as Data” a model that favors typed contracts, proactive guardrails, and simplified, graph-based provisioning over the fragile, imperative automations of the past.
1.2 The Executive Presentation Narrative
For the Chief Technology Officer and Engineering Leadership
The Problem: The “TicketOps” and “Cognitive Load” Trap
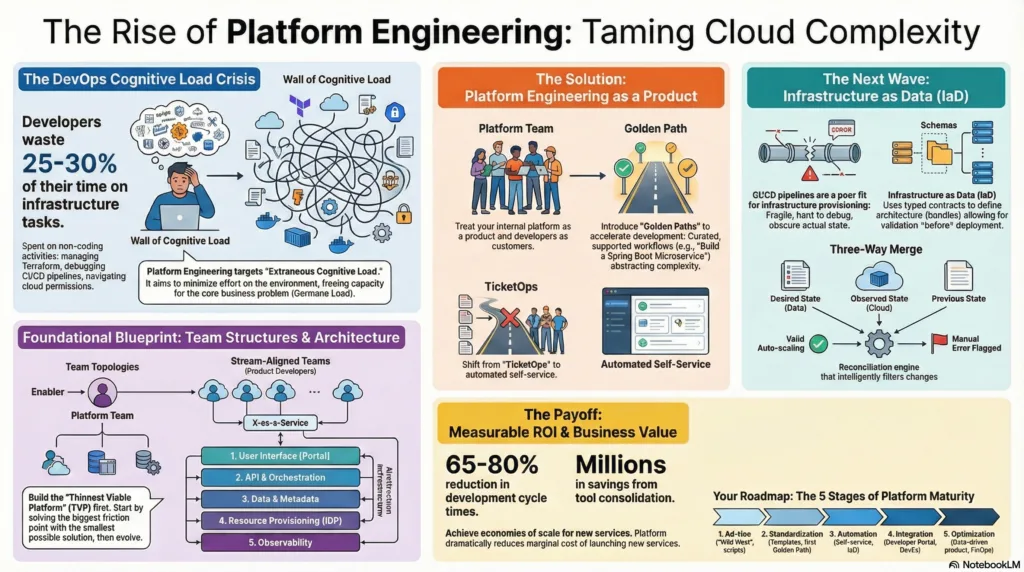
Our current operational model is facing diminishing returns. Despite heavy investment in cloud technologies, developer velocity is stalling. The root cause is not a lack of tooling, but an excess of it. Developers are spending approximately 25-30% of their time wrestling with infrastructure complexity managing Terraform state, debugging CI/CD pipelines, and navigating IAM permissions rather than writing business logic.1 This phenomenon, known as “extraneous cognitive load,” is a primary driver of burnout and attrition. Furthermore, the “TicketOps” anti-pattern remains prevalent: highly paid developers wait days for simple resource provisioning, or conversely, operations teams are drowning in repetitive requests, unable to focus on strategic improvements.2
The Solution: Platform as a Product
We must pivot to a Platform Engineering model. This means establishing a dedicated platform team whose mission is to build a “Golden Path” (or “Paved Road”) a curated, self-service experience that abstracts away the complexity of the underlying infrastructure while retaining its power. This platform is not a gatekeeper but a force multiplier.4 It allows developers to provision compliant infrastructure in minutes via high-level abstractions, while the platform team manages the standards, security, and scalability in the background.
The Economic Imperative
The ROI of Platform Engineering is measurable and significant. Organizations with mature platform capabilities report 65-80% reductions in development cycle time.1 Case studies from enterprises reveal cost savings in the millions through tool consolidation and license optimization.5 By centralizing the “heavy lifting” of operations, we achieve economies of scale that reduce the Total Cost of Ownership (TCO) for every new service launched.
Strategic Recommendation
We recommend the immediate adoption of a “Thinnest Viable Platform” (TVP) strategy.6 We will not boil the ocean by building a massive, all-encompassing PaaS from day one. Instead, we will identify the most friction-heavy developer workflows and pave those paths first. We will adopt an “Infrastructure as Data” approach to ensure long-term maintainability and prevent the “leaky abstraction” problems that plague traditional automation.
2. The Evolution of Software Delivery: From Silos to Cognitive Overload
2.1 The Historical Context: The DevOps Promise and Reality
To understand the necessity of Platform Engineering, one must first analyze the trajectory of DevOps. The movement began in roughly 2007-2008 as a reaction to the inefficiencies of siloed IT departments.7 The “wall of confusion” where developers threw code over the wall to system administrators who had no context for how to run it was the primary bottleneck. DevOps promised to solve this by merging the disciplines.
However, the definition of “DevOps” became diluted. In many organizations, it morphed into a role rather than a culture. The “DevOps Engineer” became a catch-all title for sysadmins who wrote scripts, or developers who were forced to manage Kubernetes clusters. As the cloud ecosystem exploded driven by the Cloud Native Computing Foundation (CNCF) landscape, which now boasts hundreds of projects the complexity of “running it” grew exponentially.8
The assumption that a single individual could master front-end frameworks, backend logic, database tuning, network security, and container orchestration proved to be a fallacy. The Puppet State of DevOps Report 2024 highlights that while high-performing organizations are twice as likely to exceed their goals, the “cognitive load” on developers in these environments has skyrocketed.9 The “You Build It, You Run It” model, when applied without support, results in “You Build It, You Burn Out.”
2.2 The Cognitive Load Crisis
Cognitive Load Theory, applied to software engineering, distinguishes between three types of load:
-
Intrinsic Load: The effort required to understand the core task (e.g., the Java syntax).
-
Germane Load: The effort required to solve the business problem (e.g., calculating interest rates).
-
Extraneous Load: The effort required to deal with the environment (e.g., remembering the AWS CLI command to rotate a key).10
Platform Engineering is specifically designed to minimize extraneous load. Gartner’s research indicates that platform engineering emerged as a direct response to the increasing complexity of modern software tools. By abstracting the “messy details” of infrastructure networking, storage, security compliance platforms release the productivity of engineering teams.11
2.3 The Developer’s Perspective: Friction and Fragmentation
From the perspective of a developer, the current landscape is often characterized by fragmentation. A developer might need to log into AWS to check a queue, Datadog to check logs, PagerDuty to check incidents, and GitHub to check code. This context switching is expensive.
Developers want to ship features. They do not want to become experts in the idiosyncrasies of Terraform state files or the nuances of DNS propagation. When forced to do so, they often resort to “Shadow IT” spinning up unmanaged resources to bypass the friction of official processes.4 A platform that fails to prioritize the developer experience (DevEx) will ultimately be bypassed.
The Platform Engineering Podcast emphasizes that the platform must be “compelling.” It cannot just be a mandate; it must offer a better user experience than the raw cloud provider console. If the platform is harder to use than AWS directly, it has failed.12
3. Theoretical Foundations: Cognitive Load & Team Topologies
3.1 The Four Team Types and Interaction Modes
The theoretical backbone of modern platform engineering is found in Team Topologies by Matthew Skelton and Manuel Pais. This framework provides a vocabulary for organizing teams to optimize for fast flow and reduced cognitive load.
The Four Team Types:
-
Stream-aligned teams: The primary value creators. They are aligned to a single stream of work (e.g., a product feature or user journey). They should be empowered to deliver value independently.
-
Enabling teams: Specialists who help stream-aligned teams acquire new capabilities (e.g., a security enabling team that teaches developers how to threat model).
-
Complicated Subsystem teams: Teams responsible for parts of the system that require such specialized knowledge (e.g., a video processing algorithm) that it would overburden a stream-aligned team.
-
Platform teams: The builders of the internal product. Their purpose is to enable stream-aligned teams to deliver work with substantial autonomy.13
The Three Interaction Modes:
Understanding how these teams interact is as important as the structure itself. Team Topologies defines three specific modes 10:
| Interaction Mode | Description | Context for Platform Engineering |
|---|---|---|
| X-as-a-Service | Consuming or providing something with minimal collaboration. | The Goal. A mature platform allows developers to consume infrastructure (databases, clusters) via an API or portal without ever talking to the platform team. This minimizes friction and cognitive load. |
| Collaboration | Working closely together for a defined period. | The Build Phase. When building a new platform capability, the platform team should collaborate closely with a “pilot” stream-aligned team to ensure the solution actually solves a real problem. Avoiding the “ivory tower” build. |
| Facilitating | Helping (or being helped by) another team to clear impediments. | The Support Phase. The platform team acts as coaches or support engineers to help developers understand how to use the platform effectively. |
Interaction ModeDescriptionContext for Platform Engineering****X-as-a-ServiceConsuming or providing something with minimal collaboration.The Goal. A mature platform allows developers to consume infrastructure (databases, clusters) via an API or portal without ever talking to the platform team. This minimizes friction and cognitive load.CollaborationWorking closely together for a defined period.The Build Phase. When building a new platform capability, the platform team should collaborate closely with a “pilot” stream-aligned team to ensure the solution actually solves a real problem. Avoiding the “ivory tower” build.FacilitatingHelping (or being helped by) another team to clear impediments.The Support Phase. The platform team acts as coaches or support engineers to help developers understand how to use the platform effectively.
3.2 Conway’s Law and the Inverse Conway Maneuver
Conway’s Law states that “organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations.” Platform Engineering leverages the Inverse Conway Maneuver: by designing the team structure (the platform team and its interfaces) to mirror the desired architecture (a decoupled, self-service infrastructure), organizations can force the technical architecture to evolve in that direction.10
By creating a platform team that interacts via “X-as-a-Service,” the organization enforces a clean decoupling between the application layer and the infrastructure layer. This prevents the “spaghetti code” dependency that arises when every developer is hacking on a shared Terraform repo.
3.3 The Thinnest Viable Platform (TVP)
A common pitfall is “over-engineering” building a massive, complex Kubernetes-based platform before there is a need for it. Team Topologies advocates for the Thinnest Viable Platform (TVP). The TVP is the smallest set of APIs, documentation, and tools needed to accelerate the stream-aligned teams.6
For a startup, the TVP might be a single wiki page listing the three approved AWS services and a link to a shared standard library. It does not need to be a custom-built portal. As the organization grows, the TVP evolves. Trade Me, a New Zealand marketplace, used this concept to redefine their platform not as a “thing” but as a set of building blocks, avoiding the trap of building a “monolith” platform that becomes a bottleneck itself.16
4. The Thesis: Infrastructure as Data & The End of Pipelines
4.1 The Critique of Pipelines
One of the most radical and insightful critiques of the current DevOps status quo is that CI/CD pipelines are a “poor fit for infra provisioning”.17
The Argument:
Pipelines are essentially scripts lists of imperative commands (run this, then run that). They are fragile. If a pipeline fails halfway through (e.g., during a network timeout), the infrastructure is left in an indeterminate state (a “partial apply”). Debugging a failed pipeline requires a developer to parse thousands of lines of log text, often without the necessary context.
Furthermore, pipelines obscure the state. They are a mechanism for change, not a representation of reality. Relying on pipelines for infrastructure creates a disconnect between the code (the intent) and the cloud (the reality).
4.2 Infrastructure as Data (IaD)
The proposed solution is Infrastructure as Data (IaD). Unlike Infrastructure as Code (IaC), which often involves writing logic (loops, conditionals) in languages like HCL or Python, IaD focuses on declaring the desired state using strict, typed data structures.17
Key Characteristics of IaD:
-
Typed Contracts: Every infrastructure component (a “bundle” in Massdriver’s parlance) has a strict input and output schema. A database bundle must output a connection string and an ARN. A consumer bundle must accept those exact types. This allows the platform to validate the architecture before any deployment happens. It is “type checking” for cloud architecture.17
-
Bundles and Artifacts: The unit of abstraction is the “bundle” a package of IaC (e.g., Terraform) wrapped in a data contract (massdriver.yaml). This wrapping hides the complexity of the HCL while exposing a clean configuration interface to the user.20
-
Visual and Graph-Based: Because the infrastructure is defined as structured data, it can be easily visualized as a graph. Users can drag-and-drop components, and the platform (Massdriver) knows which connections are valid based on the type system.20
4.3 Drift as a Three-Way Merge
Handling “drift” when someone manually changes a setting in the cloud console, diverging from the code is a classic DevOps nightmare. Traditional tools like Terraform simply say “drift detected” and offer to overwrite it. We need a more nuanced model: reasoning about drift as a three-way merge. The three inputs are:
-
The Desired State (Code/Data): What the repository says.
-
The Observed State (Cloud): What is running in AWS/Azure.
-
The Previous Known State: What the platform thought was running.
By comparing these three, the platform can intelligently reconcile changes. Did the cloud change because of an auto-scaling event (which is good and should be ignored)? Or did it change because of a manual hack (which is bad and should be reverted)? This level of intelligence is difficult to achieve with simple stateless pipelines.17
4.4 Capability vs. Simplicity
A vital distinction in this philosophy is that platform engineering is about capability, not just simplicity. If a platform simplifies Kubernetes by removing the ability to configure memory limits, it has reduced capability. The goal is to expose the capability through a simpler, safer interface (the data contract) rather than hiding it completely. Don’t be dumbing down the platform to the point where it becomes useless for power users.22
5. Architectural Reference Model: The Anatomy of a Platform
5.1 The Distinction: IDP vs. Portal
To build a successful platform, one must distinguish between the engine and the dashboard. Confusion between the Internal Developer Platform (IDP) and the Internal Developer Portal is common.
**ComponentDefinitionExamplesRoleInternal Developer Platform (IDP)**The backend machinery. The sum of all tech, tools, and workflows that execute the tasks.Kubernetes, Crossplane, Terraform, ArgoCD, Massdriver (backend)The “Engine.” Handles provisioning, deployment, policy enforcement, and orchestration.Internal Developer PortalThe frontend interface. The “pane of glass” for the user.Backstage, Port, Compass, Massdriver (UI)The “Dashboard.” Handles service catalog, documentation, scaffolding, and user interaction.
The CNCF emphasizes that the Portal is an interface that combines essential tools; it is an addition to, not a replacement for, the underlying platform execution layer.23 A portal without a platform is just a documentation site; a platform without a portal is powerful but hard to use.
5.2 The Component Architecture
A robust platform architecture consists of five distinct layers:
-
User Interface Layer (The Portal): This is where the developer starts. It includes the Service Catalog (what can I spin up?), the Scaffolder (create a new repo from a template), and the Documentation (TechDocs). Backstage is the industry standard here.24
-
API & Orchestration Layer: The “brain” of the platform. When a user clicks “Create Database,” this layer receives the request, validates it against policy, and orchestrates the fulfillment. This is where “Infrastructure as Data” shines the API validates the data contract.25
-
Data & Metadata Layer: The “knowledge graph” of the organization. It tracks who owns what service, which services depend on which databases, and the health status of each component. This visibility is crucial for incident response and cost allocation.26
-
Resource Provisioning Layer (The IDP Backend): The tools that actually talk to the cloud. This includes Terraform, Helm, Crossplane, or proprietary engines. In a mature platform, this layer is invisible to the developer; they interact with the abstraction, not the raw Terraform.27
-
Observability & Day-2 Operations Layer: Tools for logging, monitoring, and debugging. The platform should automatically wire these up. A “Golden Path” service should come with a dashboard pre-configured.28
5.3 Standardization Strategy: The “Golden Path”
The “Golden Path” (Spotify) or “Paved Road” (Netflix) is the core product of the platform. It represents an opinionated, supported workflow for a specific use case (e.g., “Build a Spring Boot Microservice”).
-
Supported: If a developer stays on the Golden Path, the platform team guarantees it works. PagerDuty alerts are pre-configured, security scanning is built-in, and upgrades are automated.
-
Optional: Crucially, usage is rarely mandatory. Developers can go “off-road,” but they lose the support. This “opt-in” model forces the platform team to build a product that is genuinely better than the alternative.29
5.4 Integration Patterns: The “Merge” Workflow
Shopify’s success with their platform (merging Ops and Dev) relied heavily on integrating platform workflows into the developers’ existing tools (GitHub). Rather than forcing developers to learn a new UI, they used “merge” requests (Pull Requests) as the trigger for platform actions. This “GitOps” approach aligns with the developer’s natural workflow, reducing friction.31
6. Case Studies in Excellence & Failure
6.1 Spotify: The Birth of Backstage
Spotify faced a fragmentation crisis. They had hundreds of microservices, and no one knew who owned what. New engineers took weeks to deploy their first service.
-
The Solution: They built Backstage, a developer portal centered on a “Software Catalog.”
-
The Mechanism: “Golden Paths” were created tutorials combined with scaffolding templates.
-
The Result: “Time to Hello World” dropped to minutes. The cognitive load of finding documentation or ownership info was eliminated. Backstage was open-sourced and is now a CNCF project.33
6.2 Netflix: The Paved Road to Security
Netflix’s scale (thousands of engineers, global availability) required a different approach. Their “Paved Road” is a set of integrated tools that handle the heavy lifting of distributed systems.
- The Insight: They used the platform to solve security. Instead of auditing every team, they built security into the Paved Road components. If you use the standard RPC library and the standard container base image, you are secure by default. This shifted the conversation from “compliance checking” to “platform adoption”.27
6.3 Massdriver: The “Infrastructure as Data” Pioneer
Massdriver challenged the notion that PaaS (Platform as a Service) had to be a “black box” like Heroku.
-
The Solution: A platform based on “bundles” (open-source Terraform modules wrapped in massdriver.yaml).
-
The Result: Developers get a visual diagram of their infrastructure. They can connect a “Kubernetes Cluster” bundle to a “Postgres” bundle by drawing a line. The platform handles the networking and IAM permissions automatically behind the scenes using the “Artifact” system. This proves that you can have the ease of use of a PaaS with the flexibility of custom IaC.20
6.4 Failure Modes: The “TicketOps” Trap & The “Platform for Everything”
Not all platform initiatives succeed. Gartner estimates 80% of organizations will have platform teams, but many will fail to deliver value.11
-
TicketOps: A common failure is rebranding the Ops team as “Platform” but changing nothing else. Developers still file JIRA tickets for resources. The “Platform Team” is just a bottleneck with a new name. This fails because it does not enable self-service.2
-
The Platform for Everything: Attempting to build a “Unicorn Platform” that abstracts every possible configuration option of AWS. This leads to the “Leaky Abstraction” problem. The platform becomes massive, buggy, and hard to maintain. When a developer needs a feature the platform doesn’t support, they are blocked. This is “Over-Engineering”.37
7. The Adoption Playbook: Maturity, Culture, and Governance
7.1 The Platform Engineering Maturity Model
Adoption is a journey. The CNCF and Humanitec define a maturity model to guide organizations.39
Stage 1: Ad-Hoc (The “Wild West”)
-
Characteristics: Developers write their own scripts. No standardization. “Hero culture” prevails (only Bob knows how to deploy to prod).
-
Action: Identify common patterns. Don’t build tools yet; build documentation. Start the “Thinnest Viable Platform” (wiki).
Stage 2: Standardization (The “Golden Path” v0.1)
-
Characteristics: Standard libraries and templates exist. CI/CD is used, but setup is manual.
-
Action: Create reusable Terraform modules. Define the first “Golden Path” for the most common app type.
Stage 3: Automation (The “Service”)
-
Characteristics: Self-service provisioning via scripts or CLI. Automated testing of infrastructure.
-
Action: Adopt “Infrastructure as Data.” Wrap scripts in typed contracts. Eliminate manual tickets.
Stage 4: Integration (The “Portal”)
-
Characteristics: A unified interface (Backstage/Portal). End-to-end orchestration.
-
Action: Focus on Developer Experience (DevEx). Measure adoption rates.
Stage 5: Optimization (The “Product”)
-
Characteristics: The platform is a product. Continuous improvement based on metrics. AI integration.
-
Action: Advanced cost optimization. FinOps integration. AI-driven remediation.
7.2 Building the Platform Team
A critical error is staffing the platform team solely with senior sysadmins.
-
The Product Manager: This is the most important hire. They must treat the platform as a product. They conduct user interviews, define the roadmap, and say “no” to features that don’t serve the broader user base.42
-
The Developer Advocate: The “salesperson” for the platform. They write tutorials, give internal talks, and help teams migrate.
-
The Engineers: Should have software engineering skills, not just scripting skills. They are building a software product (the platform), not just running servers.36
7.3 Governance and Risk Register
Platform engineering fundamentally changes how risk is managed.
The Risk Register:
Risk IDRisk NameDescriptionMitigation StrategyR01****Leaky AbstractionsThe platform hides too much, preventing developers from debugging deep issues.Glass-Box Design: Allow developers to “eject” or view the underlying IaC. Use “Infrastructure as Data” to make configs transparent.44R02****Adoption StagnationDevelopers ignore the platform and use Shadow IT.Product Mindset: Treat the platform as a product. Market it. Ensure the Golden Path is truly the path of least resistance.45R03****Drift & State DesyncThe platform’s view of reality diverges from the cloud state.Three-Way Merge: Implement sophisticated drift detection and reconciliation logic (e.g., Massdriver’s approach).17R04****Vendor Lock-inThe platform couples the org too tightly to a specific tool/vendor.Standardization: Use open standards (CNCF projects, OpenTofu). Define artifacts by contract, not by implementation.46
U build it u burn out Infographic
8. The Economic Imperative: ROI, TCO, and Business Value
8.1 Calculating ROI
To justify the investment, the platform must prove its value. The “business case” template revolves on three pillars: Velocity, Savings, and Stability.1
-
Savings (Tool Consolidation): A large enterprise saved £4 million annually by consolidating redundant tools (e.g., having 5 different CI tools) into a standardized platform offering.5
-
Stability (Uptime): Reduced downtime due to standardized, pre-validated infrastructure.
8.2 Total Cost of Ownership (TCO)
While building a platform is expensive upfront (the “J-Curve” of investment), it flattens the marginal cost of adding new services. In a non-platform org, adding the 100th service costs as much operational effort as the 1st. In a platform org, the 100th service is almost free to provision because the automation is already built. This “economy of scale” is the long-term financial driver.47
8.3 Qualitative Benefits
Beyond the numbers, the “State of DevOps” report consistently links platform maturity to organizational performance. High-performing teams have higher job satisfaction and lower burnout. In a tight talent market, a good platform is a recruiting asset. Developers want to work where they can ship code, not where they have to fight Kubernetes.9
9. Conclusion & Future Outlook
9.1 The Future is Agentic
As we look to the future, the intersection of AI and Platform Engineering is becoming the next frontier. “Agentic Workflows” where AI agents autonomously perform tasks will rely heavily on platforms.
-
Infrastructure as Data as the AI Interface: AI models struggle with imperative scripts but excel at understanding structured data and schemas. The “Infrastructure as Data” model (Massdriver) provides the perfect interface for AI agents to reason about and modify infrastructure safely.48
-
Feature Flags as Safety Rails: As AI begins to write and deploy code, the platform must provide safety mechanisms. Feature flags (as discussed in the podcast with Unleash) allow AI-generated features to be rolled out progressively and killed instantly if metrics degrade, providing the necessary “guardrails” for the AI era.17
9.2 Final Synthesis
Platform Engineering is the necessary evolution of DevOps for the cloud-native age. It acknowledges that cognitive load is the enemy of velocity. By shifting from imperative pipelines to declarative “Infrastructure as Data,” and from ticket-based operations to product-based self-service, organizations can achieve the dual goals of speed and stability.
The “Golden Path” is not a constraint, it is a liberation. It frees the developer from the burden of the “undifferentiated heavy lifting” of infrastructure, allowing them to focus on the creative work that drives business value. The journey from “Ad-Hoc” to “Optimized” is challenging, but the data proves that it is the only viable path for scaling software delivery in a complex world.
Appendix: Platform Engineering Reference Model Checklist
1. Culture & People
-
Establish a dedicated Platform Team (treated as a Product Team).
-
Hire a Product Manager for the platform.
-
Define “Team Topologies” interactions (X-as-a-Service vs. Collaboration).
2. Architecture & Tech
-
Define the “Thinnest Viable Platform” (TVP).
-
Separate the IDP (Engine) from the Portal (UI).
-
Adopt “Infrastructure as Data” (Typed Contracts/Bundles) over raw scripts.
-
Implement “Golden Paths” for the top 3 developer workflows.
3. Process & Governance
-
Shift Security Left (Policy-as-Code embedded in bundles).
-
Establish a “Three-Way Merge” strategy for drift management.
-
Create a Risk Register for platform adoption and abstraction leaks.
4. Metrics & ROI
-
Baseline DORA metrics (Deployment Frequency, Lead Time).
-
Measure Developer Satisfaction (NPS) and Cognitive Load.
-
Calculate TCO and ROI annually to justify continued investment.
Geciteerd werk
-
The ROI of Operational Platform Excellence | Foundations of Scale, geopend op december 7, 2025, https://foundationsofscale.com/resources/roi-whitepaper/
-
From DevOps to Platform engineering | Software Engineering Unlocked, geopend op december 7, 2025, https://www.software-engineering-unlocked.com/platform-engineering/
-
DevOps vs Platform engineering, I still struggle to understand the difference, Reddit, geopend op december 7, 2025, https://www.reddit.com/r/devops/comments/17lz167/devops_vs_platform_engineering_i_still_struggle/
-
What are Internal Developer Platforms?, DEV Community, geopend op december 7, 2025, https://dev.to/cyclops-ui/what-are-internal-developer-platforms-4idc
-
Case study: Tool standardisation and cost savings, RiverSafe, geopend op december 7, 2025, https://riversafe.co.uk/resources/case-studies/how-tool-standardisation-saved-a-large-enterprise-4-million/
-
Examples of a Thinnest Viable Platform (TVP) as defined in the book Team Topologies, GitHub, geopend op december 7, 2025, https://github.com/TeamTopologies/Thinnest-Viable-Platform-examples
-
The Evolution of Platform Engineering, DevOps Report, Carahsoft, geopend op december 7, 2025, https://static.carahsoft.com/concrete/files/3817/1596/6047/Perforce_DevOps_Wrapped_Resource_2024.pdf
-
Exploring the Thoughtworks Technology Radar, YouTube, geopend op december 7, 2025, https://www.youtube.com/watch?v=raYGdxc1zXY
-
The History of DevOps Reports | Puppet, geopend op december 7, 2025, https://www.puppet.com/resources/history-of-devops-reports
-
The Three Team Interaction Modes, IT Revolution, geopend op december 7, 2025, https://itrevolution.com/articles/the-three-team-interaction-modes/
-
Unlock Infrastructure Efficiency with Platform Engineering, Gartner, geopend op december 7, 2025, https://www.gartner.com/en/infrastructure-and-it-operations-leaders/topics/platform-engineering
-
What Is Platform Engineering? From A Developer’s Perspective, Apple Podcasts, geopend op december 7, 2025, https://podcasts.apple.com/us/podcast/what-is-platform-engineering-from-a-developers/id1729594542?i=1000644491875
-
Key concepts and practices for applying a Team Topologies approach to team-of-teams org design Team Topologies, Organizing for fast flow of value, geopend op december 7, 2025, https://teamtopologies.com/key-concepts
-
Newsletter (FEBRUARY 2025): Team Topologies Interaction Modes: Breaking Through Common Misconceptions, geopend op december 7, 2025, https://teamtopologies.com/news-blogs-newsletters/2025/2/21/team-topologies-interaction-modes-breaking-through-common-misconceptions
-
What is a Thinnest Viable Platform (TVP)? Team Topologies, Organizing for fast flow of value, geopend op december 7, 2025, https://teamtopologies.com/key-concepts-content/what-is-a-thinnest-viable-platform-tvp
-
Trade Me’s Journey Towards a Thinnest Viable Platform (TVP) Team Topologies, Organizing for fast flow of value, geopend op december 7, 2025, https://teamtopologies.com/industry-examples/trade-me-journey-towards-a-thinnest-viable-platform
-
Platform Engineering Podcast, Captivate, geopend op december 7, 2025, https://feeds.captivate.fm/platform-engineering/
-
Beyond GitOps: Rethinking Cloud Self-Service with Dave Williams, YouTube, geopend op december 7, 2025, https://www.youtube.com/watch?v=P5MbHKu_3Uw
-
Guest Host: Kelsey Hightower, Beyond Pipelines: Infrastructure As Data, geopend op december 7, 2025, https://platformengineeringpod.com/episode/guest-host-kelsey-hightower-beyond-pipelines-infrastructure-as-data
-
Massdriver Docs | Massdriver Docs, geopend op december 7, 2025, https://docs.massdriver.cloud/
-
Create, Massdriver Docs, geopend op december 7, 2025, https://docs.massdriver.cloud/applications/create
-
Platform Engineering Maturity Model | CNCF TAG App Delivery, geopend op december 7, 2025, https://tag-app-delivery.cncf.io/whitepapers/platform-eng-maturity-model/
-
A conversation about the Future of Internal Developer Portals (IDPs) | CNCF, geopend op december 7, 2025, https://www.cncf.io/blog/2024/09/30/a-conversation-about-the-future-of-internal-developer-portals-idps/
-
DevEx Series 01: Creating Golden Paths with Backstage, Developer Self-Service Without Losing Control, Gökhan Gökalp, geopend op december 7, 2025, https://gokhan-gokalp.com/devex-series-01-creating-golden-paths-with-backstage-developer-self-service-without-losing-control/
-
Design a Developer Self-Service Foundation | Microsoft Learn, geopend op december 7, 2025, https://learn.microsoft.com/en-us/platform-engineering/developer-self-service
-
Federated Governance Model: The #1 Blueprint, Lifebit, geopend op december 7, 2025, https://lifebit.ai/blog/federated-governance-complete-guide/
-
From Paralysis to Paved Roads: How Platform Engineering Resolves the Cognitive Crisis in DevOps and SRE | by Gareth Brown | Google Cloud, Community | Oct, 2025 | Medium, geopend op december 7, 2025, https://medium.com/google-cloud/from-paralysis-to-paved-roads-how-platform-engineering-resolves-the-cognitive-crisis-in-devops-and-35fcbe8f7fdf
-
The “Paved Road” PaaS for Microservices at Netflix: Yunong Xiao at QCon NY, InfoQ, geopend op december 7, 2025, https://www.infoq.com/news/2017/06/paved-paas-netflix/
-
Designing Golden Paths, Red Hat, geopend op december 7, 2025, https://www.redhat.com/en/blog/designing-golden-paths
-
How Spotify Leverages Paved Paths and Common Tooling to Improve Productivity, InfoQ, geopend op december 7, 2025, https://www.infoq.com/news/2021/03/spotify-paved-paths/
-
Studying Pull Request Merges: A Case Study of Shopify’s Active Merchant, Olga Baysal, geopend op december 7, 2025, https://olgabaysal.com/pdf/Kononenko_ICSE2018.pdf
-
Studying pull request merges: a case study of shopify’s active merchant, ResearchGate, geopend op december 7, 2025, https://www.researchgate.net/publication/325733515_Studying_pull_request_merges_a_case_study_of_shopify’s_active_merchant
-
Backstage: The Developer Portal that organizations need for their developers, geopend op december 7, 2025, https://www.thoughtworks.com/en-us/insights/blog/agile-engineering-practices/backstage-developer-portal-que-las-organizaciones-necesitan-para-sus-desarrolladores
-
How We Use Golden Paths to Solve Fragmentation in Our Software Ecosystem, geopend op december 7, 2025, https://engineering.atspotify.com/2020/08/how-we-use-golden-paths-to-solve-fragmentation-in-our-software-ecosystem
-
The Show Must Go On: Securing Netflix Studios At Scale, geopend op december 7, 2025, https://netflixtechblog.com/the-show-must-go-on-securing-netflix-studios-at-scale-19b801c86479
-
What is Platform Engineering?, Massdriver, geopend op december 7, 2025, https://www.massdriver.cloud/blogs/what-is-platform-engineering
-
charlax/professional-programming: A collection of learning resources for curious software engineers, GitHub, geopend op december 7, 2025, https://github.com/charlax/professional-programming
-
9 Platform Engineering Anti-Patterns That Kill Adoption, Jellyfish, geopend op december 7, 2025, https://jellyfish.co/library/platform-engineering/anti-patterns/
-
Understanding the Platform Engineering Maturity Model, Jellyfish, geopend op december 7, 2025, https://jellyfish.co/library/platform-engineering/maturity-model/
-
Understanding the Platform Engineering Maturity Model: A Path to Optimized Operations, geopend op december 7, 2025, https://dev.to/craftworkai/understanding-the-platform-engineering-maturity-model-a-path-to-optimized-operations-3mno
-
Whitepaper: State of Platform Engineering Report Volume 3 | Humanitec, geopend op december 7, 2025, https://humanitec.com/whitepapers/state-of-platform-engineering-report-volume-3
-
Puppet’s 2024 State of DevOps Report Reveals Security is Strengthened by Platform Engineering | Perforce Software, geopend op december 7, 2025, https://www.perforce.com/press-releases/puppets-2024-state-devops-report
-
The State of DevOps Report 2024: The Evolution of Platform Engineering is Live, Get Your Copy Now | Puppet, geopend op december 7, 2025, https://www.puppet.com/blog/state-devops-report-2024
-
Leaky by Design. Joel Spolsky came up with the term… | by Terry Crowley | Medium, geopend op december 7, 2025, https://medium.com/@terrycrowley/leaky-by-design-7b423142ece0
-
Why Up to 70% of Platform Engineering Teams Fail to Deliver Impact, The New Stack, geopend op december 7, 2025, https://thenewstack.io/why-up-to-70-of-platform-engineering-teams-fail-to-deliver-impact/
-
Episode 20, Platform Engineering Podcast, geopend op december 7, 2025, https://www.platformengineeringpod.com/episodes/5
-
The 4 hidden costs impacting software ROI, HTEC, geopend op december 7, 2025, https://htec.com/insights/blogs/software-roi-hidden-costs/
-
Technology Radar | Guide to technology landscape | Thoughtworks United States, geopend op december 7, 2025, https://www.thoughtworks.com/en-us/radar
Tabellen uit het originele artikel
Tabel 2
| Component | Definition | Examples | Role |
|---|---|---|---|
| Internal Developer Platform (IDP) | The backend machinery. The sum of all tech, tools, and workflows that execute the tasks. | Kubernetes, Crossplane, Terraform, ArgoCD, Massdriver (backend) | The “Engine.” Handles provisioning, deployment, policy enforcement, and orchestration. |
| Internal Developer Portal | The frontend interface. The “pane of glass” for the user. | Backstage, Port, Compass, Massdriver (UI) | The “Dashboard.” Handles service catalog, documentation, scaffolding, and user interaction. |
Tabel 3
| Risk ID | Risk Name | Description | Mitigation Strategy |
|---|---|---|---|
| R01 | Leaky Abstractions | The platform hides too much, preventing developers from debugging deep issues. | Glass-Box Design: Allow developers to “eject” or view the underlying IaC. Use “Infrastructure as Data” to make configs transparent.^44 |
| R02 | Adoption Stagnation | Developers ignore the platform and use Shadow IT. | Product Mindset: Treat the platform as a product. Market it. Ensure the Golden Path is truly the path of least resistance.^45 |
| R03 | Drift & State Desync | The platform’s view of reality diverges from the cloud state. | Three-Way Merge: Implement sophisticated drift detection and reconciliation logic (e.g., Massdriver’s approach).^17 |
| R04 | Vendor Lock-in | The platform couples the org too tightly to a specific tool/vendor. | Standardization: Use open standards (CNCF projects, OpenTofu). Define artifacts by contract, not by implementation.^46 |
Presentatie: You Build it You Burn Out
You Build it You Burn Out
You Build it You Burn Out.
Dit artikel is exclusief beschikbaar voor nieuwsbrief-abonnees. Schrijf je in voor toegang tot 880+ artikelen.
Geen spam. Uitschrijven op elk moment.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.