Google's PAT bewijst: AI kan wetenschappelijke fouten vinden die mensen missen - wat betekent dat voor compliance?
Google Research publiceerde vorige week een paper die het gesprek over AI-governance fundamenteel verandert. Niet omdat het weer een nieuw model aankondigt. Maar omdat het een werkend systeem beschrijft dat wetenschappelijke fouten opspoort die menselijke experts maandenlang over het hoofd zagen, en dat met een nauwkeurigheid van 89,7%.
De Paper Assistant Tool (PAT) is een agentic AI-framework dat volledige wetenschappelijke manuscripten doorlicht op theoretische fouten, experimentele validatie en logische consistentie. Het werd ingezet bij STOC en ICML, twee topconferenties in de computerwetenschap. De resultaten zijn ongemakkelijk voor iedereen die dacht dat AI-gedreven kwaliteitscontrole nog jaren weg was.
De cijfers die ertoe doen
De paper Towards Automating Scientific Review with Google's Paper Assistant Tool rapporteert drie kerncijfers:
| Metriek | Zero-shot (Gemini 3.1 Pro) | PAT (inference scaling) |
|---|---|---|
| Foutdetectie op SPOT benchmark | 55,2% | 89,7% |
| Verbetering t.o.v. zero-shot | , | +34% |
| Auteurs die substantiële theorie-fouten vonden | , | 35,4% (ICML) |
| Auteurs die nieuwe experimenten draaiden | , | 31% (ICML) |
De SPOT-benchmark bevat papers met geverifieerde fouten die tot errata of retracties leidden. Een zero-shot model vindt ongeveer de helft. PAT vindt bijna alles.
Bij de ICML-pilot gaf 35,4% van de 733 respondenten aan dat PAT significante fouten in theoretische resultaten identificeerde, fouten die meer dan een uur kostten om te repareren. Eén op de drie auteurs draaide volledig nieuwe experimenten op basis van PAT's feedback.
Hoe PAT werkt: vier fasen van inference scaling
De architectuur is relevant omdat het een blauwdruk biedt voor elk AI-systeem dat documenten moet beoordelen op juistheid, of dat nu wetenschappelijke papers zijn, compliance-rapportages of aanbestedingsdocumenten.
Fase 1, Documentsegmentatie. Een segmenter-agent deelt het manuscript op in semantische componenten (theorie, methodologie, experimenten). Segmenten mogen overlappen en niet-contigu zijn.
Fase 2, Adaptieve budgettering. Op basis van informatiedichtheid en complexiteit krijgt elk segment een compute-budget toegewezen. Theorie-secties krijgen "high thinking", introducties "light thinking".
Fase 3, Deep Review. Gespecialiseerde agents verifiëren elk segment met deep inference scaling. Ze krijgen het volledige paper als context, maar focussen op hun toegewezen segment. Dit voorkomt dat het model zijn contextbudget verspilt aan irrelevante secties.
Fase 4, Globale synthese. Een synthese-agent combineert de deelrapporten, dedupliceert bevindingen, en gebruikt Google Search als ground-truth check tegen hallucinaties (niet-bestaande papers, verzonnen stellingen).
Deze architectuur lost twee fundamentele problemen van Pass@k scaling op: (1) hallucinatie-stapeling, 10 onafhankelijke runs produceren ~100 potentiële issues waarvan er misschien één klopt, en (2) context-verspilling, zonder orchestratie besteden onafhankelijke calls hun context aan dezelfde secties.
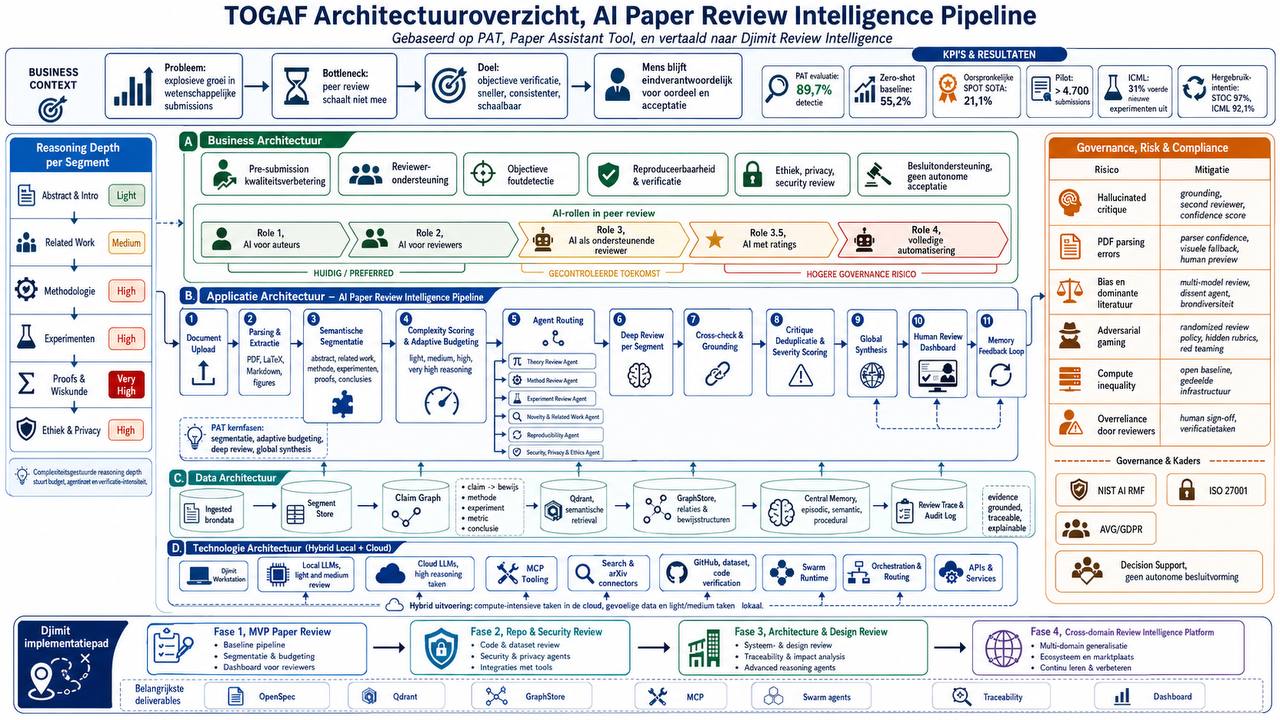
De 4-rol taxonomie: van tool tot totale automatisering
Het meest waardevolle deel van de paper is niet de techniek, maar de taxonomie. De auteurs definiëren vier rollen voor AI in peer review:
| Rol | Beschrijving | Huidige status |
|---|---|---|
| Rol 1: Tool voor auteurs | AI helpt auteurs vóór indiening | STOC/ICML pilots, operationeel |
| Rol 2: Tool voor reviewers | AI assisteert reviewers bij beoordeling | In ontwikkeling |
| Rol 3: Ondersteunend reviewer | AI produceert volledige review, mens beslist | Experimenteel (AAAI-26 pilot) |
| Rol 3.5: Met subjectief oordeel | AI geeft ook acceptatie-aanbeveling | Nog niet operationeel |
| Rol 4: Volledige automatisering | AI beslist over publicatie | Toekomstscenario |
Deze taxonomie is niet alleen relevant voor wetenschappelijke peer review. Het is een direct toepasbaar framework voor AI-governance in de publieke sector.
Wat dit betekent voor AI-governance in de Nederlandse publieke sector
De PAT-taxonomie is een governance-instrument dat verder reikt dan academische publicaties. Vervang "paper" door "aanbestedingsdocument", "beleidsnota" of "DPIA" en je hebt hetzelfde validatieprobleem.
Rol 1 (Tool voor auteurs) → AI-assistentie bij compliance-documentatie. Een AI-systeem dat BIO2-zelfevaluaties of DPIA's doorlicht op inconsistenties en omissies vóór indiening bij een toezichthouder. Dit is het laagste risiconiveau, de eindverantwoordelijkheid blijft bij de auteur.
Rol 2 (Tool voor reviewers) → AI-ondersteuning bij audits. Een auditor gebruikt AI om een NIS2-compliance-rapportage te screenen op tegenstrijdigheden of gemiste controls. De auditor blijft eindverantwoordelijk voor het oordeel.
Rol 3 (Ondersteunend reviewer) → AI als technisch beoordelaar. Een AI-systeem produceert een volledige conformiteitsbeoordeling onder de EU AI Act. Een menselijke toezichthouder neemt de uiteindelijke beslissing. Dit raakt direct aan artikel 43 van de AI Act (conformiteitsbeoordeling).
Rol 4 (Volledige automatisering) → Geautomatiseerde compliance-beslissingen. Een AI-systeem dat zelfstandig beslist of een AI-systeem aan de AI Act voldoet. Dit is voorlopig niet toegestaan onder de huidige wetgeving, maar de paper maakt duidelijk dat de technische mogelijkheden sneller ontwikkelen dan de juridische kaders.
De EU AI Act classificeert AI-systemen voor conformiteitsbeoordeling als hoog-risico. Een systeem als PAT, ingezet voor compliance-validatie, valt onder artikel 6(2) juncto Annex III, punt 1(a), systemen voor toegang tot essentiële diensten. De vraag is niet óf dit soort systemen komen, maar onder welke governance-rol ze worden toegelaten.
De ongemakkelijke waarheid over menselijke beoordeling
De paper citeert het NeurIPS 2021 consistentie-experiment: 10% van de submissions werd door twee onafhankelijke commissies beoordeeld. De inconsistentie in acceptatiebeslissingen was 23%. Bij willekeurige selectie zou dat 35% zijn. Menselijke beoordeling is dichter bij toeval dan bij perfectie.
Voor compliance-audits is dit geen academische discussie. Als twee BIO2-auditors het 23% van de tijd oneens zijn over dezelfde organisatie, is de baseline voor "aantoonbare compliance" fundamenteel onbetrouwbaar. Een AI-systeem dat consistenter scoort dan menselijke auditors is geen bedreiging voor het vak, het is een noodzakelijke correctie.
De drie risico's die de paper benoemt
De auteurs zijn eerlijk over de beperkingen:
-
Hallucinaties en datumfouten. PAT claimde soms dat een bewijs onjuist was door redeneerfouten of verouderde kennis. De synthese-agent met Google Search-grounding mitigeert dit deels, maar elimineert het niet.
-
Cognitieve complacency. Als reviewers te veel op AI vertrouwen, verliezen ze hun eigen beoordelingsvermogen. De paper noemt dit "deskilling of human reviewers", een risico dat één-op-één vertaalbaar is naar compliance-auditors.
-
Adversarial gaming. Auteurs kunnen papers optimaliseren om AI-reviewers te omzeilen, het equivalent van SEO voor wetenschappelijke validatie. De paper waarschuwt dat dit "papers superficially stronger" maakt zonder de onderliggende kwaliteit te verbeteren.
Conclusie
Google's PAT is geen toekomstmuziek. Het is een operationeel systeem dat 4.700 papers heeft gereviewd, fouten vond die maandenlang onopgemerkt bleven, en een taxonomie introduceert die direct toepasbaar is op AI-governance in de publieke sector.
De vraag voor compliance-professionals is niet of AI-systemen documenten gaan beoordelen. Die systemen bestaan al. De vraag is onder welke governance-rol we ze toelaten, en of we de juridische kaders op tijd hebben aangepast.
Bron: Jayaram, R., Tyler, D., Woodruff, D., Cortes, C., Matias, Y., Mirrokni, V., & Cohen-Addad, V. (2026). Towards Automating Scientific Review with Google's Paper Assistant Tool. arXiv:2606.28277.
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.