OpenCode vs Claude Code in productiecodebases: welke agent laat minder technical debt achter?
AI coding agents zijn volwassen genoeg geworden om echte codebases te lezen, bestanden te wijzigen, tests te draaien en pull requests voor te bereiden. Daarmee is de vraag veranderd. Niet langer: "welke tool schrijft sneller code?" Maar: "welke tool produceert software die veilig, onderhoudbaar, controleerbaar en betaalbaar blijft nadat de demo voorbij is?"
Een praktijkvergelijking tussen OpenCode en Claude Code concludeerde dat Claude Code sneller was, 9 minuten en 9 seconden voor een vierdelige taakset, terwijl OpenCode 16 minuten en 20 seconden nodig had. Tegelijk stelde dezelfde vergelijking dat OpenCode grondiger valideerde, meer tests genereerde, de volledige test suite draaide en minder verborgen regressierisico liet liggen. De kernobservatie is dus niet dat de ene tool objectief "beter" is. De kernobservatie is dat snelheid en technical debt verschillende optimalisatiefuncties zijn.
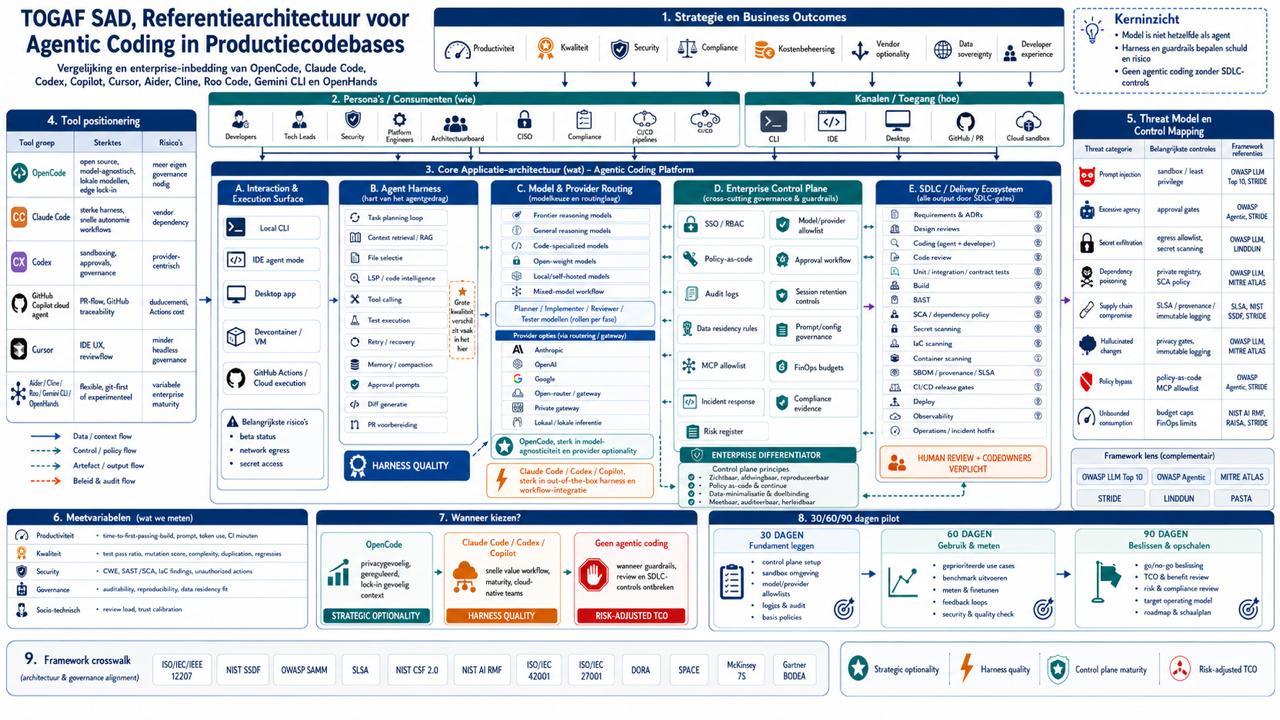
Onze aanvullende analyse bevestigt dat dit onderscheid te smal wordt zodra je naar enterprise software kijkt. In productiecodebases ontstaat technical debt niet alleen door slechte code. Het ontstaat ook door verkeerd gekozen modellen, zwakke agent-harnesses, te ruime tool-permissies, ontbrekende sandboxing, niet-goedgekeurde dependencies, gebrekkige auditlogs, CI/CD-gates die niet hard genoeg zijn en reviewers die te veel AI-diffs tegelijk moeten beoordelen. Het onderzoeksrapport splitst een AI coding agent daarom op in zes lagen: model, harness, execution surface, governance/control plane, teamproces en economisch model. Juist die ontkoppeling voorkomt misleidende conclusies.
De korte conclusie
OpenCode is niet automatisch beter dan Claude Code. Claude Code is niet automatisch gevaarlijker dan OpenCode. De betere keuze hangt af van de context.
Claude Code is sterker wanneer snelheid, out-of-the-box agentgedrag, diepe integratie, contextmanagement en ontwikkelaarsgemak belangrijker zijn dan modelsoevereiniteit. De officiële documentatie beschrijft Claude Code als een agentic coding tool die codebases leest, bestanden wijzigt, commando's uitvoert en integreert met terminal, IDE, desktop en browser. Het ondersteunt onder meer MCP, CLAUDE.md, hooks, skills, CI/CD-integraties en workflows waarbij agents taken plannen, uitvoeren en pull requests helpen voorbereiden.
OpenCode is sterker wanneer provider-keuze, lokale modellen, lage lock-in, privacy, auditbare configuratie en enterprise-soevereiniteit zwaarder wegen. OpenCode positioneert zichzelf als open-source AI coding agent voor terminal, IDE en desktop, met LSP-ondersteuning, meerdere sessies, 75+ modelproviders, lokale modellen en een privacyclaim dat code en contextdata niet door OpenCode worden opgeslagen. De enterprise-documentatie voegt daaraan toe dat OpenCode via centrale configuratie kan worden gekoppeld aan SSO en een interne AI gateway, en dat organisaties andere providers kunnen uitschakelen zodat verzoeken via goedgekeurde infrastructuur lopen.
Voor gereguleerde organisaties is de echte keuze niet "OpenCode of Claude Code". De echte keuze is: welk control plane voorkomt dat agent-output ongecontroleerd productie bereikt? Ons onderzoek komt daarom uit op één hoofdregel: geen agentic coding zonder sandboxing, policy-as-code, human review, SAST/SCA, secret scanning, dependency review, agent-logretentie, model/provider-allowlisting en FinOps-budgetcaps.
Wat de AlterSquare-case goed blootlegt
De AlterSquare-case is nuttig omdat hij een herkenbaar spanningsveld toont. Claude Code produceert sneller bruikbare output. OpenCode doet meer verificatiewerk en accepteert daardoor een langere doorlooptijd. In de case wordt gemeld dat Claude Code 73 tests genereerde en OpenCode 94 tests, en dat OpenCode breder valideerde door de volledige test suite te draaien. Tegelijk had OpenCode volgens de case last van noisier diffs, agressieve renames en soms ongewenste wijzigingen in documentatie of bestaande tests.
Dat patroon past bij wat wij in het onderzoek breder zien. Agents optimaliseren vaak naar "taak af" en "tests groen", niet automatisch naar architectuurconformiteit, lage cognitieve complexiteit, goede bounded contexts of minimale afhankelijkheden. Zonder executable architecture rules, fitness functions, CODEOWNERS en review-capaciteit wordt een AI-agent een versneller van zowel productie als schuld. Ons rapport noemt vier technische-schuldpatronen:
- Structurele schuld door coupling en duplicatie
- Dependency-schuld door ongewenste of gehallucineerde packages
- Testschuld door over-fit tests met lage mutation value
- Cognitieve schuld door review-overbelasting
Daarom is "Claude is sneller, OpenCode is veiliger" te simpel. Claude Code kan veilig zijn in een volwassen SDLC met harde gates. OpenCode kan riskant zijn als het lokaal draait met brede shellrechten, geen egresscontrole en geen centrale policy. De agent-harness en control plane bepalen in veel gevallen meer dan de merknaam.
De belangrijkste architectuurles: model is maar één laag
Veel vergelijkingen maken één fundamentele fout: ze vergelijken modelkwaliteit alsof dat de hele agentkwaliteit is. Dat is onjuist.
Een AI coding agent bestaat minimaal uit:
| Laag | Vraag die je moet stellen | Waarom dit technical debt beïnvloedt |
|---|---|---|
| Model | Claude, GPT, Gemini, Qwen, DeepSeek, lokaal of frontier? | Bepaalt redeneercapaciteit en codekwaliteit |
| Harness | Hoe plant, zoekt, wijzigt, test en herstelt de agent? | Bepaalt contextkwaliteit, retrygedrag en foutafhandeling |
| Execution surface | CLI, IDE, container, VM, GitHub Actions of cloud sandbox? | Bepaalt blast radius, datarouting en toegang tot secrets |
| Control plane | Welke policies, logs, approvals, SSO, RBAC en allowlists gelden? | Bepaalt of de tool enterprise-grade beheersbaar is |
| Teamproces | Hoe werken review, CI/CD, CODEOWNERS en release gates? | Bepaalt of slechte output wordt tegengehouden |
| Economisch model | Seat, tokens, AI credits, CI-minuten, reviewtijd, incidentkosten? | Bepaalt of productiviteit daadwerkelijk rendeert |
Ons onderzoek toetste specifiek de hypothese dat het grootste kwaliteitsverschil niet alleen uit het model komt, maar uit harness, permissions, contextstrategie, teststrategie en CI/CD-guardrails. Die hypothese is sterk ondersteund. Ook H7, dat alle agents zonder executable architecture rules en secure SDLC-gates latente technical debt kunnen verhogen, blijft plausibel.
Waar OpenCode wint
OpenCode wint vooral op optionaliteit. Het is open source, model-agnostisch en bruikbaar met verschillende providers, inclusief lokale modellen. De officiële documentatie beschrijft OpenCode als terminal-, desktop- en IDE-agent, met API-providerconfiguratie, AGENTS.md-initialisatie, plan mode en een /undo-mechanisme. Plan mode schakelt wijzigingen uit en laat de agent eerst een implementatievoorstel maken, in legacy- en gereguleerde repositories een belangrijk risicoreducerend patroon.
In een privacygevoelige of publieke-sectorcontext is OpenCode strategisch interessant omdat het kan worden gecombineerd met lokale of EU-resident modellen via een interne gateway. Ons onderzoeksrapport rangschikt OpenCode met lokaal model, bijvoorbeeld via Ollama en air-gapped uitvoering, als de hoogste soevereiniteitsoptie. De trade-off is expliciet: lokale modellen kunnen slechter presteren op complexe multi-file logica, en de organisatie wordt zelf verantwoordelijk voor patching, sandboxing en assurance.
OpenCode wint dus niet omdat het altijd betere code schrijft. OpenCode wint wanneer "Own Your AI" zwaarder weegt dan pure snelheid: eigen datarouting, eigen providerkeuze, eigen modelstrategie, eigen logging, eigen exitpad. Voor organisaties met CLOUD Act-zorgen, IP-gevoelige repositories of justitiële software kan dat doorslaggevend zijn.
Waar OpenCode verliest
OpenCode verliest wanneer een organisatie de integratietaks onderschat. Het open karakter betekent niet dat het automatisch enterprise-ready is. Integendeel: de control plane moet vaak zelf worden ontworpen.
De enterprise-documentatie laat zien dat OpenCode wel centrale configuratie, SSO-integratie en internal AI gateway-routing ondersteunt, maar juist die elementen moeten door de organisatie worden ingericht en afgedwongen. Ook is er een privacy-caveat: de optionele /share-functie stuurt conversatiegegevens naar een OpenCode-hosted share service, waarbij de documentatie adviseert dit tijdens trials uit te schakelen.
Daar zit de valkuil. Een team kan OpenCode lokaal installeren, een sterke frontier-API-key koppelen en de agent shelltoegang geven. Dan lijkt het alsof je privacy en controle hebt, terwijl je feitelijk een krachtige softwarewijzigende actor zonder centraal beleid hebt geïntroduceerd. In zo'n setup is OpenCode niet veiliger dan Claude Code. Het is alleen minder centraal bestuurd.
Waar Claude Code wint
Claude Code wint op geïntegreerde agentervaring. Het heeft een volwassen harness, werkt op meerdere surfaces, ondersteunt CLAUDE.md als projectinstructie, heeft MCP-integratie, hooks, memory, skills, CI/CD-integraties en workflowpatronen voor tests, merge conflicts, dependency updates en pull requests. Dat maakt het aantrekkelijk voor teams die snel willen van issue naar werkende branch.
De AlterSquare-case past in dit patroon: Claude Code levert sneller een eerste resultaat. Voor productteams, startups en SaaS-teams kan dat zeer waardevol zijn. De fout is alleen om die snelheid gelijk te stellen aan lagere TCO. Als de snellere agent architectuurmismatches, onnodige dependencies, subtiele runtime bugs of review-overload veroorzaakt, verschuift de kostenpost van coding time naar review time, debugging, rework en incident response.
Voor C-level besluitvorming is dit cruciaal: Claude Code is een productiviteitsversneller, maar geen SDLC-vervanger. Het werkt het best wanneer teams al duidelijke architectuurregels, testdiscipline, reviewpatronen en dependencybeleid hebben.
Codex en Copilot veranderen de vergelijking
OpenAI Codex en GitHub Copilot cloud agent verschuiven de discussie van lokale coding assistants naar cloud-gebaseerde software execution.
Codex documenteert sandboxmodi zoals read-only, workspace-write en danger-full-access, en approval policies zoals untrusted, on-request en never. De documentatie waarschuwt dat full access zonder sandbox en zonder approvals alleen in gecontroleerde omstandigheden gebruikt moet worden. Voor cloudtaken blokkeert Codex standaard internettoegang tijdens de agentfase, met configuratieopties voor domeinallowlists en HTTP-methods, omdat internettoegang prompt injection, code- of secret-exfiltratie, malware en licentierisico's kan vergroten.
Codex heeft daarnaast AGENTS.md-instructielagen, automatische approval reviews, governance- en observabilityfuncties, analytics, compliance exports en managed configuration voor enterprise admins. Dat maakt Codex interessant voor organisaties die controlled autonomy willen, maar minder voor organisaties die maximale provider-onafhankelijkheid of volledige lokale soevereiniteit eisen.
GitHub Copilot cloud agent is weer anders. De officiële GitHub-documentatie stelt dat Copilot cloud agent repositories kan onderzoeken, implementatieplannen kan maken, bugs kan fixen, features kan toevoegen, test coverage kan verbeteren, documentatie kan bijwerken en technische schuld kan adresseren. De agent werkt in een eigen ephemeral GitHub Actions-omgeving, kan code wijzigen, tests en linters draaien en branches of pull requests voorbereiden. GitHub biedt daarnaast PR-lifecycle-metrics, zoals aantal aangemaakte en gemergede PR's en mediane merge time.
Dat is sterk voor traceability, maar het verschuift risico naar GitHub identity, repositorypermissies, GitHub Actions-kosten, AI credits, branch policies, MCP-instellingen en cloud-execution. GitHub vermeldt expliciet dat Copilot cloud agent GitHub Actions-minuten en AI credits gebruikt, en dat code review op private repositories ook Actions-minuten kan verbruiken.
Security: de agent is een nieuwe supply-chainlaag
Agentic coding is geen gewone IDE-feature. Het is een nieuwe supply-chainlaag.
Ons onderzoek classificeert prompt/config-bestanden, AGENTS.md, CLAUDE.md, settings, hooks, MCP-servers, model-gateways, lokale inferentieservers, IDE-extensies, gegenereerde dependencies en agent-commits als governed assets. Die assets moeten versiebeheerd, gereviewd, gepind, gescand en van provenance voorzien worden.
OWASP's GenAI Top 10 noemt onder andere prompt injection, sensitive information disclosure, supply chain, improper output handling, excessive agency en unbounded consumption als relevante LLM-risico's. De OWASP Agentic AI Threats and Mitigations-publicatie benadrukt dat LLM-gebaseerde agents de schaal, capaciteiten en risico's van autonome systemen vergroten.
Dat vertaalt zich concreet naar coding agents:
| Risico | Hoe het ontstaat | Control |
|---|---|---|
| Prompt injection | Issue, README, dependency of webcontent bevat kwaadaardige instructies | Untrusted-content-isolatie, geen auto-exec, human gate |
| Excessive agency | Agent krijgt shell, file en netwerkrechten die breder zijn dan nodig | Deny-by-default, per-actie approval, sandbox |
| Dependency poisoning | Agent voegt gehallucineerd of malafide package toe | SCA, allowlist, lockfile-review, private registry |
| Secret exfiltration | Agent leest .env, tokens of CI-secrets en verstuurt ze via tool of netwerk | Secret scanning, egress allowlist, restricted network |
| Governance gap | Geen reproduceerbare prompt/tool-call/diff logs | Immutable audit logging, SIEM-integratie, retentiebeleid |
| FinOps runaway | Agent loops verbruiken tokens en CI-minuten zonder cap | Budget caps, usage alerts, modelroutering |
Het threat model uit het onderzoeksrapport koppelt deze risico's aan STRIDE, LINDDUN, PASTA, MITRE ATT&CK en MITRE ATLAS, met expliciete aandacht voor prompt injection, allowlist-poisoning, informatie-exfiltratie, RCE via hooks of MCP-config en niet-reproduceerbare agentacties.
Secure SDLC: de agent mag nooit de gate zijn
NIST SSDF stelt dat secure software development practices geïntegreerd moeten worden in SDLC-implementaties, juist omdat veel levenscyclusmodellen softwaresecurity niet diep genoeg adresseren. Voor agentic coding betekent dit dat de agent geen vervanging is voor secure SDLC, maar een actor binnen de secure SDLC.
Concreet betekent dit:
- Requirements: AI mag user stories formaliseren, maar domeinaannames moeten door product owner en architect worden gevalideerd
- Design: AI mag alternatieven voorstellen, maar architecture decision records en fitness functions blijven leidend
- Coding: AI mag implementeren, maar alleen binnen scoped permissions
- Testing: AI mag tests genereren, maar coverage is onvoldoende zonder branch coverage, mutation score en contracttests
- Review: AI-output vereist menselijke review, zeker bij auth, crypto, datalaag, dependencies en IaC
- Build en deploy: elke agent-commit doorloopt dezelfde SAST, SCA, secret scan, IaC scan, container scan en release gates als menselijke code
- Operations: incident-hotfixes door agents mogen alleen binnen vooraf goedgekeurde runbooks
Ons SDLC-crosswalk laat zien dat agentic tools vooral waarde toevoegen in implementatie, verificatie, testgeneratie en maintenance, maar risico verschuiven naar review, integratie, supply chain en operations.
Governance: AI RMF en ISO 42001 als lens
NIST AI RMF is bedoeld om risico's van AI voor individuen, organisaties en samenleving beter te managen en trustworthiness mee te nemen in ontwerp, ontwikkeling, gebruik en evaluatie van AI-systemen. Voor coding agents is dat praktisch te vertalen naar Govern, Map, Measure en Manage: definieer eigenaarschap, classificeer use cases, meet betrouwbaarheid en security, en manage risico's met harde controls.
Ons AI-governance-crosswalk koppelt dit aan ISO/IEC 42001 en ISO/IEC 27001. Een coding agent vereist een AI-risk-register, provider/model-allowlisting, auditbaarheid, reproduceerbaarheid en supplier-risk management. Het verschil tussen vendor-tools en OpenCode is governance-technisch fundamenteel: bij vendor-tools ligt een deel van het leveranciersrisico extern, bij OpenCode verschuift meer verantwoordelijkheid naar de eigen organisatie en open-source supply chain.
Beslismatrix: welke tool in welke context?
| Context | Beste keuze | Waarom | Niet doen |
|---|---|---|---|
| Regulated enterprise | Copilot cloud agent met sterk control plane, of OpenCode met eigen control plane | Copilot scoort sterk op GitHub-governance en PR-traceability, OpenCode op soevereiniteit | Tool kiezen zonder policy, audit en sandboxing |
| Privacygevoelige publieke sector | OpenCode met lokaal of EU-resident model via private gateway | Maximale dataroutingcontrole en lage lock-in | US-default cloud endpoint gebruiken zonder transfer-impactanalyse |
| Cloud-native SaaS scale-up | Claude Code, Codex of Copilot cloud agent | Snelheid, out-of-the-box agentkwaliteit, goede workflows | Metered kosten en review-overload onderschatten |
| IDE-gedreven productteam | Cursor of Claude Code | Sterke developer experience en context in IDE | IDE-tool behandelen als enterprise control plane |
| Open-source engineering team | OpenCode of Aider | Transparantie, BYOK, git-first, lage lock-in | Autonome merges zonder maintainer-review |
| Solo of klein team | Aider, OpenCode of Claude Code | Aider voor controle, OpenCode voor flexibiliteit, Claude Code voor zware taken | Volledige autonomie gebruiken zonder testdiscipline |
Deze matrix sluit aan op de MCDA uit het onderzoeksrapport: OpenCode scoort sterk op soevereiniteit, transparantie, cost en lock-in, maar verliest punten op governance wanneer de organisatie het control plane niet zelf bouwt. Claude Code en Codex scoren sterker op capaciteit en autonome workflow, maar brengen meer vendorafhankelijkheid mee.
Minimum guardrail baseline
Voor productiecodebases moet de baseline vóór adoptie klaarstaan, niet erna.
De minimale baseline is:
- Deny-by-default tool permissions
- Plan/read-only mode als startpunt voor gevoelige repositories
- Container of VM met least privilege
- Egress allowlist, geen vrije internettoegang
- Geen productie-secrets, geen echte PII in agentcontext
- MCP-allowlist, pinning en herkomstverificatie
- Config-as-code review voor AGENTS.md, CLAUDE.md, hooks en settings
- CODEOWNERS en verplichte human review op alle agent-PR's
- SAST, SCA, secret scanning, IaC scanning, container scanning en API-security tests
- OAuth2/OIDC token lifecycle tests voor auth-wijzigingen
- Immutable logging van prompts, approvals, tool calls, diffs en CI-resultaten
- Provider/model-allowlist met data-residency-eisen
- FinOps-budgetcaps op tokens, AI credits en CI-minuten
- Agent-CVE-monitoring voor hooks, MCP, IDE-extensies en gateways
Het onderzoeksrapport formuleert dit als knock-out: zonder control plane, sandboxing, egresscontrole, human-reviewcapaciteit en audit-reproduceerbaarheid geen agentic coding in gevoelige context.
Wat je moet meten in een pilot
Een serieuze pilot meet geen "regels code per dag". Dat is een vanity metric.
Meet minimaal:
| Domein | Metrieken |
|---|---|
| Productiviteit | Time-to-first-passing-build, elapsed time, prompts, interventies, tool calls, token usage, CI-minuten, reviewtijd |
| Kwaliteit | Test pass rate, branch coverage, mutation score, complexity, duplication, dependency additions, regressies, rollback-kans |
| Security | CWE-findings, SAST/SCA-resultaten, secret scans, IaC-misconfiguraties, OAuth2/OIDC-antipatterns, prompt injection events |
| Governance | Auditbaarheid, reproduceerbaarheid, policy enforcement, provider allowlisting, data residency, compliance evidence |
| Socio-technisch | Reviewer cognitive load, trust calibration, junior/senior impact, rework rate, psychological safety |
| Economie | API spend, AI credits, CI-minuten, review-overhead, incidentkosten, exitkosten |
De onderzoeksbrief adviseert een factorieel experiment waarbij tool, model, repositorytype, taaktype, governance-modus en execution mode onafhankelijk worden gevarieerd, met herhalingen per agent/model-combinatie en archivering van prompts, diffs, logs, tool calls, approvals, token usage en CI-resultaten.
30/60/90-dagen aanpak
Dag 1-30: bouw geen brede rollout. Bouw de veiligheidsfundering: control-plane-PoC, sandboximages, modelgateway, logging, SAST/SCA-gates, MCP-allowlist en twee toolingpaden. Eén soeverein pad, bijvoorbeeld OpenCode met lokaal of EU-resident model. Eén capaciteitsgericht pad, bijvoorbeeld Claude Code, Codex of Copilot cloud agent.
Dag 31-60: draai gecontroleerde taken op 2 of 3 representatieve repositories: bugfix, testgeneratie, dependency upgrade, security patch, OAuth2/OIDC-wijziging en documentatie. Meet niet alleen snelheid, maar ook defecten, reviewlast, agent-permissies, secret exposure, tokenkosten en regressies.
Dag 61-90: beslis. Niet op gevoel, maar op go/no-go criteria: minimaal 20 procent reductie in time-to-first-passing-build zonder stijging in change failure rate, geen ongeautoriseerde shell- of netwerkacties, 100 procent human review op agent-PR's, volledige audit trail en TCO binnen worst-case budget.
Eindadvies
Kies OpenCode wanneer data-soevereiniteit, lage lock-in, provideroptionaliteit, lokale modellen en exitstrategie belangrijker zijn dan maximale out-of-the-box snelheid. OpenCode is vooral sterk voor publieke sector, financiële instellingen, zorg, defensie, vitale infrastructuur en open-source teams. Maar alleen als je bereid bent het control plane, de sandboxing en de guardrails echt te bouwen.
Kies Claude Code wanneer autonome workflowkwaliteit, snelheid, contextmanagement en ontwikkelaarsgemak centraal staan, en wanneer vendorafhankelijkheid acceptabel is. Het is een sterke keuze voor teams met volwassen review, CI/CD, testdiscipline en duidelijke architectuurconventies.
Kies Codex wanneer je sandboxing, approvals, AGENTS.md, cloud en lokale execution, enterprise analytics en compliance-exports wilt combineren binnen het OpenAI-ecosysteem.
Kies GitHub Copilot cloud agent wanneer je GitHub-centrisch werkt en PR-traceability, branch workflows, GitHub Actions-integratie en usage metrics belangrijker zijn dan provideronafhankelijkheid.
Kies Cursor wanneer IDE-native developer experience en snelle interactie belangrijker zijn dan headless governance of platformonafhankelijkheid.
Kies Aider wanneer je git-first, human-in-the-loop en incrementeel gecontroleerd werk wilt, vooral in kleine teams.
Sta geen agentic coding toe wanneer je geen control plane, geen sandboxing, geen egresscontrole, geen human-reviewcapaciteit, geen SAST/SCA/secret scanning en geen audit-reproduceerbaarheid hebt. Dan versnelt de agent niet je softwareontwikkeling, maar je ongecontroleerde technical debt.
Bronnen: AlterSquare, OpenCode vs Claude Code, Claude Code Docs, OpenCode, OpenCode Enterprise, OpenCode Docs, Codex Sandboxing, Codex Internet Access, Codex AGENTS.md, Codex Approvals & Security, Codex Governance, Codex Managed Configuration, GitHub Copilot Cloud Agent, OWASP GenAI Top 10, OWASP Agentic AI Threats, NIST SSDF, NIST AI RMF
AI & Security Intelligence
Wekelijkse nieuwsbrief met AI updates, security alerts en compliance inzichten, direct in uw inbox.
Security & AI Operating Model
Advisory met executiekracht
Van BIO2 en NIS2 tot EU AI Act, embedded in uw operating model, niet als extern project. Maandelijks opzegbaar, met assessments als bewijsvoering.